Python学习笔记(三)——基于用户的协同过滤(推荐算法)
一、基本原理

用户A,和用户C都喜欢物品A,和物品C,表明他们兴趣相同,则可向用户A推荐物品D
那么如何表示两个用户兴趣相同呢?
有如下用户对物品的评分矩阵
| item1 | item2 | item3 | item4 | item5 | |
| Bob | 5 | 3 | 0 | 5 | 5 |
| Alice | 5 | 0 | 0 | 4 | 5 |
| Carle | 5 | 4 | 0 | 4 | 5 |
| Dum | 0 | 3 | 0 | 4 | 4 |
| Enime | 0 | 0 | 1 | 5 | 3 |
①找出相似用户
计算两个用户兴趣是否相同则可以使用余弦相似度(cos)或皮尔逊相关系数(pearson)进行用户相似度计算
评分矩阵中的行代表了用户向量,列代表了物品向量,计算用户间的相似度是计算评分矩阵中行向量的相似度。
cos:

pearson:
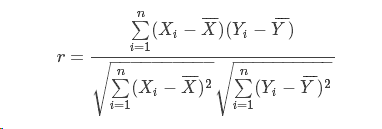
注:相关系数有一个明显的缺点,即它接近于1的程度与数据组数n相关,这容易给人一种假象。因为,当n较小时,相关系数的波动较大,对有些样本相关系数的绝对值易接近于1;当n较大时,相关系数的绝对值容易偏小。特别是当n=2时,相关系数的绝对值总为1。因此在样本容量n较小时,我们仅凭相关系数较大就判定变量x与y之间有密切的线性关系是不妥当的。
②对未评分物品进行预测评分并推荐
Alice和Bob的相似度为0.864048379427
Alice和Carle的相似度为0.726595958504
故可以借助Bob的评分信息对Alice没评分的物品进行预测评分,并进行推荐
二、算法实现:
1.数据预处理
读取数据,并浏览
import pandas as pd
data=pd.read_csv('file.csv',names=['userId', 'movieId', 'rating']) #读取文件并改列名
data.head(15) #浏览前10行
userId movieId rating
0 1 1 3.5
1 1 2 2.0
2 1 4 4.5
3 1 5 5.0
4 1 6 1.5
5 1 7 2.5
6 1 8 2.0
7 2 1 2.0
8 2 2 3.5
9 2 3 4.0这种对电影评分的数据较为好处理,可以直接利用pandas的透视函数pivot()转换成用户评分矩阵
user-item=data.pivot(index='userId', columns='movieId', values='rating')
user-item:
movieId 1 2 3 4 5 6 7 8
userId
1 3.5 2.0 NaN 4.5 5.0 1.5 2.5 2.0
2 2.0 3.5 4.0 NaN 2.0 3.5 NaN 3.0
3 5.0 1.0 1.0 3.0 5.0 1.0 NaN NaN
4 3.0 4.0 4.5 NaN 3.0 4.5 4.0 2.0
5 NaN 4.0 1.0 4.0 NaN NaN 4.0 1.0
6 NaN 4.5 4.0 5.0 5.0 4.5 4.0 4.0
7 5.0 2.0 NaN 3.0 5.0 4.0 5.0 NaN
8 3.0 NaN NaN 5.0 4.0 2.5 3.0 4.0如果遇到一些比较乱的数据,则需要进行合并查重,处理空值,归一化等工作后,才好转换
#处理前
num user love point
0 1 10001 1 0.001389
1 2 10001 1 0.000694
2 3 10002 16 0.006250
3 4 10002 17 0.003472
4 5 10002 1 0.010417
5 6 10002 3 0.001389
6 7 10002 16 0.002778
7 8 10002 11 0.174306
8 9 10002 6 0.017361
9 10 10002 3 0.000694
10 11 10002 16 0.095139
11 12 10002 112 0.005556
12 13 10002 160 0.008333
13 14 10002 6 0.018056
14 15 10002 4 0.013194
15 16 10002 116 0.000694
16 17 10002 6 0.001389
17 18 10002 24 0.010417
18 19 10002 4 0.001389
19 20 10002 21 0.002083
def dataSet2Matrix():
ds=pd.read_csv('file.csv',names=['num','user','love','point'])
ds_2=ds.head()
ds_2.drop([0,1,2,3,4],inplace=True)
user=set()
for i in ds['user'].values:
user.add(i)
for i in user:
ds_1=ds[ds['user']==i].groupby('love').sum()
ds_1.drop(columns=['user'],inplace=True)
ds_1['user']=i
ds_1['love']=ds_1.index
ds_1.index=ds_1['num'].values
ds_2=pd.concat([ds_1,ds_2],axis=0,sort=False,ignore_index=True)
global df
df=ds_2.pivot(index='user',columns='love',values='point')
#处理后
num point user love
125 3 0.002083 10001 1
104 220 0.038194 10002 1
105 52 0.043750 10002 3
106 139 0.042361 10002 4
107 38 0.004167 10002 5
108 152 0.062500 10002 6
109 8 0.174306 10002 11
110 113 0.109028 10002 16
111 4 0.003472 10002 17
112 65 0.004861 10002 21
113 54 0.017361 10002 22
124 98 0.036111 10002 160
115 88 0.023611 10002 24
116 244 0.025000 10002 112
117 37 0.001389 10002 116
118 53 0.004167 10002 117
119 28 0.001389 10002 119
120 100 0.018056 10002 120
121 56 0.006944 10002 121
122 24 0.048611 10002 129
#转换后
love 1 2 3 4 5 6 7 ....
user
10001 0.002083 NaN NaN NaN NaN NaN NaN
10002 0.038194 NaN 0.043750 0.042361 0.004167 0.062500 NaN
10003 0.081250 NaN NaN NaN NaN NaN NaN
10004 0.595833 0.218750 0.198611 0.157639 0.711806 0.134722 0.717361
10005 2.150694 0.510417 2.443056 0.025000 4.064583 4.150000 NaN
10008 NaN NaN 0.002083 0.001389 0.101389 0.520833 0.019444
10009 NaN NaN NaN NaN NaN NaN 0.971528
10010 0.000694 0.002083 0.002083 0.015278 NaN 0.040972 0.002778
10011 1.475694 0.004167 NaN NaN 0.642361 0.056250 0.001389
10012 NaN NaN NaN NaN NaN NaN NaN
...
..
.
2.计算用户相似度:
user-item:
movieId 1 2 3 4 5 6 7 8
userId
1 3.5 2.0 NaN 4.5 5.0 1.5 2.5 2.0
2 2.0 3.5 4.0 NaN 2.0 3.5 NaN 3.0
3 5.0 1.0 1.0 3.0 5.0 1.0 NaN NaN
4 3.0 4.0 4.5 NaN 3.0 4.5 4.0 2.0
5 NaN 4.0 1.0 4.0 NaN NaN 4.0 1.0
6 NaN 4.5 4.0 5.0 5.0 4.5 4.0 4.0
7 5.0 2.0 NaN 3.0 5.0 4.0 5.0 NaN
8 3.0 NaN NaN 5.0 4.0 2.5 3.0 4.0
# 构建共同的评分向量
def build_xy(user_id1, user_id2):
bool_array = df.loc[user_id1].notnull() & df.loc[user_id2].notnull()
return df.loc[user_id1, bool_array], df.loc[user_id2, bool_array]
#如此用户评分矩阵中用户1,和用户2的共同评分向量是
movieId
1 3.5
2 2.0
5 5.0
6 1.5
8 2.0
Name: 1, dtype: float64,
movieId
1 2.0
2 3.5
5 2.0
6 3.5
8 3.0
Name: 2, dtype: float64)
# 皮尔逊相关系数
def pearson(user_id1, user_id2):
x, y = build_xy(user_id1, user_id2)
mean1, mean2 = x.mean(), y.mean()
# 分母
denominator = (sum((x-mean1)**2)*sum((y-mean2)**2))**0.5
try:
value = sum((x - mean1) * (y - mean2)) / denominator
except ZeroDivisionError:
value = 0
return value
3.找到相似度最高的用户并进行推荐:
# 计算最相似的邻居
def computeNearestNeighbor(user_id, k=3):
return df.drop(user_id).index.to_series().apply(pearson, args=(user_id,)).nlargest(k)
#与用户3相似的前3个用户
userId
1 0.819782
6 0.801784
7 0.766965
Name: userId, dtype: float64
#推荐
def recommend(user_id):
# 找到最相似的用户id
nearest_user_id = computeNearestNeighbor(user_id).index[0]
print('最相似用户ID:')
print nearest_user_id
# 找出邻居评价过、但自己未曾评价的项目
# 结果:index是项目名称,values是评分
return df.loc[nearest_user_id, df.loc[user_id].isnull() & df.loc[nearest_user_id].notnull()].sort_values()
#对用户3进行推荐结果
最相似用户ID:
1
movieId
8 2.0
7 2.5
Name: 1, dtype: float64
总结:
协同过滤推荐算法还有有基于项目的协同过滤和基于模型的协同过滤,基于用户(user-based)的协同过滤主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户,可以挖掘用户的隐藏属性。而基于项目(item-based)的协同过滤和基于用户的协同过滤类似,只不过这时我们转向找到物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么我们就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。而基于模型的协同过滤,就是借助机器学习中的各种模型实现推荐算法啦。