大数据----Hive集成Python分析
- 一、Hive的基本使用
-
- 1.1、HIVE的启用
- 1.2、用法
-
- 1.2.1、简介
- 1.2.2、实例
-
-
- 二、SQL进阶用法
- 三、PySpark集成Hive表数据分析
- 四、Hive+Python集成分析(电影评分数据)
-
- 4.1、SQL实现实例
- 4.2、python实现实例
-
- 五、提高:时间戳转化为星期
数据下载地址,点击这里
一、Hive的基本使用
1.1、HIVE的启用
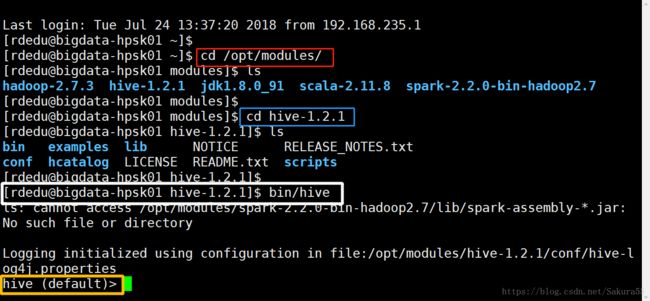
如果安装了mysql,则要先打开mysql

1.2、用法
1.2.1、简介
Spark 大数据分析框架
-1. 功能:
类似MapReduce并行计算框架,对海量数据分析处理
-2. 数据结构:
-a. 最原始数据结构,最核心
RDD(弹性分布式数据集):
类比Python中列表
处理数据调用函数Transformation(高阶函数)
SparkContext: sc (实例对象名称)
-b. 最新数据结构
DataFrame = RDD + Schema(字段类型和字段名称)
SparkSession: spark
spark.read
cvs(.tsv)
.json
.jdbc
.hdfs
…..
result_df.write
.csv(.tsv)
.json
.jdbc
.hdfs
=====================================================
无论是Hadoop框架还是Spark框架数据分析,最多的就是编写SQL分析
大数据机器学习中,算法的训练集数据
通常都是通过SQL语句分析而成
类似于MySQL数据库SQL语句,95%类似SQL 语言:
提供从RDBMS中检索数据(查询数据、分析数据)
语法:
SELECT … FROM … WHERE … GROUP BY … ORDER BY …SQL on HADOOP
能否给用户提供SQL语法,对海量数据进行分析(底层MR/Spark)
1.2.2、实例
● 创建数据库
CREATE DATABASE IF NOT EXISTS db_hive ;● 使用数据库
USE db_hive ;● 创建表
'''
样本数据:
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
'''
CREATE TABLE IF NOT EXISTS db_hive.sg_log(
access_time string,
user_id string,
search_word string,
sortId_clickId string,
url string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
● 加载数据文件 到 表中
LOAD DATA LOCAL INPATH '/home/rdedu/SogouQ.sample' INTO TABLE db_hive.sg_log ;
LOAD DATA LOCAL INPATH '/home/rdedu/SogouQ.reduced' INTO TABLE db_hive.sg_log ;● 设置HiveQL转换MapReduce运行在LocalMode中
set hive.exec.mode.local.auto=true;● 查看条目数
-- hive (db_hive)>
select count(1) from sg_log ;● 查看样本数据
-- hive (db_hive)>
select * from sg_log limit 5 ;● 删除表
DROP TABLE IF EXISTS db_hive.sg_log ;● 设置HiveQL转换MapReduce运行在LocalMode中
set hive.exec.mode.local.auto=true;● 对 搜狗用户日志分析,一天的额数据,设置参数,以便运行在本地模式
set hive.exec.mode.local.auto.inputbytes.max = 160939050 ;● 分析数据(依据业务)来分析
--1. 统计每个用户的PV数,降序排列desc pv: pageview 用户浏览网页个数
SELECT user_id, COUNT(1) AS pv FROM db_hive.sg_log GROUP BY user_id ORDER BY pv DESC LIMIT 10 ;
--2. 统计每个小时的PV数
SELECT t.hour_str, COUNT(1) AS pv
FROM (
SELECT SUBSTRING(access_time,0 ,2) AS hour_str, url FROM db_hive.sg_log
) AS t
GROUP BY t.hour_str ORDER BY pv DESC ;
--3. 统计每个用户搜索关键词点击结果的次数
-- 从某种程度上,检验 搜索引擎底层技术
SELECT
user_id, search_word, COUNT(1) AS cnt
FROM
db_hive.sg_log
GROUP BY
user_id, search_word
ORDER BY
cnt DESC
LIMIT 20 ;
--4. 统计每个用户搜索关键词的的个数
SELECT user_id, COUNT(DISTINCT search_word) AS cnt FROM db_hive.sg_log GROUP BY user_id ORDER BY cnt DESC LIMIT 10 ;二、SQL进阶用法
● 创建数据库
CREATE DATABASE IF NOT EXISTS db_movie ;
--创建表:用户信息表
-- 样本数据:
-- 1|24|M|technician|85711
-- user id | age | gender | occupation | zip code
--
CREATE TABLE IF NOT EXISTS db_movie.ml_user(
user_id string,
age string,
gender string,
occupation string,
zipcode string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';-- 创建表: 电影评分表
-- 样本数据:
-- 196 242 3 881250949
-- user id | item id | rating | timestamp
--
CREATE TABLE IF NOT EXISTS db_movie.ml_rating(
user_id string,
item_id string,
rating string,
unixtime string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';● 加载数据到 用户信息表
LOAD DATA LOCAL INPATH '/home/rdedu/ml-100k/u.user' INTO TABLE db_movie.ml_user ;● 加载数据到 电影评分表
LOAD DATA LOCAL INPATH '/home/rdedu/ml-100k/u.data' INTO TABLE db_movie.ml_rating ;● 统计表中的条目数
SELECT COUNT(1) AS FROM db_movie.ml_rating ;
SELECT COUNT(1) AS FROM db_movie.ml_user ;● 每部电影的评分人数及平均分
SELECT
item_id, COUNT(item_id) AS num, ROUND(AVG(rating), 2) AS avg_rating
FROM
db_movie.ml_rating
GROUP BY
item_id
ORDER BY
num DESC, avg_rating DESC
LIMIT
10 ;● 每个用户评分的次数和工作
SELECT
t1.user_id, t1.cnt, t2.occupation
FROM(
SELECT user_id, COUNT(1) AS cnt FROM db_movie.ml_rating GROUP BY user_id ORDER BY cnt DESC
) t1
JOIN
db_movie.ml_user t2
ON
t1.user_id = t2.user_id ;● 将上述分析结果存储到一个临时结果表中,为后续进行分析提供方便
/*
在Hive中使用CTAS方式创建表或将分析结果存储到新表中
CTAS:Create Table As Select
*/
CREATE TABLE IF NOT EXISTS db_movie.user_cnt_occu
AS
SELECT
t1.user_id, t1.cnt, t2.occupation
FROM(
SELECT user_id, COUNT(1) AS cnt FROM db_movie.ml_rating GROUP BY user_id ORDER BY cnt DESC
) t1
JOIN
db_movie.ml_user t2
ON
t1.user_id = t2.user_id ; ● 统计 评分的用户中各个职业的人数
SELECT occupation, SUM(cnt) AS total FROM db_movie.user_cnt_occu GROUP BY occupation ORDER BY total DESC limit 21 ;● 先统计有多少个职业
SELECT COUNT(DISTINCT occupation) AS cnt FROM db_movie.user_cnt_occu ;三、PySpark集成Hive表数据分析
# SparkSQL从Hive表中读取数据
# 1. 启动pyspark交互式命令行
$ cd /opt/modules/spark-2.2.0-bin-hadoop2.7/
$ bin/pyspark --master local[2]
# 测试读取hive表的数据
spark.sql("show databases").show()
# 读取ml_user表中的数据
ml_user_df = spark.read.table("db_movie.ml_user")
ml_user_df.printSchema()
ml_user_df.groupBy('occupation').count().show()
"""
使用SparkSession中sql函数,直接对hive表使用SQL分析
"""
week_day_df = spark.sql('SELECT weekday, COUNT(1) AS total FROM db_movie.ml_rating_new GROUP BY weekday ORDER BY total DESC')
# 复杂数据分析
user_movie_df = spark.sql("""
SELECT
t1.user_id, t1.cnt, t2.occupation
FROM(
SELECT user_id, COUNT(1) AS cnt FROM db_movie.ml_rating GROUP BY user_id ORDER BY cnt DESC
) t1
JOIN
db_movie.ml_user t2
ON
t1.user_id = t2.user_id
""")
user_movie_df.show()
# 将DataFrame 注册为一个临时视图
user_movie_df.createOrReplaceTempView('view_tmp_movie')
# 继续使用SQL分析
spark.sql('SELECT occupation, SUM(cnt) AS total FROM view_tmp_movie GROUP BY occupation ORDER BY total DESC limit 21').show()四、Hive+Python集成分析(电影评分数据)
4.1、SQL实现实例
CREATE TABLE IF NOT EXISTS db_movie.ml_rating_new(
user_id string,
item_id string,
rating string,
weekday string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 加载脚本文件到集群开发环境 中
add file /home/rdedu/ml-100k/unixtime_to_weekday.py ;
-- 从原数据表中读取数据,加载到 业务数据表
INSERT OVERWRITE TABLE db_movie.ml_rating_new
SELECT
TRANSFORM (user_id, item_id, rating, unixtime)
USING 'python unixtime_to_weekday.py'
AS (user_id, item_id, rating, weekday)
FROM
db_movie.ml_rating ;
/*
如何使用Python脚本处理Hive表中数据????
python脚本处理表的每条数据
遵循原则:
-a. 输入数据 TRANSFORM
表中的字段
-b. 处理数据 USING
指定python脚本处理数据
-c. 输出数据 AS
输出字段
*/
-- 统计一周中 每天观看电影的人数
SELECT weekday, COUNT(1) AS total FROM db_movie.ml_rating_new GROUP BY weekday ORDER BY total DESC ;4.2、python实现实例
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@version: v1.0
@author: Kian
@time: 2018/7/24 14:34
"""
import os
import time
from pyspark.sql import SparkSession
if __name__ == "__main__":
# 由于在系统的环境变量中没有设置相关看见的安装目录,所以在程序中设置
os.environ['JAVA_HOME'] = 'C:/Java/jdk1.8.0_91'
# 设置HADOOP框架安装目录,为了HADOOP在Windows兼容性设置
os.environ['HADOOP_HOME'] = 'C:/Java/hadoop-2.6.0-cdh5.7.6'
# 设置SPARK框架安装目录,必须设置
os.environ['SPARK_HOME'] = 'C:/Java/spark-2.2.0-bin-2.6.0-cdh5.7.6'
# 实例化SparkSession对象,以本地模式是运行Spark程序
spark = SparkSession \
.builder \
.appName("Hello_World_Application") \
.master("local[2]")\
.getOrCreate()
# print type(spark)
# print spark
# 读取数据, 一行一行的读取文本文件中的数据,每行数据的字段名称为value,数据类型为字符串
log_data = spark.read.text("datas/README.md")
print type(log_data)
# Row(value=u'# Apache Spark')
print log_data.first()
print "Count: " + str(log_data.count())
print '\n'
# 在Spark框架中可以将数据进行缓存,以便再次使用时,直接从缓存中读取数据
# 默认缓存级别:MEMORY_AND_DISK,先放内存,不足放磁盘
log_data.cache()
# 对DataFrame中每条数据进行过滤,获取每条数据中的value字段的只值,进行筛选
nums_spark = log_data.filter(log_data.value.contains('Spark')).count()
nums_python = log_data.filter(log_data.value.contains('Python')).count()
print("Lines with Spark: %i, lines with Python: %i" % (nums_spark, nums_python))
print "==============================================="
"""
使用SparkSession读取wc.data,进行WordCount统计
"""
# 读取数据,数据封装在DataFrame集合中
wc_df = spark.read.text('datas/wc.data')
print type(wc_df)
wc_df.show(n=5, truncate=False)
# DataFrame = RDD + schema, 如何将DataFrame转换为RDD
# wc_df.rdd()
"""
SparkSQL中对数据分析两种方式:
-1. DSL分析
调用DataFrame中函数
-2. SQL分析
需要将DataFrame注册为临时视图,编写类似MySQL中SQL进行分析
"""
# 导入SparkSQL中函数库
from pyspark.sql.functions import *
word_df = wc_df\
.select(explode(split(wc_df.value, '\\s+')).alias('word'))\
word_count_df = word_df.groupBy('word').count() # 操作以后, 聚合count以后的字段名称为count
word_count_df.show()
# fitler_df = word_df.filter("length(word_df.word.strip) > 0")
print '======================================'
# 注册时临时视图
word_df.createOrReplaceTempView('view_tmp_word')
spark.sql('SELECT word, COUNT(1) AS count FROM view_tmp_word GROUP BY word').show()
# 读取CSV文件
csv_df = spark.read.csv('datas/flights.csv', header=True, inferSchema=True)
csv_df.printSchema()
csv_df.show(n=10, truncate=False)
csv_df.write.csv('datas/flights.tsv', header=True, sep='\t')
# 为了查看Spark程序运行是的WEB UI界面,让线程休眠一段时间
time.sleep(100000)
# SparkContext Stop
spark.stop()五、提高:时间戳转化为星期
#!/usr/local/bin/python
# -*- coding: utf-8 -*-
import sys
import datetime
"""
将878887116 时间戳转换为星期几
"""
# 从标准输入读取数据(913 209 2 881367150)
for line in sys.stdin:
# 去除字符串左右空格
line = line.strip()
# 按照制表符进行分割
user_id, item_id, rating, unixtime = line.split("\t")
# 调用函数 转换时间戳为星期几
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
# 标准输出
print '\t'.join([user_id, item_id, rating, str(weekday)])