欢迎关注笔者的公众号:【阿飞的博客】,首发都在这里!!!
这篇文章深入讲解InnoDB如何在逻辑上构造它的索引,并深入了解索引上的叶子节点的结构,然后几乎精确的计算索引树高度,深度好文,你一定不要错过。
一些术语
在深入了解索引以及叶子节点结构之前,我们先提前了解一些专业术语:B+Tree, ROOT, leaf和level,为了接下来更好的掌握InnoDB的索引。
- B+Tree
InnoDB用B+Tree构造它的索引(MyISAM也是一样的),当数据不能完全加载到内存中,需要从磁盘读取时,这时候B+Tree结构是非常有效的。它能保证访问任何数据的效率,查找索引过程中每次读取事实上就是一次IO,整个查找过程主要与索引树的高度有关。
- ROOT
每一个索引树都是从一个ROOT页开始,它的位置是固定的,永远被保存在InnoDB的数据字典中,ROOT页就是访问索引树的起点。索引树可能只有一个ROOT页,也可能有成百上千个页,这时候就是多级树,并且树的高度超过1。
- leaf
索引树的每个页都与叶子(leaf)页或者非叶子(non-leaf)页相关联。叶子页包含实际的行数据,非叶子页只包含指向非叶子页或者叶子页的指针。索引树是平衡的,B+Tree中的B是Balance的意思,而不是Binary。所以,索引树的所有分支有相同的深度。
- level
InnoDB索引树中每个页都有一个level值,其中:叶子页level=0,从叶子页往ROOT页,level值递增。ROOT页的level值加1就是树的深度(例如叶子页level=0;ROOT页level=1,那么索引树高度为2)。那些既不是叶子页,也不是ROOT页的页被称为内部(internal)页。
- page directory
即页目录(就跟树目录的原理差不多),它是一个大小为2个字节的指向4~8个记录的指针,它的作用是为了改进遍历一个索引页的性能。如果没有页目录,即使二分法查询,如果是拥有大概1000个记录的非叶子页,最多需要近10次的比较(2^10≈1000),并且索引页有多少级,这样的比较要成倍增加。
有了页目录后,我们就可以先用二分法从页目录中找到目标KEY所在的目录,然后通过页目录这个指针,找到目标KEY所在的只有4~8个记录的数组中。我们假设每个页目录平均指向5个记录,那么,1000个记录的非叶子页,需要200个页目录,二分法查找只需要8次(2^8=256),整个遍历过程少了20%的开销。
叶子&非叶子页
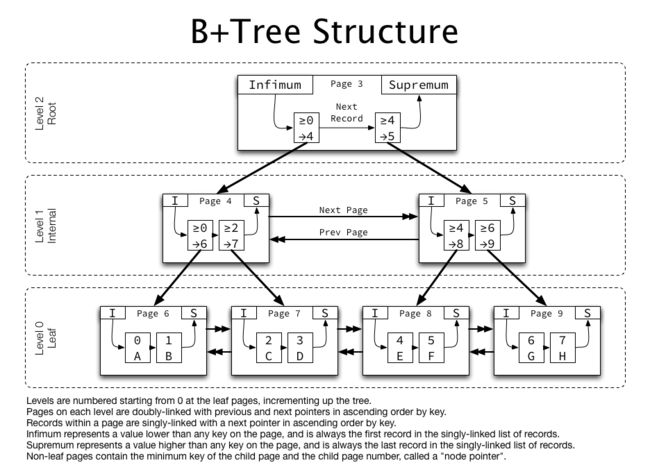
对于叶子页和非叶子页,每个记录都包含一个指向下一个记录的指针。它存储了下一个记录的offset值(相对当前页的offset)。一个索引页以下确界(Infimum)开始,以KEY递增的方式连接所有记录,并以上确界(Supremum)结束。
- 叶子页
叶子页包含了其他非KEY的值,这些值也是每个记录中的部分数据(假设表有3列:id, name, age。那么id就是KEY,name和age都是非KEY。KEY和非KEY组成完整的记录):

如上图所示,这个叶子页有两个Record:一个Record的Key是0,并且还有非Key的值A;另一个Record的Key是1,并且还有非Key的值B。
- 非叶子页
非叶子页的结构与叶子页的结构大同小异,不同的地方是,非叶子页中保存是子页的页号。而且并不保存一个明确的KEY,而是保存一个Min Key,这个字段表示的是他们指向的子页的最小KEY:

如上图所示,这个非叶子页有两个Record:其中一个Record的Min Key为0,并且Page为4,表示它指向的子页的页号为4,并且它的最小记录为0;我们根据这个视图可以得出结论,这个索引树对应的表的id最小值肯定是0(因为这个页的页号是3,page 3表示ROOT页)。
- 相同等级的索引页
许多索引远不止一个页,那么就会有很多级(level)。所以,许多页会被以升序和降序的方式用双向链表串联起来,每个页都包含了指向前一页和下一页的指针。需要注意的是,只有level相同的页才会被串联起来,例如叶子页相互串联成双向链表,level 1 的页相互串联成双向链表。如下图所示,是level=0即叶子页相互串联成的双向链表:

剖析一个索引页
接下来让我们深入研究一个B+Tree索引页的内部,完全掌握一个默认16k大小的索引页里面都保存了一些什么数据,索引页的细节图如下所示:

我们可以通过前文《innodb_ruby:窥探InnoDB的神器》提供的SQL和存储过程稍微修改,然后创建一张名为tk_afei的InnoDB表,并插入1000条数据,然后借助innodb_ruby命令的一些模式可以验证上面的B+TREE索引页视图。
space-index-pages-summary模式能够得到整个索引树的概要信息,结果如下所示:
[afei@afei mysql]# innodb_space -s ibdata1 -T afei/tk_afei space-index-pages-summary
page index level data free records
3 54 1 39 16213 3
4 54 0 7462 8648 287
5 54 0 14924 1044 574
6 54 0 3614 12572 139
7 0 0 0 16384 0
这个结果可以得出一些结论:
- 页号为3的是ROOT页(因为它的level是1),并且ROOT页只有3个记录;
- 页号为4、5和6的是叶子节点(level为0),每个叶子页都有上百个记录,叶子页总计有287+574+139=1000个记录;
- 页号7总计16384即16k空间还没有任何数据。
通过page-records模式查看页号为3的索引页内容,由结果可知,只有3个记录,且指针分别指向#4,#5,#6(#N表示页号N):
[afei@afei mysql]# innodb_space -s ibdata1 -T afei/tk_afei -p 3 page-records
Record 125: (id=1) → #4
Record 138: (id=288) → #5
Record 151: (id=862) → #6
俗话说的好:一图胜前言。在讲解一个索引页的内容时,我们通过命令:innodb_space -s ibdata1 -T afei/tk_afei -p 6 page-illustrate查看页号为6的索引页的完整可视化试图(其中offset在896~15936之间的空间省略,否则图片太长):

从这张图中,我们能清晰的看到一个16k的索引页到底包含了哪些内容。从这张图得到的一些信息如下(色彩对应即可,比如绿色就知道是Index Header):
- 第一行offset为[0, 63]中的茶色部分就是FIL Header,即这个索引页的头指针,并且占用38字节。
- 第一行与第二行的绿色就是Index Header,占用36字节。
- 接下来就是File Segment Header,占用20个字节。
- 然后就是下确界和上确界,都是占用13个字节。
- 中间最多的就是Record Header和Record Data即索引页里的指针和数据(主键)。
- 最后两行总计34个小方块就是Page Directory。
- 最后一行的最后一小部分就是FIL Trailer,也就是当前索引页的尾指针,占用8个指针。
计算索引树高度
我在之前的文章中初略的讲解了如何计算索引树高度,方法比较粗糙,不够严谨。今天,我们根据刚才对索引页的深入剖析,以及索引页结构视图,以更加精确的方式计算索引树高度。
我们知道一个索引树是由叶子页和非叶子页组成。所以,计算索引树高度的关键就是如果计算一个16k大小的叶子页和非叶子上能保存多少个记录。
通过上面的page-illustrate模式结果,我们能够知道每个索引页都有一些固定的数据:
- 38个字节的FIL Header
- 36个字节的Index Header
- 20个字节的File Segment Header
- 13个字节的Infimum
- 13个字节的Supremum
- 8个字节的FIL Trailer
总计128个字节。
剩下的空间全部用来保存Record Header,Record Data和Page Directory。之前我们已经得知ROOT页信息如下:
page index level data free records
3 54 1 39 16213 3
所以一个16k大小的索引页内容为:128(固定数据占用字节数)+ 39(数据) + 4(Page Directory) + 16213(Free空间,即还没填满) = 16384(每个索引页的大小)。
到了这里,要计算一个叶子页和非叶子页能保存多少记录的关键就剩下如何计算每个记录的大小了。
- 叶子页
对于任意一个叶子叶子,其记录尺寸计算公式如下:
Record Size = 5(header)+ 4(int类型的PK)+ 6(TRX_ID)+ 7(ROLL_PTR)+ N(Non-key fields)
这个公式可以通过如下方式进行验证:
-- 创建一张表
CREATE TABLE tk3_afei (
id INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
num int not null,
age int not null
) ENGINE=InnoDB;
-- 用存储过程插入1004条数据后,再插入1条数据,对比前后,我们发现page为6的free值从8446减少到了8416(records数从256增加到257):
[root@mysql]# innodb_space -s ibdata1 -T afei/tk3_afei space-index-pages-summary
page index level data free records
3 58 1 39 16213 3
4 58 0 7470 8658 249
5 58 0 14970 1036 499
6 58 0 7680 8446 256
7 0 0 0 16384 0
[root@mysql]# innodb_space -s ibdata1 -T afei/tk3_afei space-index-pages-summary
page index level data free records
3 58 1 39 16213 3
4 58 0 7470 8658 249
5 58 0 14970 1036 499
6 58 0 7710 8416 257
7 0 0 0 16384 0
也就是说一条记录(1005, 1005, 26)占用了8446-8416=30个字节。这30个字节计算公式如下:
5(header)+ 4(int类型的PK)+ 6(TRX_ID)+ 7(ROLL_PTR)+ 4*2(2个int类型的Non-key fields)= 30 个字节。
所以,叶子页能保存的记录数B计算方式如下:
- 先计算每个记录大小:5+4+6+7+8=30个字节;
- 再计算每个叶子页能保存的记录数B:那么30*B+2*B/5+128=16384(2*B/5表示每5个记录需要一个页目录,每个页目录大小是2个字节),所以B≈535;
- 非叶子页
非叶子页由于不需要保存非KEY字段的值,所以计算方式略有不同。对于任意一个非叶子节点,其能保存的记录数B计算方式如下:
- 先计算每个记录大小(Record Data):4+4=8字节(需要保存指向子叶的页号,以及Min Key两个int类型字段的值);
- 每个指针的大小(Record Header)为8;
- 计算每个非叶子页能保存的记录数B:那么(8+8)*B+2*B/5+128=16384,所以B≈991;
- 索引树高度
计算索引树高度时,我们做如下假设:
表拥有16个列,其中主键是int类型,并且还有5个int类型和10个varchar类型的其他列,平均每个varchar保存10个字节长度的字符串。那么这张表的每个记录大小是:5+4+6+7+(4*5+10*10)=142≈150
另外,通过上面的计算可知,一个非叶子页可以保存1000左右的记录,而一个叶子页只可以保存150个左右记录(与我们的表保存的记录有很大的关系)。我们假设有一个完美的B+Tree索引,每一个页都填满了,那么索引树的高度和表能容纳的最大数据量关系如下(其中:k表示千,m表示百万,b表示十亿):
| height | 非叶子页 | 叶子页 | 记录数 |
|---|---|---|---|
| 1 | 0 | 1(ROOT) | 150 |
| 2 | 1(ROOT) | 1k | 150k(150*1k) |
| 3 | 1(ROOT)+1k | 1m | 150m(150*1m) |
| 4 | 1(ROOT)+1k+1k*1k | 1b | 150b(150*1b) |
所以,主键要设计的尽可能的小。如果用一个大的主键可能引起B+Tree低效,因为无论如何,主键值会被保存在非叶子页中,主键越大,非叶子页中的主键占用的空间就越大,这就意味着,非叶子页存储的指针更小,从而导致索引树越高。
一个完整的索引树
最后,我们能得出一个多级索引树的大概示意图如下图所示,正如前面所描述的,所有level相同的页通过双向链表相互串联,在每个页中,记录按照递增的方式单向链表串联,非叶子页包含的是指针(包含了指向它的子叶的页号和Min Key),而不是非KEY的行数据: