inceptionv3迁移学习 训练+测试
迁移学习在实际应用中的意义非常大,它可以将之前已学过的知识(模型参数)迁移到一项新的任务上,使学习效率大大的提高。我们知道,要训练一个复杂的深度学习模型,成本是十分巨大的。而迁移学习可以大大的降低我们的训练成本,在短时间内就能达到很好的效果。
迁移学习的四种应用场景:
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。我们使用公开大模型作为我们的特征提取器。比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。在这个例子中,我们需要做的就是把最终softmax layer的输出从1000个类别改为2个类别。当然为了达到更好的效果,我们可能会在最后加几层全链接,这个根据实际情况而定。
场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
下面是通过对inceptionv3网络进行迁移学习来识别5种花的例子:
1.下载谷歌已训练好的inceptionv3网络 https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
2.数据集下载 http://download.tensorflow.org/example_images/flower_photos.tgz
3.替换最后一个softmax层,在最后这一层全连接层之前的网络层称之为瓶颈层bottleneck。将新的图像通过训练好的卷积神经网络直到瓶颈层的过程,可以看成是对图像进行特征提取的过程。在训练好的inceptionV3模型中,因为将瓶颈层的输出再通过一个单层的全连接层神经网络可以很好地区分1000种类别的图像,所以有理由认为瓶颈层输出的节点向量可以被作为任何图像的一个更加精简且表达能力更强的特征向量。
4.训练自己的数据,并保存pb模型文件
5.恢复模型进行预测
训练并保存模型代码:
# -*- coding: utf-8 -*-
"""
卷积神经网络 Inception-v3模型 迁移学习
并保存pb模型文件
"""
import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
from tensorflow.python.framework import graph_util
# inception-v3 模型瓶颈层的节点个数
BOTTLENECK_TENSOR_SIZE = 2048
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
# 图像输入张量所对应的名称
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
# 下载的谷歌训练好的inception-v3模型文件目录
MODEL_DIR = 'model'
# 下载的谷歌训练好的inception-v3模型文件名
MODEL_FILE = 'tensorflow_inception_graph.pb'
# 保存训练数据通过瓶颈层后提取的特征向量
CACHE_DIR = 'tmp/bottleneck'
# 图片数据的文件夹
INPUT_DATA = 'flower_data/'
# 验证的数据百分比
VALIDATION_PERCENTAGE = 10
# 测试的数据百分比
TEST_PERCENTACE = 10
# 定义神经网路的设置
LEARNING_RATE = 0.1
STEPS = 5000
BATCH = 100
# 这个函数把数据集分成训练,验证,测试三部分
def create_image_lists(testing_percentage, validation_percentage):
"""
这个函数把数据集分成训练,验证,测试三部分
:param testing_percentage:测试的数据百分比 10
:param validation_percentage:验证的数据百分比 10
:return:
"""
result = {}
# 获取目录下所有子目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# ['/path/to/flower_data', '/path/to/flower_data\\daisy', '/path/to/flower_data\\dandelion',
# '/path/to/flower_data\\roses', '/path/to/flower_data\\sunflowers', '/path/to/flower_data\\tulips']
# 数组中的第一个目录是当前目录,这里设置标记,不予处理
is_root_dir = True
for sub_dir in sub_dirs: # 遍历目录数组,每次处理一种
if is_root_dir:
is_root_dir = False
continue
# 获取当前目录下所有的有效图片文件
extensions = ['jpg', 'jepg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir) # 返回路径名路径的基本名称,如:daisy|dandelion|roses|sunflowers|tulips
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension) # 将多个路径组合后返回
file_list.extend(glob.glob(file_glob)) # glob.glob返回所有匹配的文件路径列表,extend往列表中追加另一个列表
if not file_list: continue
# 通过目录名获取类别名称
label_name = dir_name.lower() # 返回其小写
# 初始化当前类别的训练数据集、测试数据集、验证数据集
training_images = []
testing_images = []
validation_images = []
for file_name in file_list: # 遍历此类图片的每张图片的路径
base_name = os.path.basename(file_name) # 路径的基本名称也就是图片的名称,如:102841525_bd6628ae3c.jpg
# 随机讲数据分到训练数据集、测试集和验证集
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images
}
return result
# 这个函数通过类别名称、所属数据集和图片编号获取一张图片的地址
def get_image_path(image_lists, image_dir, label_name, index, category):
"""
:param image_lists:所有图片信息
:param image_dir:根目录 ( 图片特征向量根目录 CACHE_DIR | 图片原始路径根目录 INPUT_DATA )
:param label_name:类别的名称( daisy|dandelion|roses|sunflowers|tulips )
:param index:编号
:param category:所属的数据集( training|testing|validation )
:return: 一张图片的地址
"""
# 获取给定类别的图片集合
label_lists = image_lists[label_name]
# 获取这种类别的图片中,特定的数据集(base_name的一维数组)
category_list = label_lists[category]
mod_index = index % len(category_list) # 图片的编号%此数据集中图片数量
# 获取图片文件名
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
# 拼接地址
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path
# 图片的特征向量的文件地址
def get_bottleneck_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt' # CACHE_DIR 特征向量的根地址
# 计算特征向量
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
"""
:param sess:
:param image_data:图片内容
:param image_data_tensor:
:param bottleneck_tensor:
:return:
"""
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values
# 获取一张图片对应的特征向量的路径
def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
"""
:param sess:
:param image_lists:
:param label_name:类别名
:param index:图片编号
:param category:
:param jpeg_data_tensor:
:param bottleneck_tensor:
:return:
"""
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir) # 到类别的文件夹
if not os.path.exists(sub_dir_path): os.makedirs(sub_dir_path)
bottleneck_path = get_bottleneck_path(image_lists, label_name, index, category) # 获取图片特征向量的路径
if not os.path.exists(bottleneck_path): # 如果不存在
# 获取图片原始路径
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
# 获取图片内容
image_data = gfile.FastGFile(image_path, 'rb').read()
# 计算图片特征向量
bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)
# 将特征向量存储到文件
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# 读取保存的特征向量文件
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
# 字符串转float数组
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
return bottleneck_values
# 随机获取一个batch的图片作为训练数据(特征向量,类别)
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category, jpeg_data_tensor,
bottleneck_tensor):
"""
:param sess:
:param n_classes: 类别数量
:param image_lists:
:param how_many: 一个batch的数量
:param category: 所属的数据集
:param jpeg_data_tensor:
:param bottleneck_tensor:
:return: 特征向量列表,类别列表
"""
bottlenecks = []
ground_truths = []
for _ in range(how_many):
# 随机一个类别和图片编号加入当前的训练数据
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index] # 随机图片的类别名
image_index = random.randrange(65536) # 随机图片的编号
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category, jpeg_data_tensor,
bottleneck_tensor) # 计算此图片的特征向量
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
# 获取全部的测试数据
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys()) # ['dandelion', 'daisy', 'sunflowers', 'roses', 'tulips']
for label_index, label_name in enumerate(label_name_list): # 枚举每个类别,如:0 sunflowers
category = 'testing'
for index, unused_base_name in enumerate(image_lists[label_name][category]): # 枚举此类别中的测试数据集中的每张图片
'''''
print(index, unused_base_name)
0 10386503264_e05387e1f7_m.jpg
1 1419608016_707b887337_n.jpg
2 14244410747_22691ece4a_n.jpg
...
105 9467543719_c4800becbb_m.jpg
106 9595857626_979c45e5bf_n.jpg
107 9922116524_ab4a2533fe_n.jpg
'''
bottleneck = get_or_create_bottleneck(
sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
def create_inception_graph():
with tf.Graph().as_default() as graph:
model_filename = os.path.join(
MODEL_DIR, MODEL_FILE)
with gfile.FastGFile(model_filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, name='', return_elements=[
BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])
return graph, bottleneck_tensor, jpeg_data_tensor
def add_final_training_ops(class_count, bottleneck_tensor):
# 输入
bottleneck_input = tf.placeholder_with_default(bottleneck_tensor, [None, BOTTLENECK_TENSOR_SIZE],
name='BottleneckInputPlaceholder')
ground_truth_input = tf.placeholder(tf.float32, [None, class_count], name='GroundTruthInput')
# 全连接层
with tf.name_scope('output'):
weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, class_count], stddev=0.001))
biases = tf.Variable(tf.zeros([class_count]))
logits = tf.matmul(bottleneck_input, weights) + biases
final_tensor = tf.nn.softmax(logits, name='prob')
# 损失
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
# 正确率
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return (train_step, evaluation_step, cross_entropy_mean, bottleneck_input, ground_truth_input)
def main():
image_lists = create_image_lists(TEST_PERCENTACE, VALIDATION_PERCENTAGE)
n_classes = len(image_lists.keys())
print('n_classes:', n_classes)
graph, bottleneck_tensor, jpeg_data_tensor = create_inception_graph()
print(bottleneck_tensor.graph is tf.get_default_graph())
with tf.Session(graph=graph) as sess:
train_step, evaluation_step, cross_entropy_mean, bottleneck_input, ground_truth_input = add_final_training_ops(
n_classes, bottleneck_tensor)
# 初始化参数
init = tf.global_variables_initializer()
sess.run(init)
for i in range(STEPS):
# 每次获取一个batch的训练数据
train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(sess, n_classes, image_lists, BATCH,
'training', jpeg_data_tensor,
bottleneck_tensor)
# 训练
sess.run(train_step,
feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
# 验证
if i % 100 == 0 or i + 1 == STEPS:
validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(sess, n_classes,
image_lists, BATCH,
'validation',
jpeg_data_tensor,
bottleneck_tensor)
validation_accuracy = sess.run(evaluation_step, feed_dict={bottleneck_input: validation_bottlenecks,
ground_truth_input: validation_ground_truth})
print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%' % (
i, BATCH, validation_accuracy * 100))
# 测试
test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor,
bottleneck_tensor)
test_accuracy = sess.run(evaluation_step,
feed_dict={bottleneck_input: test_bottlenecks, ground_truth_input: test_ground_truth})
print('Final test accuracy = %.1f%%' % (test_accuracy * 100))
#保存合并后模型的参数和计算图
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ["output/prob"])
with tf.gfile.FastGFile("newpb/nn.pb", mode='wb') as f:
f.write(constant_graph.SerializeToString())
main()
恢复模型并进行预测代码:
import glob
import os.path
import tensorflow as tf
import numpy as np
import cv2
"""
"""
def predict():
strings = ['daisy', 'dandelion', 'rose', 'sunflowers', 'tulips']
def id_to_string(node_id):
return strings[node_id]
with tf.gfile.FastGFile('newpb/nn.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('output/prob:0')
#
for root, dirs, files in os.walk('flowers_test'):
for file in files:
#
image_data = tf.gfile.FastGFile(os.path.join(root, file), 'rb').read()
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data}) #
predictions = np.squeeze(predictions) #
#
image_path = os.path.join(root, file)
print(image_path)
#
top_k = predictions.argsort()[::-1]
print(top_k)
for node_id in top_k:
#
human_string = id_to_string(node_id)
#
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))
print()
img = cv2.imread(image_path)
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
predict()运行训练程序时注意检查一下有没有修改成自己的路径,我自己的测试图片放在flowers_test文件夹下。
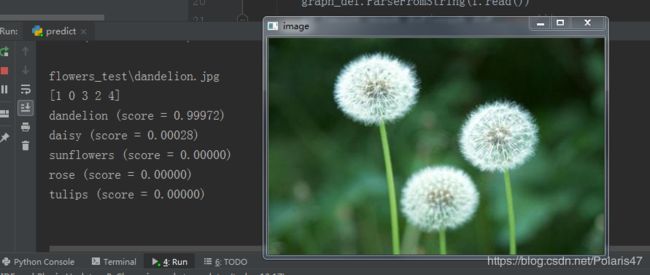
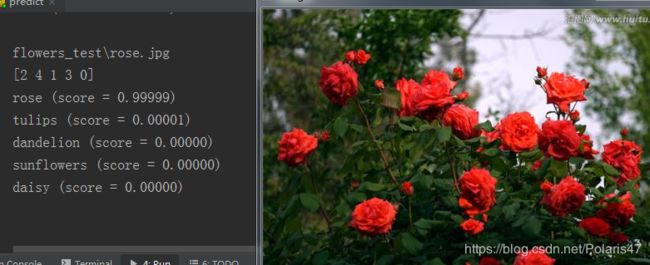
运行结果: