MNIST数据集转换为.png图像(Python实现)
在图像分类任务中,PyTorch有一个现成的图片数据集读取函数 : torchvision.datasets.ImageFolder。这个api的使用方法为:假设所有图片数据都按文件夹保存好,每个文件夹下存储的是同一类别的图片数据,文件夹的名字为类别的名字。将这些按类别保存图片的文件夹都放到一个大文件夹下。在代码中的命令如下:
dataset = torchvision.datasets.ImageFolder(root=保存着类别文件夹的大文件夹的位置,
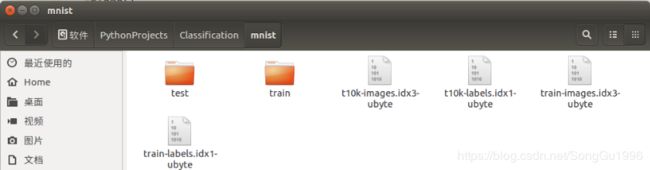
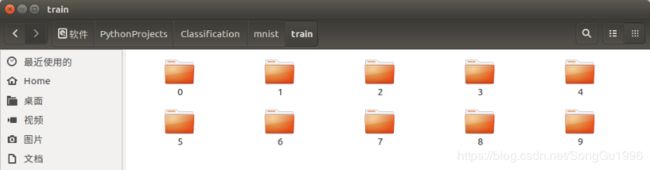
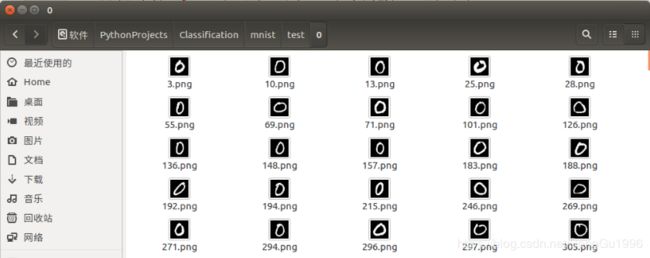
transform=对图像数据设置的一些预处理操作)MNIST手写数字数据集非常经典,它由60000个训练样本和10000个测试样本组成,每个样本都是一张28×28的灰度图片。这个数据集对硬件要求较低,所以很多初学者都选择它作为深度学习的入门选择。需要注意的是,直接下载下来的MNIST数据是无法通过解压或应用程序打开的,因为它里面的文件不是标准的图像格式,而是以字节的形式存储的,所以需要借助编程的手段来打开。虽然MNIST数据集在PyTorch中有自己专门的读取函数:torchvision.datasets.MNIST,但是在使用自己的数据集进行学习和实验时,一般使用的是标准格式的图片,为了向一般情况靠拢,使用以下代码将MNIST数据集转换成标准格式的图像,并像上文所述的那样,将每一类图片保存到单独的文件夹中,便于直接用PyTorch的数据集读取函数读取,编程工具为Python3.6。
MNIST数据集的下载地址为:
链接:https://pan.baidu.com/s/1jIseh5Nqph9_xdmD1btESg
提取码:ry8w
import struct
from array import array
import os
# 通过 pip install pypng 命令安装此库
import png
trainimg = './mnist/train-images.idx3-ubyte'
trainlabel = './mnist/train-labels.idx1-ubyte'
testimg = './mnist/t10k-images.idx3-ubyte'
testlabel = './mnist/t10k-labels.idx1-ubyte'
trainfolder = './mnist/train'
testfolder = './mnist/test'
if not os.path.exists(trainfolder): os.makedirs(trainfolder)
if not os.path.exists(testfolder): os.makedirs(testfolder)
# open(文件路径,读写格式),用于打开一个文件,返回一个文件对象
# rb表示以二进制读模式打开文件
trimg = open(trainimg, 'rb')
teimg = open(testimg, 'rb')
trlab = open(trainlabel, 'rb')
telab = open(testlabel, 'rb')
# struct的用法这里不详述
struct.unpack(">IIII", trimg.read(16))
struct.unpack(">IIII", teimg.read(16))
struct.unpack(">II", trlab.read(8))
struct.unpack(">II", telab.read(8))
# array模块是Python中实现的一种高效的数组存储类型
# 所有数组成员都必须是同一种类型,在创建数组时就已经规定
# B表示无符号字节型,b表示有符号字节型
trimage = array("B", trimg.read())
teimage = array("B", teimg.read())
trlabel = array("b", trlab.read())
telabel = array("b", telab.read())
# close方法用于关闭一个已打开的文件,关闭后文件不能再进行读写操作
trimg.close()
teimg.close()
trlab.close()
telab.close()
# 为训练集和测试集各定义10个子文件夹,用于存放从0到9的所有数字,文件夹名分别为0-9
trainfolders = [os.path.join(trainfolder, str(i)) for i in range(10)]
testfolders = [os.path.join(testfolder, str(i)) for i in range(10)]
for dir in trainfolders:
if not os.path.exists(dir):
os.makedirs(dir)
for dir in testfolders:
if not os.path.exists(dir):
os.makedirs(dir)
# 开始保存训练图像数据
for (i, label) in enumerate(trlabel):
filename = os.path.join(trainfolders[label], str(i) + ".png")
print("writing " + filename)
with open(filename, "wb") as img:
image = png.Writer(28, 28, greyscale=True)
data = [trimage[(i*28*28 + j*28) : (i*28*28 + (j+1)*28)] for j in range(28)]
image.write(img, data)
# 开始保存测试图像数据
for (i, label) in enumerate(telabel):
filename = os.path.join(testfolders[label], str(i) + ".png")
print("writing " + filename)
with open(filename, "wb") as img:
image = png.Writer(28, 28, greyscale=True)
data = [teimage[(i*28*28 + j*28) : (i*28*28 + (j+1)*28)] for j in range(28)]
image.write(img, data)代码运行完成后,mnist文件夹中的内容如下第一张图所示,train文件夹中的内容如下第二张图所示,第三张图则是展示数据集中的一些数字图片。在这里提醒大家一下,MNIST数据集是黑底白字!黑底白字!黑底白字!我发现有不少刚入门的小伙伴,满怀热情地调通了LeNet-5,训练准确率也很高,但是用自己的图片来预测却怎么都不对,甚至开始怀疑这个网络。但是LeNet是肯定没有问题的,因为当年美国大多数银行都是借助LeNet来识别支票上的手写数字,这是第一个大规模商用的神经网络,有效性毋庸置疑。其实很可能是因为你用白底黑字的图来预测的,换一张黑底白字的图再试试吧。