现场丨2017中国计算机大会(CNCC2017)之李飞飞演讲:ImageNet之后,计算机视觉何去何从?

今天,我就想和大家来分享实验室的思考和一些比较新的工作。
由于我在国外生活的时间比较长,我可能说英文比说中文要好一点儿。所以,我就要用英文来做这个演讲,偶尔会插一些中文词。谢谢大家。
今天我的主题演讲主要是关于计算机视觉。
要聊这个话题,首先,让我们先从5.4亿年前说起。
那个时候,地球基本上没有陆地,全是海洋。为数不多的低等的生物就生活在海洋里,当有食物漂过来时,这些生物就赶紧将其吃掉以维持生命。
自那起的1000万年间,动物的种类和数量迎来了大爆发 。生物的种类从少有的几种,迅速增长为几千种之多。这在历史上被称为“寒武纪大爆发”。那么,是什么引起了这场大爆发呢?
几年前,澳大利亚的科学家 Andrew Parker找到了答案。
大约在5.4亿年前,有的动物开始进化出了简陋的眼睛。对于一个个体来说,这没有什么大不了,不就是多了一个小孔,这个小孔能接收光线,仅此而已。但这对于整个地球而言,可就是一件改变整个生命历程的大事。
就因为有眼睛,动物们看得见食物了。他们可以从被动获取食物,变成主动寻找食物。他们学会了隐藏,学会了伺机而动,也学会了快速出击。
于是,动物的存活率大大提升,而大幅提升的存活率又大大促进了生物的进化。可以这么说,正是因为视觉的诞生,才有了寒武纪大爆发。
从那以后,动物们开始进化出各种各样的视觉系统。实际上,视觉已经变成了动物大脑中最为重要的感知神经系统。因为发达的视觉系统,让他们的生命不断延续,种类不断增多。
将目光收回到人类。
视觉让人们看到这个世界,看懂这个世界,让人们有能力不停地交流、合作、互动。
在人类的大脑中,视觉神经系统非常重要。甚至可以这么说,视觉是人类智能的基石。
正因为如此,我对于计算机视觉这项工作才尤为着迷。这可是人工智能的关键环节啊。可是,计算机视觉应该从哪些地方模仿人类的视觉呢?哪些才是能影响到计算机视觉的里程碑式的事件呢?而且人类对目标识别到底有多擅长?
早在60年代和70年代,认知心理学家以及视觉科学家就指出,人类拥有的视觉系统无与伦比。
有一个来自麻省理工大学的著名实验是这样的,我现在要向大家连续播放多帧画面,每帧的显示时间仅100微秒。其中,只有一帧的画面里有人。你们能找出来吗?可以举手示意我一下。
这可不是一个IQ测试,大家尽可以放轻松。
实验的结果是:大多数的人都可以找到这一帧,看出在这一帧中,有个人立在那里。这太让人惊叹了!
实验之前,你不会知道这个人长什么样,是男人还是女人,这个人穿着什么衣服,是什么姿态。但是,你的视觉系统却能在如此短的时间内快速地找到这个信息。
1996年,神经学家Simon J. Thorpe及团队发布了一项研究,通过脑电波来观察人脑对于图像识别的速度。他发现,仅需 100 微秒,大脑就会发出一道区分信号,对画面中的物体是否为动物做出判断。对于复杂目标对象的处理能力,构成了人类视觉系统的基础。
这个实验对于计算机视觉的影响巨大。回望20年前,我们能清楚地看到,正是对目标物体的识别的研究促进了整个计算机视觉的大发展。
最近,大家都很了解与ImageNet有关的先进的图像识别。其实,从2010年到2017年,ImageNet挑战了传统的图像分类。这八年间,我们的社区取得了令人瞩目的成绩,将错误率从 28% 降低到了2.3%。在攻克图像识别的难题的征途上,计算机视觉的研究者们共同努力,取得了非凡的成绩。当然,解决图像识别难题的重要里程碑之一是在 2012 年,这是 CNN 第一次在利用大数据进行监督学习领域展现出令人印象深刻的能力。从这一点出发,我们开始进入深度学习革命的新纪元。
但是,我今天的主题并不在ImageNet。固然,ImageNet对人工智能有重要的贡献,但是我们必须往前看,看看有什么技术可以超越ImageNet。图像是视觉体验的基本要素。但是,在图像之上,还有一些需要探索的东西。
视觉关系理解
比如,有两张图片,当我遮挡住其余部分,只留出一两个要素时,你会觉得它们很相似。但是,当你看到整张图片时, 你会发现,它们呈现了两个完全不同的场景。
这说明图像理解非常关键。它超越了ImageNet,和其所代表的图像识别。
那么,视觉关系的预测或者理解难在哪?
当我们给计算机一张图片,我们需要算法通过识别关键对象来定位对象的位置以及预测对象之间的关系,这就是视觉关系预测的任务。
过去有一些针对视觉关系的深度研究。但是大部分此方向的研究都局限于一些特定的或者普遍的关系。而现在,由于计算机在数据和深度学习能力上的提高,我们可以对视觉关系进行更深层次的研究。
我们使用了一个卷积神经网络视觉表示的联结,以及一个估计交互式视觉组件之间关系的语言模块。
我不会深入这个模型的细节,只是简单地介绍其结果。我们的模型去年发表在ECCV,能够估计特殊关系,对比关系,非对称关系,动词和动作关系,以及位置关系。因此,我们能够估算出场景的丰富关系,不只是简单的感知对象。
相比于目前最先进的技术,我们对基本测试有很好的性能表现。我们不仅能够进行关系预测,实际上还能对未知的关系进行理解(zero-shot understanding)。例如,在我们的训练数据集中,我们能发现坐在椅子上的人或者站在地面上的消防队员。但在测试时,我们有人坐在消防栓上等类似的关系的图片,而实际训练时很难收集大量的训练实例。但我们的模型可以做到对未知东西的学习及理解。这里还有一个例子,马戴帽子,实际上另一个关系人骑马或人戴帽子更为常见。自从我们去年发表在ECCV的工作以来,关系预测的工作已经雨后春笋般发展起来。有些工作的效果已经超过了我们一年前的结果,但我个人很高兴看到社区不再局限于ImageNet提供的内容,而去思考更丰富的场景理解。
但为了做到这一点,我们必须用基准数据集来支持社区。我们已经看到了ImageNet对物体识别做出了特别大的贡献,但作为一个数据集,这是一个有局限的数据集。它只有一个信息位,就是场景中的主要对象。ImageNet之后,社区的同事提出了许多关于数据集的有趣想法。Harry(沈向洋)已经提到的微软的COCO框架可以识别场景中的更多对象,以及用一个简短的句子进行描述。但是,还有更多的内容需要解决,特别是物体间的关系,问答,及针对图像场景的问答。
自动生成场景图
三年前,我们开始收集有关的数据集,目的为了深入场景内容。我们真正关心的是关系,我们将视觉世界视为相互关联的场景图。
场景图是表示对象和关系的基本方式。
通过三年的努力,我们做出了一些通用的数据集。这个通用的视觉数据集包含10w多张图像和对其进行的420万个图像描述,180万对问答,140万标注好的对象,150万个关系和170万个属性。因此,这是一个非常丰富的数据集,其目的是推动我们超越名词,开展关系理解,纹理推理等研究。
我们已经展示了关系表示,还有什么其他事情可以做,或者视觉数据集是用来做什么的?
我要告诉你另一个称为“场景检索”的项目。
这实际上是计算机视觉中的一个老问题,很多人都研究过。这是一个相对已经成熟的产品,有点像谷歌图像搜索。
当我在Google输入“男人穿套装”或者“可爱的狗狗”这个词后,系统会返回给你漂亮的照片。你可以看看结果,非常有说服力。
但我用更复杂的句子,比如“男人穿西装,抱着可爱的狗”呢?效果就很难说了。
我们希望对我们得到的东西有更多的控制,更丰富的场景检索。然后,场景检索模型就没法实现了,因为它是基于对象的,它并不真正地理解关系。
这里有一个例子。我想获得一个男人坐在长凳上的场景,如果我只是基于对象搜索它,我会得到分离的对象或者错误的关系。也许我可以添加一些属性,但它会丢失对象和其他东西。但是当我添加关系和对象时,我可以立刻得到更加有意义和精确的场景。这就是场景检索的理念。
我们之前的一个研究是如何表示非常复杂的检索请求,就像这个描述:一个满头灰发的老女人戴着她的眼镜,穿着一个敞怀的的黄夹克,等等等。一旦我们有这样的场景图,它就变得更容易,成为了一个图匹配问题。此前我们有在专有设备上训练过它。完全可以想象,我们最近几年可以用深度学习技术将其发扬光大。需要特别注意的是,场景图是描述复杂场景中丰富内容的基础。
下面是有关卧室的另一个例子,以及如何使用场景图来检索它。这一切都是可行的,它用新的方式来表示复杂的意义和连接的场景。
但是,你们至少应该先问我个问题,她是怎么得到这些场景图的?这看起来不容易。
事实上,这在实际应用环境中是完全不可想象的。当我去百度搜索,或者Bing搜索,或者谷歌搜索询问一个图像时,你如何构造场景图呢?所以我们真正需要做的是自动生成场景图。
关于自动生成场景图的论文我们发表在 2017 CVPR 上。
我们使用了一个自动场景图生成模型来验证传递进行的查询消息,感兴趣可以查看我们的论文。相比于其他基准模型(baseline),此模型更接近于真实的场景图处理。
我们很兴奋地看到这个通用的视觉数据集向世界传达了场景图表示的概念,我们正在使用这个基准并且鼓励社区去审视有关关系条件,场景检索生成等问题。但这些只是越过ImageNet的一些早期问题,它仍然相对简单。他们只是有关场景的。当你睁开眼睛时,你首先看到的是物体、关系。但视觉智能或人工智能比我们要强,那么,超越早期对像素的感知外还有什么呢?
给大家展示一下 10 年前我在研究生时期做的一个实验,这个实验是关于人类认知的。我让参与测试的实验对象坐在电脑屏幕的前方,然后让他们看一张闪烁地非常快的图片,然后这张图片很快就会被壁纸遮挡起来,此处的遮挡是为了控制图片在屏幕上停留的时长,停留的时间其实非常短。一小时我给他们 10 美元,然后他们在看过图片之后,需要写出自己所能记得的关于这张图片的所有描述。
可以看到,这里的场景切换非常之快,其中最短的图片展示时间只有 27 毫秒,也就是 1/45 秒,而图片停留的最常时间也只有 500 毫秒,也就是 0.5 秒。让人惊奇的是,我们发现人类能够将图片场景描述的非常详细。只需要 500 毫秒,人类就能够识别出非常多的内容,比如任务、动作、穿着、情绪、事件、社会角色等等。就算只有 40 毫秒,人类也能够对(图片)环境有大致的理解。因此,在视觉系统和描述场景的能力或者语言的能力之间,有一种不寻常的联系。我们的实验室现在正在研究的已经不只是单纯的“感知器”,视觉和语言之间的联系、视觉和推理之间的联系非常非常深,现在的研究还只是开始。
从句子整合到段落
我们最早开始做人类和语言相关的工作可以追溯到 2015 年。
当时,世界上还很少有实验室用和我们一样的想法做图像描述:用 CNN 来表示像素空间,用 RNN 或者 LSTM 来表示序列模型、生成语言。
当时刚刚兴起了第一波算法浪潮,可以根据现有图片自动生成描述的句子。在这个特殊的例子中,穿着橘色马甲的建筑工人正在路上工作,穿着蓝色T恤的人正在弹吉他。这是一个让人印象深刻的例子,但是一个视觉场景并不是短短的一句话能够描述的,而是可以分成不同的组成部分,因此我们接下来就做了“dense captioning”:给定一个场景,我们不仅仅只看这张图片中的整体内容,而是看不同的部分,看感兴趣的区域,然后尝试用语言来描述。
这里有一个例子,这张图片的描述由很多不同的部分组成:一部分是关于人骑在大象上,一部分是关于人坐在长椅上,一部分是关于大象本身的描述,一部分是关于大象身后的森林。比起短短的一句话,这种描述方式,能够提供更多的图片信息。

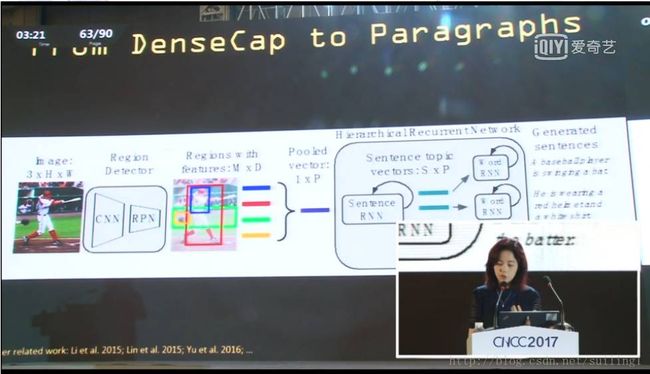
这是去年发布的,今年,就在几个月以前,我们又往前进了一步,开始生成段落。
当然,你可以说只要先生成句子,然后将句子串联起来就成了段落,但是通过这种方式生成的段落并不能令人满意。我们并不想随意地将句子组合起来,我们必须思考如何将句子组合起来,如何让句子之间的过度更加自然,这些就是这篇论文背后的想法。尽管我们已经可以生成段落,但是结果仍然不能令人满意,但是这种方式可以完整地描述场景内容。
自动分割视频关键部分
就在几天前,我的学生在威尼斯举行的 ICCV 大会上展示了我们的工作。我们将原来静态图片上的工作延伸到了视频上,在这个领域,如何检索视频是一个问题。目前,大部分关于视频的工作,要么是通过一些关键目标来进行检索,或者对一个事件(如打篮球)进行整体描述。 
但是在绝大多数的长视频中,里面发生的事件不只一个。于是我们建立了一个包含 20000 段视频的数据集,并对每个视频进行注释,平均每个视频 3.6 个句子。然后我们提出了一种能够在整段视频中临时查看的算法,它能够自动分割视频中的关键部分,然后用句子描述出来。
对于其完整的模型结构,不过我不打算细讲。这个模型的开始的部分是对视频中的 C3D 特征进行特征编码,剩下的部分则是如何找到关键部分并生成描述。
我们跟其他的方法进行了对比,尽管我们是第一个这样做的,但是和其他的方法相比,我们的方法展现了非常不错的前景。
这种工作才刚刚起步,但是我非常兴奋,因为在计算机视觉领域,人们对视频的研究还不够,而这种将视频和自然语言处理连接起来的能力将会创造非常多的可能和应用领域。
从SHRDLU到CLEVR:模块世界+自然语言

演讲的最后部分仍然是关于视觉理解和自然语言处理的,但是在这个特殊的实例里,我想将语言当作推理的媒介,不仅仅是生成描述,而是去推理视觉主题的组成性质。
让我们回到 40 年前,当时 Terry Winograd 创建了一个早期的 AI,叫作 SHRDLU。SHRDLU 是一个“Block World”。人类提出一个问题:“ the blue pyramid is nice. I like blocks which are not red, but I don’t like many thing which supports a pyramid. Do I like the grey box?”,在这个世界里,人类会问出非常复杂的问题,而算法 SHRDLU 需要生成答案:“ No.( Because it supports the pyramid. )”因此这个过程里面涉及到很多的推理。在那个时候,SHRDLU 还是一个局域规则的系统。如今,我们将这种想法用现代的方法重现,在simulation engine(模拟引擎)中使用现代的图片创造另一个数据集——“CLEVR”。
“CLEVR”是一个拥有无限多对象模块的数据集合,我们可能产生不同类型的问题。我们生成了各种各样的问题:一些问题可能是关于attribute(属性)的,比如“有没有哪些大型物体和金属球的数量相同?”;一些问题跟counting(计算)相关,比如“有多少红色的物体?”;一些问题和comparison(比较)相关;还有一些问题与special relationship(特殊关系)相关,等等。
“CLEVR”是一个非常丰富的数据集,由问答集组成,与场景中内容的含义有关。我们如何看待我们的模型呢?与人进行比较。我们发现仅仅使用venilla,CNN,LSTM作为训练模型,人类仍然比机器好得多。当机器的平均性能小于70%时,人类可以达到93%左右的精度。 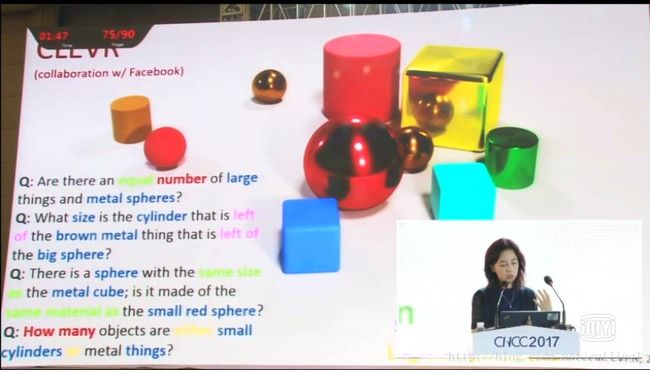
所以有一个巨大的差距。我认为我们差距的原因在于我们的模型不能明确推理。我们把相关的研究也发表在刚刚结束的2017ICCV大会上。
大致原理是,模型首先提取问题并通过自然语言训练生成器。然后我们利用这个模型进行推理,最后得出这些答案。总的来看,是训练一个生成器模型。然后,训练模型和其预测的答案。最后,联合查找及模型,可以对最后的QA给出合理的结果。我们的模型比执行基线(baseline)好很多。
由于李飞飞在演讲中提到了自然语言处理与视觉识别的结合,也提到了微软研究院沈向洋对于自然语言的描述等研究,因此,我们也将沈向阳的演讲内容整理如下,希望对你有所启发。
