爬虫从入门到放弃——WebMagic使用简单的爬虫(2)
补充一下引用的包:
<dependencies>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.3version>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.3version>
dependency>
dependencies>
WebMagic基本代码
现在我们想爬取博客园的作者,我们进入博客园的网站:www.cnblogs.com 。
如下图所示:
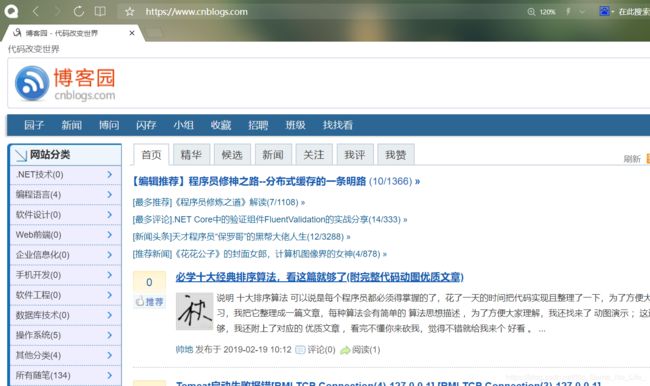
现在我们想爬取第一页里所有文章里的作者名,我们该怎么做呢?
Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();
首先使用上面这句,初始化PageProcessor。
然后是重写public void process(Page page)方法,具体应该怎么写呢?
(1)判断抓取的网址是不是符合规范。
我们随意点进去一个博客,可以看到网址是这样的:

如果足够了解,我们知道,他的规律是https://www.cnblogs.com/+用户id+/p/+8位数字。
由正则表达式,我们可以得出:https://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{8}.html
好了,因为我们要在该页面抓取作者名,所以符合该页面地址规范的我们就抓,不符合的,说明就是像首页这样的布局,我们可以将首页带有的URL加入进待抓取的队列中。如何判断呢?
if(!page.getUrl().regex("https://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{8}.html").match())
(2)如果不符合规范,加入新网页:
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"post_list\"]/div/div[@class='post_item_body']/h3/a/@href").all());
这里使用xpath的语法,//*[@id=...]表示所有满足id=xxx的标签。很容易的,我们可以在h3中发现能够加入的链接地址。
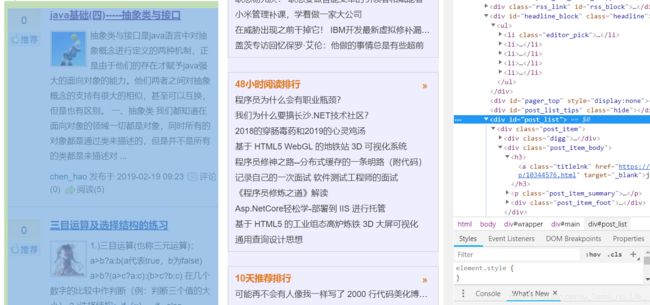
(3)如何符合规范,读取作者名称。
可以看到网页中有两个地方会出现作者名,但是公告栏那一处是通过js读取的,关于ajax/js,我还没看到,所以这里不做处理。我们使用左上角的那个。
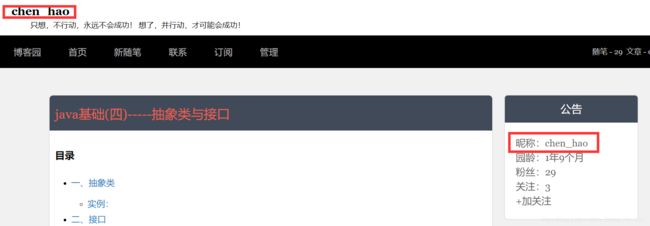
根据审查页面元素和查看页面源码:

我们看到,“chen_hao”这一词出现在标签为,id为Header1_HeaderTitle的地方。
所以,我们使用//*[@id="Header1_HeaderTitle"]/text()即可读取到作者名。
最后的代码如下:
/**
* Author: LeesangHyuk
* Date: 2019/2/19 9:21
* Description:
*/
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class MyProcessor implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count =0;
public Site getSite() {
return site;
}
public void process(Page page) {
//判断链接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
if(!page.getUrl().regex("https://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{8}.html").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"post_list\"]/div/div[@class='post_item_body']/h3/a/@href").all());
}else{
//获取页面需要的内容
System.out.println("抓取的内容:"+
page.getHtml().xpath("//*[@id=\"Header1_HeaderTitle\"]/text()").get()
);
count ++;
}
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
}
这段代码有两个缺点,一是只读取了一页的内容,二是没能读取ajax/js的内容(我读出来是null)。鉴于我只看了一章的WebMagic,所以第二点的内容我之后再补充。
如何读取下一页呢?
通过一行代码即可
if(!page.getUrl().regex("https://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{8}.html").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"post_list\"]/div/div[@class='post_item_body']/h3/a/@href").all());
//读取下一页
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"paging_block\"]/div/a/@href").all()
);
}

下面是CSDN的爬虫,也是爬取作者名:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* Author: LeesangHyuk
* Date: 2019/2/19 10:45
* Description:
*/
public class CSDNProcessor implements PageProcessor{
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count =0;
public Site getSite() {
return site;
}
public void process(Page page) {
//判断链接是否符合https://blog.csdn.net/用户名id/article/details/8位数字
if(!page.getUrl().regex("https://blog.csdn.net/[a-z 0-9 -]+/article/details/[0-9]{8}").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@class=\"title\"]/h2/a/@href").all());
}else{
//获取页面需要的内容
System.out.println("抓取的内容:"+
page.getHtml().xpath("//*[@id=\"uid\"]/text()").get()
);
count ++;
}
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new CSDNProcessor()).addUrl("https://www.csdn.net/").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
}
不过好像有某种反爬虫机制,把我的地址给屏蔽了,希望后续的学习能够完善。
完善结果:
package csdn;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.PriorityScheduler;
import java.util.ArrayList;
import java.util.List;
/**
* Author: LeesangHyuk
* Date: 2019/2/21 14:21
* Description:
*/
public class CSDNProcessor implements PageProcessor {
private Site site;
private static int count=0;
// public static final String URL_LIST = "";
public static final String URL_POST = "https://blog.csdn.net/No_Game_No_Life_/article/details/[0-9]{8}";
public void process(Page page) {
if (page.getUrl().regex(URL_POST).match()) {
page.putField("title",page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1/text()"));
if (page.getResultItems().get("title") == null) {
page.setSkip(true);
}else{
count++;
}
page.putField("url",page.getUrl().toString());
page.putField("time",page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[2]/div[1]/span[1]/text()"));
}else{
page.addTargetRequests(page.getHtml().links().regex(URL_POST).all(), 1000);
page.addTargetRequests(getListLink(), 1);
}
}
public Site getSite() {
if (site==null) {
site=Site.me().setRetryTimes(3).setSleepTime(500).setTimeOut(10000)
.addHeader("referer","https://blog.csdn.net/No_Game_No_Life_")
.setCharset("utf-8").setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3633.400 QQBrowser/10.4.3232.400");
}
return site;
}
public List<String> getListLink(){
List<String> links=new ArrayList<String>();
for (int i = 2; i < 13; i++) {
links.add("https://blog.csdn.net/No_Game_No_Life_/article/list/"+i);
}
return links;
}
public static void main(String[] args) {
while (true) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new CSDNProcessor())
.setScheduler(new PriorityScheduler())
.addPipeline(new ConsolePipeline())
.addUrl("https://blog.csdn.net/No_Game_No_Life_/")
.thread(2).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了" + count + "条记录");
try {
Thread.sleep(20000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
发现一个惊天大秘密!
原来可以直接复制XPath:
