走进机器阅读理解的世界,飞桨开源升级版 BiDAF模型解读
导读:飞桨(PaddlePaddle)致力于让深度学习技术的创新与应用更简单。在重要的机器阅读领域,基于DuReader数据集,飞桨升级并开源了一个经典的阅读理解模型 —— BiDAF,相较于DuReader原始论文中的基线,在效果上有了大幅提升,验证集上的ROUGE-L指标由原来的39.29提升至47.68,测试集上的ROUGE-L指标由原来的45.90提升至54.66。
1. 机器阅读理解概述
阅读理解,相信中国学生都不陌生,不管是语文考试还是英语考试,阅读理解都是非常常规的考试内容。一般形式就是给出一篇文章,然后针对这些文章提出一些问题,问题的类型包括选择题、填空题或者分析题,学生通过回答这些问题来证明自己理解了文章所要传达的主旨内容。
而机器阅读理解,就是指机器自主来完成以上过程。教会机器学会阅读理解是自然语言处理(NLP)中的核心任务之一,也是机器真正智能化的体现。
在机器阅读理解任务中,我们会给定一个问题(Q)以及一个或多个段落(P)/文档(D),然后利用机器在给定的段落中寻找正确答案(A),即Q + P or D => A。
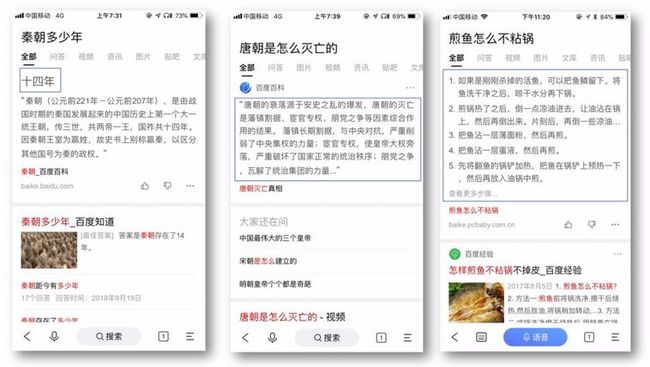
下图是机器阅读理解的一个示例:

作为自然语言处理领域的前沿课题,机器阅读理解近年来一直受到学术界和工业界的广泛关注。
从学术角度看,机器阅读理解任务可以用来衡量机器理解人类语言的综合水平。NLP的很多传统任务,例如词性标注、命名实体识别、句法分析、语义角色标注、指代消解等都试图让机器从词法、语义等角度理解人类语言。机器在某一个任务上的效果,仅在一定程度上反应了机器在该方面对语言的理解水平。而在阅读理解任务中,机器需要在词法、语义等多方面有较高的理解水平,才能够正确回答相关问题。因此可以通过让机器阅读文本回答相关问题,来评价机器理解人类语言的综合水平。这与人类参加的语言考试中用阅读理解题目考察答题者对语言和内容的理解水平是类似的。
从应用角度看,机器阅读理解也是构建问答系统和对话系统的关键技术之一。近些年来,各种智能设备,如智能手机、智能音响等迅速普及。这些设备具有小屏化或无屏化的特点,因此用户亟需能够精准满足其信息需求的问答技术。传统的检索式问答技术,主要关注段落排序,仍难以完成精准问答的“最后一公里”,即段落中的精准答案定位。而近两年机器阅读理解技术所取得的进展,为精准答案定位提供了有力的技术支持。在百度的搜索问答和小度音箱中,都使用到了机器阅读理解技术,为数亿用户提供了精准问答。
2. BiDAF模型原理介绍
BiDAF是一个经典的机器阅读理解模型,包含多阶段的层次化过程,通过使用双向注意流机制,在不进行早期总结的情况下,仍可以在不同的粒度级别上,获得一个查询感知的上下文表示。
原始论文名称:Bidirectional AttentionFlow for Machine Comprehension
BiDAF模型的结构图如下:
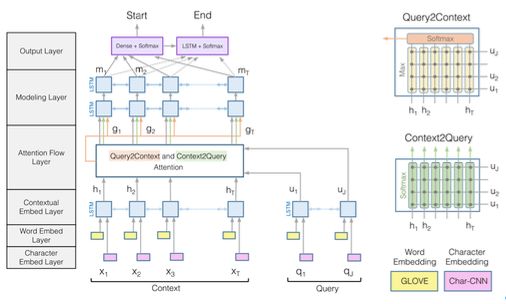
BiDAF模型是一个分阶段的多层过程,主要由6层网络组成。
(1)字符嵌入层:
用字符级CNNs将每个字映射到向量空间。
(2)字嵌入层:
利用预训练的词嵌入模型,将每个字映射到向量空间。
(3)上下文嵌入层:
利用周围单词的上下文线索来细化单词的嵌入。这前三层同时应用于问句和原文。
(4)注意力流层:
将问句向量和原文向量进行耦合,并为原文中每个词生成一个问句相关的特征向量集合。
(5)建模层:
使用RNN以扫描整个原文。
(6)输出层:
输出问句对应的回答。
飞桨此次开源的BiDAF模型,是基于DuReader阅读理解数据集来训练的。
数据集地址:
https://ai.baidu.com/broad/subordinate?dataset=dureader
DuReader是一个大规模、面向真实应用、由人类生成的中文阅读理解数据集。DuReader聚焦于真实世界中的不限定领域的问答任务。相较于其他阅读理解数据集,DuReader的优势包括:
问题来自于真实的搜索日志
文章内容来自于真实网页
答案由人类生成
面向真实应用场景
标注更加丰富细致
更多关于DuReader数据集的详细信息可在DuReader官网找到。
飞桨团队在实现并升级BiDAF的过程中,去掉了char级别的embedding,在预测层中使用了pointer network,并且参考了R-NET中的一些网络结构,从而达到了比原始论文中更好的模型效果。
在DuReader2.0验证集、测试集的表现如下:
Model |
Dev ROUGE-L |
Test ROUGE-L |
BiDAF (原始论文基线) |
39.29 |
45.90 |
飞桨实现的BiDAF |
47.68 |
54.66 |
3. 飞桨BiDAF快速上手
3.1.基础环境
(1)安装飞桨
关于飞桨框架的安装教程,可以参考飞桨官方网站。
官网地址:https://www.paddlepaddle.org.cn
(2)安装代码
克隆工具集代码库到本地
git clone https://github.com/PaddlePaddle/models.gitcd models/PaddleNLP/reading_comprehension/cd models/PaddleNLP/reading_comprehension/
(3)下载第三方依赖
在本基线系统中,我们采用了Bleu以及Rouge-L指标作为模型的评估标准。这些指标的计算脚本可以通过运行以下命令进行下载
cd utils && bash download_thirdparty.sh3.2.数据准备
为了方便开发者进行测试,我们提供了预处理(分词、计算answer span等)过后的DuReader 2.0数据集、训练好的模型参数以及词表。通过运行以下命令即可下载:
cd data && bash download.sh此外,用户还可以利用paddlehub的方式下载模型参数,例如:
hub download dureader_machine_reading-bidaf3.3.段落抽取
我们采用了一种新的段落抽取策略以提升模型在DuReader2.0数据集上的表现(策略内容详见src/UPDATES.md)。该段落抽取策略可通过运行以下命令执行:
sh run.sh --para_extraction请注意,在运行上面命令之前,需要先下载预处理之后的DuReader 2.0数据 (见”下载数据集以及模型“章节)。段落抽取得到的结果会存放在 data/extracted/文件夹中。
3.4.模型评估
通过运行以下命令,开发者可以利用上面提供的模型在DuReader 2.0验证集进行评估:
sh run.sh --evaluate--load_dir ../data/saved_model--devset ../data/extracted/devset/zhidao.dev.json ../data/extracted/devset/search.dev.json
在评估结束后,程序会自动计算ROUGE-L指标并显示最终结果。
3.5.模型预测
通过运行以下命令,开发者可以利用上面提供的模型在DuReader 2.0测试集进行预测:
sh run.sh --predict--load_dir ../data/saved_model--testset ../data/extracted/testset/zhidao.test.json ../data/extracted/testset/search.test.json
模型预测的答案将被保存在data/results文件夹中。
3.6.训练自己的模型
如果开发者希望重新训练模型参数,可以参考本章节步骤。
在模型训练开始之前,需要先运行以下命令来生成词表以及创建一些必要的文件夹,用于存放模型参数等:
sh run.sh --prepare--trainset ../data/extracted/trainset/zhidao.train.json ../data/extracted/trainset/search.train.json--devset ../data/extracted/devset/zhidao.dev.json ../data/extracted/devset/search.dev.json--testset ../data/extracted/testset/zhidao.test.json ../data/extracted/testset/search.test.json
建立好的词表会存放在data/vocab文件夹中。
然后运行下面的命令,即可开始训练:
sh run.sh --train--pass_num 5--trainset ../data/extracted/trainset/zhidao.train.json ../data/extracted/trainset/search.train.json --devset ../data/extracted/devset/zhidao.dev.json ../data/extracted/devset/search.dev.json
以上参数配置会对模型进行5轮训练,并在每轮结束后利用验证集自动进行评估。每轮过后,程序会自动将模型参数保存到data/models文件夹当中,并以该轮的ID命名。
如果开发者需要改变模型训练时的超参数,例如初始学习率、隐层维度等,可以通过指定以下参数来实现:
sh run.sh --train--pass_num 5--learning_rate 0.00001--hidden_size 100--trainset ../data/extracted/trainset/zhidao.train.json ../data/extracted/trainset/search.train.json--devset ../data/extracted/devset/zhidao.dev.json ../data/extracted/devset/search.dev.json
更多参数配置可在paddle/args.py中找到。
3.7.提交测试集结果
当开发者通过调参、修改模型结构得到更好的结果后,可以将DuReader 2.0测试集的预测结果提交到DuReader 官网来进行评测。在提交结果之前,请确保以下几点:
训练已经全部结束;
通过训练日志在data/models文件夹中选择在验证集表现最佳的模型;
通过上面章节描述的方法在测试集上进行预测,并得到完整结果。
赶快自己动手尝试下吧!
想与更多的深度学习开发者交流,请加入飞桨官方QQ群:432676488。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
项目地址:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleNLP/reading_comprehension
