特征融合论文《DeepFuse:A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs》
再接再厉。本文:https://arxiv.org/abs/1712.07384
ECCV2018那篇前景变换的我要是看懂代码了可以把代码简单的介绍下放上来,那个真的厉害。
Abstract
本文通过一种深度学习方法来融合静态的多曝光度的图片。现有的多曝光度图像融合技术使用手动计算的特征(hand-crafted features)来融合输入的图片序列。然而对于不同的输入情况,这种低级的手动计算特征并不稳健。除此之外,对于极端的曝光图片组合,这些特征的表现能力就更糟了。因此,我们需要一种方法可以对不同的输入情况都保持稳定的性能,并且可以在不引入伪影的时候处理极端的曝光情况。而深度学习方法对输入条件具有稳健性,并且在监督学习时表现惊人。然而,用深度学习方法进行多曝光度融合(MEF)的限制因素是:缺乏大量的训练数据以及作为监督的ground truth。为了解决上述问题,我们生成了一个含有多张曝光度的图片的组合(stacks)的数据集用于训练,并减少了对ground truth图片的需求,我们提出一种无监督的MEF深度学习框架,利用无参考质量度量(no-reference quality metric)来作为损失函数。我们提出的方法通过使用新型CNN架构来学习融合操作,而无需使用ground truth图像。该模型通过融合从不同图像中提取的低级特征,以生成没有伪影的,视觉上可以接受的结果。
本文通过进行广泛的定量和定性的评估,并表明所提出的技术优于现有的SOTA的方法。
一、简介
HDR可提供类似人眼可见的景色,从而避免过亮或者过暗的区域。常见生成HDR的方法就是多曝光度图片融合(MEF),通过将不同曝光度的LDR图片融合生成一张HDR的图片。本文便使用这一方法。许多MEF方法在融合曝光度较相似的LDR图片时效果明显(比如曝光度差异值为1)。因此,它需要通过更多不同曝光度的LDR图像以获得整个场景的动态范围,这样就需要更大的存储空间、更长的处理时间和更好的性能。原则上,长曝光时间的图片在较暗区域具有更好的颜色和结构信息;短曝光时间的图片在明亮的区域中会有更好的颜色和结构信息。虽然融合极端的曝光图像实际上更具有吸引力,但是它也非常困难,因为现有的方法无法保证均匀的亮度。
在本文我们把LDR堆栈看做我们算法的输入。
在本文中,我们提出一种基于数据驱动的方法来融合静态的多曝光度的图片。初始的层中包括一系列的卷积核来提取不同输入图片的低级特征。输入图像的低级特征被用来融合生成最后的结果。整个网络端到端训练,使用无参考图片的质量损失函数。
我们通过一个巨大的含有不同类别的图片堆栈(室内/室外、白天/夜晚、侧光/背光)来训练并测试我们的模型。此外,我们的模型不需要对不同的输入图像进行参数微调。通过广泛的实验评估,我们证明现有方法要由于其他SOTA的方法。
贡献点如下:
1、提出基于无监督的图片融合的方法来融合曝光度堆栈的图片。
2、提出新的基准数据集,可用于比较MEF的性能。
3、通过广泛的实验评估与和7个SOTA的算法进行对比学习。
二、相关工作
一般融合算法都是纯数学方法(基本在opencv库都能找到2333),而通过ELM(Extreme Learning Machine,极限学习机)可以将饱和度,曝光度,和对比度反馈到回归量中以估计每个像素的重要性。我们通过数据来学习原始像素中的表示,而不是使用手工计算出来的算子什么的。
三、基于CNN的特征融合算法
设 I I I是输入的LDR图片对,则 O ( I ) O(I) O(I)是融合操作后的结果, F W ( I ) F_W(I) FW(I)时前馈函数。由于输出结果 O ( I ) O(I) O(I)在MEF问题中是缺失的,因此我们无法使用列入MSE loss或者其他需要参考图片的loss函数。因此,我们把图片质量的度量MEF SSIM作为损失函数进行优化。MEF SSIM是基于SSIM框架提出来的。它测量的是结构完整性的损失,比如照度的一致性。
本实验结构如下所示。输入的曝光度堆栈被转换成 Y C b C r YCbCr YCbCr通道的数据。CNN被用于融合输入图片的照度通道——图像结构的细节在照度通道被显示出来,并且亮度通道中的亮度变化比色度通道要明显。将亮度通道通过3.3的方法与色度通道(Cb和Cr)组合。以下小节中介绍了网络架构,损失函数以及训练过程。
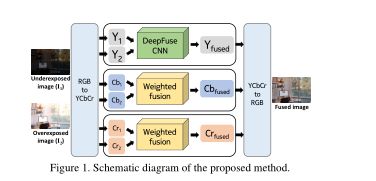
3.1 DeepFuse CNN
图像融合由于发生在像素域,CNN架构在很大程度上没有利用CNN的特征学习的能力。下图是图像融合的网络结构。
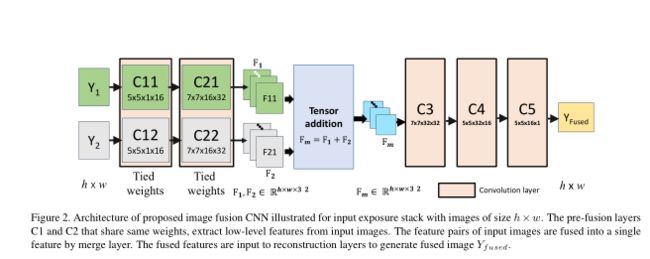
上图的网络结构包括以下三个层:特征提取层、特征融合层、重建图像层。
欠曝光图像 Y 1 Y_1 Y1和过曝光图像 Y 2 Y_2 Y2通过不同的通道输入,而特征提取层(C11与C21、C12与C22)通过5x5的卷积核来提取低层特征(比如边缘特征或角点特征),且C11与C12、C21与C22共用相同的权重信息。
这种结构优势有三:
1、网络可以从输入图片对中学习到相同的图片特征,因此可以通过简单的融合方法进行融合。意思是,添加图像1的第一特征图(F11)和图像2的第一特征图(F21),并且该处理也应用于剩余的特征图。此外,添加特征可以比其他组合特征选择更好的性能(下表)。在特征添加中,来自两个图像的类似特征类型被融合在一起。可选地,可以选择连接特征,通过这样做,网络必须计算合并它们的权重。在我们的实验中,我们观察到特征级联也可以通过增加训练迭代次数,增加C3之后的卷积核和层数来实现类似的结果。这是可以理解的,因为网络需要更多次迭代来计算出适当的融合权重。在本文的锁定权重设置中,我们正在强制网络学习对亮度变化不变的卷积核。通过可视化学习的卷积核观察到这一点(见下图)。在绑定权重的情况下,很少有高活化过滤器具有中心环绕感受野。这些卷积核已经学会从邻域中去除均值,从而有效地使特征亮度不变。


2、可学习的卷积核的数量减少了一半。
3、由于网络参数数量较少,因此收敛速度很快。
F m F_m Fm层用来通过对F11和F21的相加来进行特征融合,经过卷积层C3、C4、C5来从融合特征中重建最终的结果 Y f u s e d Y_{fused} Yfused。
3.1.1 MEF SSIM 损失函数
我们令 { y k } = { y k ∣ k = 1 , 2 } \{y_k\}=\{y_k|k=1,2\} {yk}={yk∣k=1,2}代表从像素点p处
y k = ∣ ∣ y k − μ y k ∣ ∣ ⋅ y k − μ y k ∣ ∣ y k − μ y k ∣ ∣ + μ y k = ∣ ∣ y k ~ ∣ ∣ ⋅ y k ~ ∣ ∣ y k ~ ∣ ∣ + μ y k = c k ⋅ s k + l k y_k=||y_k - \mu_{y_k}||\cdot\frac{y_k - \mu_{y_k}}{||y_k - \mu_{y_k}||}+\mu_{y_k}=||\tilde{y_k}||\cdot\frac{\tilde{y_k}}{||\tilde{y_k}||}+\mu_{y_k} =c_k\cdot s_k + l_k yk=∣∣yk−μyk∣∣⋅∣∣yk−μyk∣∣yk−μyk+μyk=∣∣yk~∣∣⋅∣∣yk~∣∣yk~+μyk=ck⋅sk+lk,其中 ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣是patch的l2范数, μ y k \mu_{y_k} μyk是指 y k y_k yk和 y k ~ \tilde{y_k} yk~的mean substracted patch。
3.2 训练过程
我们收集了25个可公开获得的曝光堆栈[。除此之外,我们还使用标准相机设置和三脚架,重新拍摄了50个具有不同场景特征的曝光堆栈。每个场景由2个低动态范围图像组成,二者具有±2 EV差异。输入图片的大小调整为1200×800。我们优先考虑室内和室外场景。从这些输入图片中,裁剪了大小为64×64的30000个patches用于训练。我们将学习率设置为 1 0 − 4 10^{-4} 10−4,并将网络训练100个迭代周期,每个迭代周期处理全部的patches。
3.3 测试过程
四、特征融合结果







五、结论
在本文中,我们提出了一种方法,可以有效地融合具有不同曝光度的一对图像,以产生无伪影和看起来顺眼的的输出。 DeepFuse是第一个无监督的深度学习方法,可以执行静态的MEF。本文提出的模型提取每个输入图像的低级特征图。
所有的输入图像的特征对通过合并层融合到单个特征图中。最后,融合的特征图被输入到重建层以获得最终的融合图像。我们使用各种设备拍摄的大量曝光堆栈来训练和测试我们的模型。此外,我们的模型不受参数微调的影响,适用于不同的输入条件。最后,本文进行了定量和定性评估,我们证明了所提出的体系结构是SOTA的。
总之,DF提供的优势如下:
1)更好的融合质量:即使对于极端曝光图像对也能产生更好的融合结果。
2)SSIM loss超过 l1 loss:之前有作者报告称l1损失优于SSIM损失函数。在他们的工作中,作者已经实现了SSIM的近似版本,并发现它与l1误差相比表现不佳。我们已经实施了精确的SSIM loss公式,并观察到SSIM损失函数的性能比MSE loss和l1 loss好得多。此外,我们已经表明,诸如MEF SSIM之类的复杂感知损失在缺乏ground truth的情况下可以成功地与CNN结合在一起。结果鼓励研究界检查其他基于感知能力的质量指标,并将其用作损失函数来训练神经网络。
3)对其他融合任务的概括性:所提出的融合本质上是通用的,并且也可以容易地适应其他融合问题。在我们目前的工作中,DF经过训练可以融合静态图像。对于未来的研究,我们的目标是推广DeepFuse来融合运动的图像。