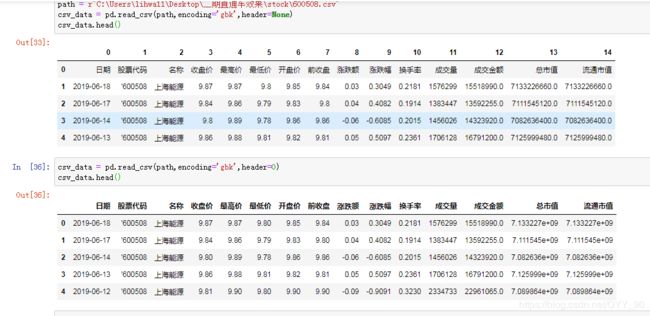
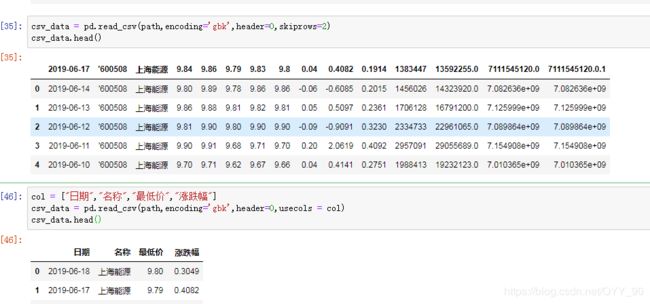
python:to_csv&read_csv常用参数的解析
df.read(file,sep,shkiprows,usecols,nrows,chunksize...)
sep=',' # 以 “,” 作为数据的分隔符
shkiprows= 10 # 跳过前十行
usecols=['column1', 'column2', 'column3'] # 读取指定列
nrows = 10 # 只取前10行
chunksize=1000 # 分块大小来读取文件(每次读取多少行),不一次性把文件数据读入内存中,而是分多次
parse_dates = ['col_name'] # 指定某行读取为日期格式
index_col = ['col_1','col_2'] # 读取指定的几列
error_bad_lines = False # 当某行数据有问题时,不报错,直接跳过,处理脏数据时使用
na_values = 'NULL' # 将NULL识别为空值
dt.to_csv('file.csv',sep='?')#使用?分隔需要保存的数据,如果不写,默认是,
dt.to_csv('file.csv',na_rep='NA') #确实值保存为NA,如果不写,默认是空
dt.to_csv('file.csv',float_format='%.2f') #保留两位小数
dt.to_csv('file.csv',columns=['name']) #保存索引列和name列
dt.to_csv('file.csv',header=0) #不保存列名
dt.to_csv('file.csv',index=0) #不保存行索引