LLVM教程( 三)-- LLVM IR
传统编译器的设计
<1> 最受欢迎的设计传统的静态编译器(像大多数C编译器)是三个阶段主要组件的前端设计,优化器和后端(下图)。前端解析代码,检查错误,并构建一个特定于语言的抽象语法树(AST)来表示输入代码。AST是优化选择转换为一种新的表示方法,优化器和后端上运行代码。

<2> 优化器负责做各种各样的转换来提高代码的运行时间,如消除冗余计算,通常是或多或少独立于语言和目标。后端(也称为代码生成器)然后映射到目标指令集的代码。除了要生成正确的代码,它还负责生成好的代码,利用不同寻常的特性支持的体系结构。常见的编译器后端部分包括指令选择、寄存器分配和指令调度。
这个模型同样适用于解释器和JIT编译器。Java虚拟机(JVM)也是此模型的一个实现,它使用Java字节码作为前端和优化器之间的接口。
<3> 这种经典设计的最重要的胜利来自编译器决定支持多种源语言或目标体系结构。如果编译器优化器使用一个共同的代码表示,那么可以为任何语言编写的一个前端,可以编译,和后端可以写任何目标都可以编译。如下图
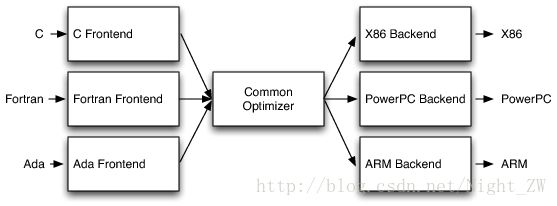
通过这个设计,移植编译器支持新的源语言(如 Algol 或者 BASIC)需要实现一个新的前端,但现有的优化和后端可以重用。如果这些部件不分离,实现一个新的源语言需要从头重新开始,所以支持N的目标需要N * M和M源语言编译器。
三端设计的另一个优点是编译器提供了更广泛的程序员集合,而不是只支持一种源语言和一个目标。 对于开源项目,这意味着有一个更大的潜在贡献者社区,这自然导致对编译器的更多改进和改进。 这就是为什么开放源代码编译器服务于许多社区(如GCC)倾向于生成更好的优化机器代码比较窄的编译器,如FreePASCAL。 专有编译器不是这样,其质量与项目的预算直接相关。 例如,英特尔ICC编译器以其生成的代码质量而广为人知,即使它为狭窄的人群提供服务。
最后一个三端设计的重大胜利,实现前端所需的技能是不依赖所需的优化和后端。分离这些更容易“前端”加强和维护他们的编译器的一部分。虽然这是一个社会问题,而不是一个技术问题,这就更至关重要了。在实践中,特别是对于开放源码项目,想贡献尽可能减少障碍。
虽然三端设计的好处在编译器教科书中是令人信服的和有据可查的,但实际上它几乎从未完全实现。查看开源语言实现(LLVM启动时),您会发现Perl,Python,Ruby和Java的实现没有共享代码。此外,类似Glasgow Haskell编译器(GHC)和FreeBASIC的项目可以重定向到多个不同的CPU,但是它们的实现非常特定于他们支持的一种源语言。还有各种专用编译器技术,用于实现用于图像处理的JIT编译器,正则表达式,显卡驱动程序和需要CPU密集型工作的其他子域。
也就是说,这个模型有三个主要的成功案例,第一个是Java和.NET虚拟机。这些系统提供了JIT编译器,运行时支持和非常清晰的字节码格式。这意味着任何可以编译为字节码格式的语言可以利用放入优化器和JIT以及运行时的支持。折衷是这些实现在运行时的选择上提供了很少的灵活性:它们有效地强制JIT编译,垃圾收集和使用非常特定的对象模型。当编译与此模型不匹配的语言(例如C(例如,使用LLJVM项目))时,这导致次优性能。
第二个成功案例可能是最不幸的,但也是最常用的重用编译器技术的方法:将输入源翻译为C代码(或其他语言),并通过现有的C编译器发送它。这允许重用优化器和代码生成器,提供良好的灵活性,对运行时的控制,并且前端实现者很容易理解,实现和维护。不幸的是,这样做阻碍了异常处理的有效实现,提供了差的调试经验,减慢编译,并且对于需要有保证的尾调用(或C不支持的其他特性)的语言可能有问题。
这个模型的最终成功实现是GCC 4。GCC支持许多前端和后端,并且具有活跃和广泛的贡献者团体。GCC有一个悠久的历史,作为一个C编译器支持多个目标与hacky支持其他几种语言。随着时间的推移,GCC社区正在慢慢演变一个更干净的设计。从GCC 4.4开始,它有一个新的优化器表示(称为“GIMPLE元组”),它比前面的表示更接近于前端表示。此外,它的Fortran和Ada前端使用一个干净的AST。
虽然非常成功,但这三种方法对它们可以用于什么有很大的局限性,因为它们被设计为单片应用。作为一个例子,将GCC嵌入其他应用程序,使用GCC作为运行时/ JIT编译器,或者提取和重用GCC的片段而不牵引大部分编译器是不现实可能的。想要使用GCC的C ++前端进行文档生成,代码索引,重构和静态分析工具的人不得不使用GCC作为一个整体应用程序,以XML形式发布有趣的信息,或者编写插件以将外部代码注入GCC进程。
有多个原因导致GCC不能作为库重用,包括猖獗地使用全局变量,弱强制的不变式,设计不良的数据结构,扩展的代码库,以及使用宏来阻止代码库编译支持更多每次一个前端/目标对。然而,最难解决的问题是源于其早期设计和年代的固有的建筑问题。具体来说,GCC遭受分层问题和漏洞抽象:后端走前端AST生成调试信息,前端生成后端数据结构,整个编译器依赖于命令行接口设置的全局数据结构。
LLVM IR
<1> 有了历史背景和上下文,让我们来看看LLVM:它的设计的最重要的方面是LLVM中间表示(IR),它是用来在编译器中表示代码的形式。LLVM IR设计为托管在编译器的优化器部分中找到的中级分析和转换。它被设计成具有许多具体的目标,包括支持轻量级运行时优化,跨功能/过程间优化,整个程序分析和积极的重组转换等。然而,它的最重要的方面是它本身被定义为一种具有明确定义的语义的第一类语言。下图有个例子.ll文件。
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
LLVM 对应的C代码。
unsigned add1(unsigned a, unsigned b) {
return a+b;
}
// Perhaps not the most efficient way to add two numbers.
unsigned add2(unsigned a, unsigned b) {
if (a == 0) return b;
return add2(a-1, b+1);
}
从这个例子可以看出,LLVM IR是一个低级RISC类的虚拟指令集。像真正的RISC指令集一样,它支持简单指令的线性序列,如加,减,比较和分支。这些指令采用三种地址形式,这意味着它们需要一些输入并在不同的寄存器中产生结果。LLVM IR支持标签,通常看起来像一个奇怪的汇编语言形式。
与大多数RISC指令集不同,LLVM是使用简单类型系统强制类型化的(例如,i32是一个32位整数,i32** 是指向32位整数的指针),并且机器的一些细节被抽象掉。例如,调用约定是通过抽象call和ret说明和明确的参数。与机器代码的另一个显着区别是,LLVM IR不使用一组固定的命名寄存器,它使用以%字符命名的无限临时集。
除了被实现为语言之外,LLVM IR实际上以三种同构形式定义:上面的文本格式,通过优化本身检查和修改的内存数据结构,以及高效和密集的磁盘上二进制“位码”格式。该项目LLVM还提供工具,以磁盘格式从文本到二进制转换:llvm-as文本汇编.ll文件转换成 .bc包含bitcode粘性物质从中文件,并llvm-dis把一个 .bc文件到一个.ll文件中。
LLVM的三端设计实现
在基于LLVM的编译器中,前端负责解析,验证和诊断输入代码中的错误,然后将解析的代码转换为LLVM IR(通常但不总是通过构建AST,然后将AST转换为LLVM IR)。该IR可选地通过一系列分析和优化过程来馈送,改进代码,然后发送到代码生成器中以产生本地机器代码,如图所示。这是一个非常直接的三端设计实现,但这个简单的描述掩盖了LLVM架构从LLVM IR派生的一些功能和灵活性。
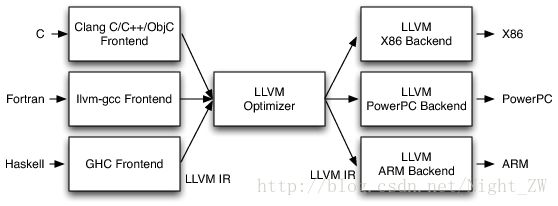
特别地,LLVM IR是优化器的唯一接口。 这个就意味着你需要知道为LLVM编写一个前端是什么LLVM IR,它是如何工作,以及它期望的不变性。 由于LLVM IR具有一级文本形式,因此构建一个将LLVM IR作为文本输出的前端是可能的,也是合理的,然后使用Unix管道通过您选择的优化器序列和代码生成器发送它。
这可能是令人惊讶的,但这实际上是LLVM的一个非常新颖的属性和其成功在广泛的不同应用程序的主要原因之一。 即使是广泛成功和相对良好架构的GCC编译器也没有这个属性:它的GIMPLE中级表示不是一个自包含的表示。 作为一个简单的例子,当GCC代码生成器发出DWARF调试信息时,它返回并遍历源级“树”形式。 GIMPLE本身使用代码中的操作的“元组”表示,但(至少如GCC 4.5)仍然表示操作数作为回到源级树形式的引用。
参考资料:
http://www.aosabook.org/en/llvm.html
http://llvm.org/docs/LangRef.html