Python爬虫【urllib模块】
通用爬虫
爬虫的一般流程
1 初始化一批URL,将这些URL放入队列
2 从队列中取出这些URL,通过DNS解析IP,对IP对应的网站下载HTML页面,保存到本地服务器中,爬取完的URL放到已爬取队列。
3 分析这些网页得内容,找出网页里面得其他关心的URL连接,继续执行第2步,知道爬取条件结束
搜素引擎如何获取一个新网站的URL
1 新网站主动提交搜索引擎
2 通过其它网站页面中设置的外链
3搜索引擎和DNS服务商合作,获取最新收录的网站
聚焦爬虫
有针对的编写特定领域数据的爬虫程序,针对某些类别数据采集的爬虫,是面向主题的爬虫
Robots协议
制定一个robots.txt,告诉爬虫引擎什么可以爬取;什么不让爬取(所以可以在robots协议里可以看到它们的重要数据)
例如:
淘宝:http://www.taobao.com/robots.txt 必须用搜索引擎(索引库),绝对不是Mysql的搜索匹配
user-agent:Baiduspider "百度搜索引擎"
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /product/ "product下面的内容不允许爬虫 "
Disallow: / "根下面的内容不允许爬虫 "
user-agent:Googlebot
Allow: /article
Allow: /oshtml
Allow: /ershou
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
user-agent:Bingbot
Allow: /article
Allow: /oshtml
Allow: /ershou
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
user-agent:Yahoo! Slurp
Allow: /ershou
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
user-agent:* “对于其他所以搜索引擎都是不允许的”,比如我们写的爬虫
Disallow: /马蜂窝:http://www.mafengwo.cn/robots.txt
User-agent: Baiduspider
Disallow: /music/
Disallow: /booking/discount_booking.php
Disallow: /secrect/
Disallow: /rank/
Disallow: /hotel/s.php
Disallow: /order_center/
Disallow: /hotel_zx/order/detail.php
Disallow: /sales/order/
User-agent: Googlebot
Disallow: /music/
Disallow: /booking/discount_booking.php
Disallow: /secrect/
Disallow: /rank/
Disallow: /hotel/s.php
Disallow: /order_center/
Disallow: /hotel_zx/order/detail.php
Disallow: /sales/order/
User-agent: Bingbot
Disallow: /music/
Disallow: /booking/discount_booking.php
Disallow: /secrect/
Disallow: /rank/
Disallow: /hotel/s.php
Disallow: /order_center/
Disallow: /hotel_zx/order/detail.php
Disallow: /sales/order/
####
这里删除了一部分
####
User-agent:YisouSpider
Disallow: /music/
Disallow: /booking/discount_booking.php
Disallow: /secrect/
Disallow: /rank/
Disallow: /hotel/s.php
Disallow: /order_center/
Disallow: /hotel_zx/order/detail.php
Disallow: /sales/order/
User-agent: *
Disallow: /
Disallow: /poi/detail.php
Sitemap: http://www.mafengwo.cn/sitemapIndex.xml
如果你想知道网站的信息,"Sitemap: http://www.mafengwo.cn/sitemapIndex.xml" 请点击该链接:点进去之后是个二级连接。这里面就是它提供的让你爬取得站点地图信息,友好的访问指向。
HTTP请求和响应处理
其实爬去网页就是通过HTTP协议访问网页,不过通过浏览器访问往往是人的行为,把这种行为变成使用程序来访问。
urllib包:
urllib是标准库,它是一个工具包模块,包含下面模块处理URL:
1 urllib.request 用于打开和读写url “最重要的”
2 urllib.error 包含由urllib.request引起的异常
3 urllib.parse 用于解析url
4 urllib.robotparser 分析robots.txt文件
python2中提供了urllib和urllib2,urllib提供较为底层的接口,urllib2对urllib进行了进一步的封装。
python3将urllib合并到了urllib2,并且只提供了标准库urllib包。
urllib.request模块
模块定义了在基本和摘要式身份认证,重定向,cookies等应用中打开url(主要是http)的函数和类
- urllib.request.Request(url,data = None,headers = {})
url是链接地址的字符串或者reuqest类的实例(urllib.request.Request)
data是get或post;如果data = None,则发起get请求,否则发起post请求。
headers默认是个字典,里面存的是键值对。请求头里包括的内容有:
Accept; Cookie; User-Agent:告诉服务器,自己的版本,为了让服务器给自己返回合适的响应。
- urllib.request.urlopen(url,data = None)
url是链接地址的字符串或者reuqest类的实例(urllib.request.Request)
data是get或post;如果data = None,则发起get请求,否则发起post请求。
返回:http.client.HTTPResponse类的响应对象,这是一个类文件对象。
- urllib.parse({'id':1, 'name':'tom}) 必须是字典的形式
用于解析模块
以下是个实例
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 14 11:09:46 2018
@author: DELL
"""
from urllib.request import urlopen
from http.client import HTTPResponse
#打开一个url返回一个响应对象,类文件对象
url = "http://www.bing.com"
response = urlopen(url) #get方法
print(response.closed) #类文件对象:支持上下文管理
with response: #with语法
print(type(response)) #http.client.HTTPResponse 类对象文件
print(response.status,response.reason) #状态
print(response._method) #返回方法是get还是post
print(response.read()) #返回读取的内容
print(response.info()) #返回headers
print(response.geturl()) #重定向之后返回真正的url
print(response.closed)
下面是返回结果
runfile('C:/Users/DELL/Desktop/python/spyder_test1.py', wdir='C:/Users/DELL/Desktop/python')
False
200 OK
GET
b'\xe5\xbe\xae\xe8\xbd\xaf Bing \xe6\x90\x9c\xe7\xb4\xa2 - \xe5\x9b\xbd\xe5\x86\x85\xe7\x89\x88 \xe5\xbf\x85\xe5\xba\x94\xe5\x9b\xbd\xe5\x86\x85\xe7\x89\x88\xe5\x9b\xbd\xe9\x99\x85\xe7\x89\x88
'
Cache-Control: private, max-age=0
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Vary: Accept-Encoding
P3P: CP="NON UNI COM NAV STA LOC CURa DEVa PSAa PSDa OUR IND"
Set-Cookie: SRCHD=AF=NOFORM; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUID=V=2&GUID=9689D0C3152443DB9AB516DA7787024F&dmnchg=1; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUSR=DOB=20181114; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: _SS=SID=2EA0EABA00306B51311AE61D011E6A4B; domain=.bing.com; path=/
X-MSEdge-Ref: Ref A: AF2F6BBE92A14BC5A05C9A9B04F06838 Ref B: BJ1EDGE0219 Ref C: 2018-11-14T04:16:45Z
Set-Cookie: _EDGE_S=F=1&SID=2EA0EABA00306B51311AE61D011E6A4B; path=/; httponly; domain=bing.com
Set-Cookie: _EDGE_V=1; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUID=0CD0C497736D6F510D23C83072436EFF; path=/; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUIDB=0CD0C497736D6F510D23C83072436EFF; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT
Date: Wed, 14 Nov 2018 04:16:45 GMT
Connection: close
http://cn.bing.com/?setmkt=zh-CN&setmkt=zh-CN
True 

 '
Cache-Control: private, max-age=0
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Vary: Accept-Encoding
P3P: CP="NON UNI COM NAV STA LOC CURa DEVa PSAa PSDa OUR IND"
Set-Cookie: SRCHD=AF=NOFORM; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUID=V=2&GUID=9689D0C3152443DB9AB516DA7787024F&dmnchg=1; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUSR=DOB=20181114; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: _SS=SID=2EA0EABA00306B51311AE61D011E6A4B; domain=.bing.com; path=/
X-MSEdge-Ref: Ref A: AF2F6BBE92A14BC5A05C9A9B04F06838 Ref B: BJ1EDGE0219 Ref C: 2018-11-14T04:16:45Z
Set-Cookie: _EDGE_S=F=1&SID=2EA0EABA00306B51311AE61D011E6A4B; path=/; httponly; domain=bing.com
Set-Cookie: _EDGE_V=1; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUID=0CD0C497736D6F510D23C83072436EFF; path=/; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUIDB=0CD0C497736D6F510D23C83072436EFF; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT
Date: Wed, 14 Nov 2018 04:16:45 GMT
Connection: close
http://cn.bing.com/?setmkt=zh-CN&setmkt=zh-CN
True
'
Cache-Control: private, max-age=0
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Vary: Accept-Encoding
P3P: CP="NON UNI COM NAV STA LOC CURa DEVa PSAa PSDa OUR IND"
Set-Cookie: SRCHD=AF=NOFORM; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUID=V=2&GUID=9689D0C3152443DB9AB516DA7787024F&dmnchg=1; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: SRCHUSR=DOB=20181114; domain=.bing.com; expires=Sat, 14-Nov-2020 04:16:45 GMT; path=/
Set-Cookie: _SS=SID=2EA0EABA00306B51311AE61D011E6A4B; domain=.bing.com; path=/
X-MSEdge-Ref: Ref A: AF2F6BBE92A14BC5A05C9A9B04F06838 Ref B: BJ1EDGE0219 Ref C: 2018-11-14T04:16:45Z
Set-Cookie: _EDGE_S=F=1&SID=2EA0EABA00306B51311AE61D011E6A4B; path=/; httponly; domain=bing.com
Set-Cookie: _EDGE_V=1; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUID=0CD0C497736D6F510D23C83072436EFF; path=/; expires=Mon, 09-Dec-2019 04:16:45 GMT; domain=bing.com
Set-Cookie: MUIDB=0CD0C497736D6F510D23C83072436EFF; path=/; httponly; expires=Mon, 09-Dec-2019 04:16:45 GMT
Date: Wed, 14 Nov 2018 04:16:45 GMT
Connection: close
http://cn.bing.com/?setmkt=zh-CN&setmkt=zh-CN
True上面的例子,其实就是通过urllib.request.urlopen的方法,发起了一个HTTP的GET请求,WEB服务器返回了网页内容。响应的数据被封装到类文件对象中,可以通过read()方法,readline()方法和readlines()的方法获取数据,status和reason属性表示返回的状态吗,info方法返回头信息等。
User-Agent 问题
很多网站其实是不想让大家用python爬虫去爬的,比如上面的淘宝网站也是,只允许百度,谷歌等部分搜索引擎对其进行搜索。而如果我们用python去爬的时候,它的User-agent是python,被爬的网站会采取一种反爬虫的方法,禁止python等爬虫方式的访问。因此,在这里就需要所谓的伪装User-agent。
urlopen(url,data)只能传递URL和data这样的数据,不能构造HTTP的请求,例如User-Agent。在python源码中构造useragent的方法如下:在openerDirector里面
#urllib.request.OpenerDirector
class openerDirector:
def __init__(self):
client_version = "python-urliib/%s"%__version__
self.addheaders = [("User-agent",client_version)]当前显示的是python-urllib/3.6
而urllib.request.Request(url,data = None,headers = {})可以修改User-Agent 到headers里,伪装~主要有以下两种方式:
其思路都是一致的,也就是:将User-Agent封装在Request的类对象里,再对其使用urlopen。
- req = Request(url,headers = {'User-Agent':ua})
- req = Request(url)
- req.add_header('User-Agent',ua)
代码变化为:
from urllib.request import urlopen,Request
import random
#from http.client import HTTPResponse
#伪造一个user-agent的列表分别是:谷歌,火狐,IE;
url = "http://www.bing.com/"
ua_list = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"]
ua = random.choice(ua_list)#随机选择一个user-agent
req = Request(url,headers = {'User-Agent':ua})
#req.add_header('User-Agent',ua)
response = urlopen(req) #get方法
print(response.closed) #类文件对象:支持上下文管理
print(type(response)) #http.client.HTTPResponse 类对象文件
with response: #with语法
print(1, response.status,response.getcode(),response.reason) #状态
print(2, response.geturl()) #返回真正的url
print(3, response.read()) #返回读取的内容
print(4, response.info()) #返回headers
print(5,req.get_header('User-agent'))至于如何让在谷歌浏览器中,找到切换搜索引擎(也就是我们这里写的ua_list的内容)的地方:见https://jingyan.baidu.com/article/0bc808fc0b66621bd485b926.html
结果如下
False
1 200 200 OK
2 http://cn.bing.com/
3 b'\xe5\xbe\xae\xe8\xbd\xaf Bing \xe6\x90\x9c\xe7\xb4\xa2 - \xe5\x9b\xbd\xe5\x86\x85\xe7\x89\x88 \xe5\xbf\x85\xe5\xba\x94\xe5\x9b\xbd\xe5\x86\x85\xe7\x89\x88\xe5\x9b\xbd\xe9\x99\x85\xe7\x89\x88
'
4 Cache-Control: private, max-age=0
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Vary: Accept-Encoding
P3P: CP="NON UNI COM NAV STA LOC CURa DEVa PSAa PSDa OUR IND"
Set-Cookie: SRCHD=AF=NOFORM; domain=.bing.com; expires=Sat, 14-Nov-2020 08:43:04 GMT; path=/
Set-Cookie: SRCHUID=V=2&GUID=2F979C9C623D45839ABD12AC532F1FDC&dmnchg=1; domain=.bing.com; expires=Sat, 14-Nov-2020 08:43:04 GMT; path=/
Set-Cookie: SRCHUSR=DOB=20181114; domain=.bing.com; expires=Sat, 14-Nov-2020 08:43:04 GMT; path=/
Set-Cookie: _SS=SID=3C5C0AE95A0B6EFA29DF064E5B256F29; domain=.bing.com; path=/
X-MSEdge-Ref: Ref A: B40C4664EFC0492AB68074587A220624 Ref B: BJ1EDGE0219 Ref C: 2018-11-14T08:43:04Z
Set-Cookie: _EDGE_S=F=1&SID=3C5C0AE95A0B6EFA29DF064E5B256F29; path=/; httponly; domain=bing.com
Set-Cookie: _EDGE_V=1; path=/; httponly; expires=Mon, 09-Dec-2019 08:43:04 GMT; domain=bing.com
Set-Cookie: MUID=28962DA146236EF4189E2106470D6F86; path=/; expires=Mon, 09-Dec-2019 08:43:04 GMT; domain=bing.com
Set-Cookie: MUIDB=28962DA146236EF4189E2106470D6F86; path=/; httponly; expires=Mon, 09-Dec-2019 08:43:04 GMT
Date: Wed, 14 Nov 2018 08:43:04 GMT
Connection: close
5 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240 总结以上:
弄清楚urlopen和Request两个模块的不同使用。
urllib.parse模块
-
parse.urlencode(u) 编码
-
parse.unquote(u) 解码
该模块可以完成对url的编码和解码。
parse.urlencode({})的第一个参数要求的是一个字典或者二元组序列。将该序列进行编码。汉字的话采用UTF-8的格式,转化成%XX%XX%XX的形式。(6个字节)
先看一段代码,进行编码
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 14 16:56:58 2018
@author: DELL
"""
from urllib import parse
body = {'id':1,
'name':'tom',
'Sub':'语文',
'url':'http://www.magedu.com/python'}
u1 = parse.urlencode(body)
u2 = parse.urlencode({'url':'http://www.magedu.com/python',
'p_url':'http://www.magedu.com/python?id&name=张三'})
print(u1)
print(u2)实验结果是:每一个key和value用等号表示,items之间用&连接
runfile('C:/Users/DELL/Desktop/python/spyder_test2.py', wdir='C:/Users/DELL/Desktop/python')
id=1&name=tom&Sub=%E8%AF%AD%E6%96%87&url=http%3A%2F%2Fwww.magedu.com%2Fpython
url=http%3A%2F%2Fwww.magedu.com%2Fpython&p_url=http%3A%2F%2Fwww.magedu.com%2Fpython%3Fid%26name%3D%E5%BC%A0%E4%B8%89从运行结果来看:冒号,斜杠,&,等号,问号等符号全部被编码了,%之后的实际上是单个字节十六进制表示的值。
一般来说,URL地质部份,一般不需要中文路径,但是参数部分,无论是GET还是POST,提交的数据中,都有可能含有斜杠,等号,问号等符号,这些字符表示数据,不表示元字符。如果直接发给服务器端,就会导致接收方无法判断谁是元字符,谁是数据。为了安全,一般会将数据部分的字符做URL编码,这样就不会有歧义了。
总之,要看哪些需要编码,哪些已经编码,不再需要编码,再使用urlencode;需要注意的是urlencode()和encode()的区别
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 14 16:56:58 2018
@author: DELL
"""
from urllib import parse
u = parse.urlencode({'wd':'中'})
#后面的url就不需要加到encode里面再编码一次了
url="https://www.baidu.com/s?{}".format(u)
print(url)
print('中'.encode('utf-8'))
#########解码###############
print(parse.unquote(u))
print(parse.unquote(url))
结果:
runfile('C:/Users/DELL/Desktop/python/spyder_test2.py', wdir='C:/Users/DELL/Desktop/python')
https://www.baidu.com/s?wd=%E4%B8%AD
b'\xe4\xb8\xad'
wd=中
https://www.baidu.com/s?wd=中
提交方法method
GET:数据是通过URL传递的,也就是说数据实在HTTP报文的header部分
POST:数据是放在HTTP报文的body部分提交的
数据都是键值对的形式,多个参数之间使用&连接。如a=1&b=2
GET:连接必应搜索引擎,获取一个搜索URL的需求:实例用get方法获取以下界面的内容:
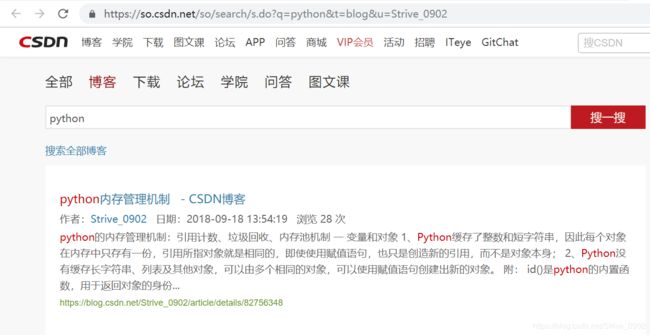
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 14 22:31:20 2018
@author: DELL
"""
from urllib.parse import urlencode
from urllib.request import Request,urlopen
u = parse.urlencode({'q':'python',
't':'blog',
'u':'Strive_0902'})
base_url="https://so.csdn.net/so/search/s.do"
url = "{}?{}".format(base_url,u)
print(url)
print(parse.unquote(url))
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
req = Request(url,headers={
'User-agent':ua
})
#动态的异步数据
with urlopen(req) as res:
with open(r'C:\Users\DELL\Desktop\python\get_url.html','wb+') as f:
f.write(res.read())
f.flush()
运行结果为
runfile('C:/Users/DELL/Desktop/python/spyder_test3.py', wdir='C:/Users/DELL/Desktop/python')
https://so.csdn.net/so/search/s.do?q=python&t=blog&u=Strive_0902
https://so.csdn.net/so/search/s.do?q=python&t=blog&u=Strive_0902还有本地生成的一个html文件
POST方法:测试网站:http://httpbin.org/,传递的内容在urlopen的data里面
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 15 10:13:43 2018
@author: DELL
"""
from urllib import parse
from urllib.request import Request,urlopen
import json
url = 'http://httpbin.org/post'
data = parse.urlencode({'name':'张三,@#¥/*',
'age':'6'
})
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
req = Request(url,headers = {'User-agent':ua})
#因为这里的data需要二进制,而我们前面的data是字符串,所以需要编码成二进制
with urlopen(url,data = data.encode()) as res:
text = res.read()
print(type(text))
d = json.loads(text)
print(d)
print(type(d))结果是:
runfile('C:/Users/DELL/Desktop/python/spyder_post.py', wdir='C:/Users/DELL/Desktop/python')
{'args': {}, 'data': '', 'files': {}, 'form': {'age': '6', 'name': '张三,@#¥/*'}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Content-Length': '59', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'Python-urllib/3.6'}, 'json': None, 'origin': '202.121.146.127', 'url': 'http://httpbin.org/post'}
处理json数据:python爬虫Ajax数据爬取
测试网站:豆瓣网站:https://movie.douban.com/ 右键打开检查之后一点更要刷新!!!
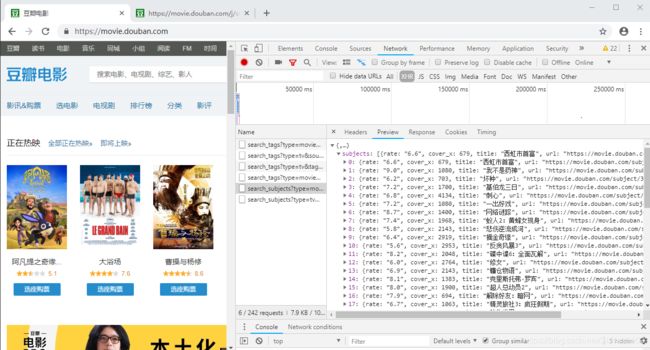
谷歌浏览器:右键——检查——network——XHR(XMLHttpReques)点击第五条就可以看到,我们需要的信息。右键可以复制link(https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit=10&page_start=10)在浏览器中打开该link显示的内容为:
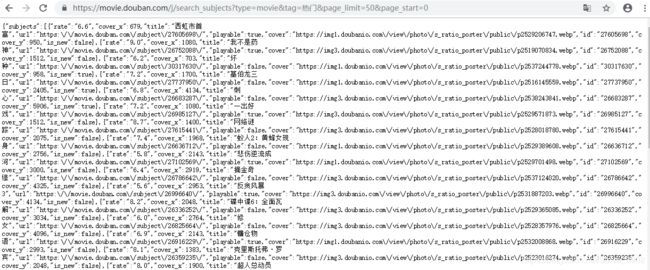
所以,我们可以用python脚本去爬去该链接对应的内容。下面写python脚本
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 15 11:07:00 2018
@author: DELL
"""
from urllib.parse import urlencode
from urllib.request import Request,urlopen
u = parse.urlencode({'type':'movie',
'tag':'热门',
'page_limit':10,
'page_start':10})
base_url='https://movie.douban.com/j/search_subjects'
url = "{}?{}".format(base_url,u)
print(url)
print(parse.unquote(url))
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
req = Request(url,headers={
'User-agent':ua
})
with urlopen(req) as res:
text = res.read()
print(type(text))
d = json.loads(text)
print(d)
print(len(d['subjects']))
print(type(d))结果是
https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=10&page_start=10
https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit=10&page_start=10
{'subjects': [{'rate': '5.6', 'cover_x': 2953, 'title': '反贪风暴3', 'url': 'https://movie.douban.com/subject/26996640/', 'playable': True, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2531887203.jpg', 'id': '26996640', 'cover_y': 4134, 'is_new': False}, {'rate': '8.2', 'cover_x': 2048, 'title': '碟中谍6:全面瓦解', 'url': 'https://movie.douban.com/subject/26336252/', 'playable': False, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2529365085.jpg', 'id': '26336252', 'cover_y': 3034, 'is_new': False}, {'rate': '5.9', 'cover_x': 2764, 'title': '修女', 'url': 'https://movie.douban.com/subject/26825664/', 'playable': False, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2528357976.jpg', 'id': '26825664', 'cover_y': 4096, 'is_new': False}, {'rate': '6.9', 'cover_x': 2143, 'title': '镰仓物语', 'url': 'https://movie.douban.com/subject/26916229/', 'playable': True, 'cover': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2532008868.jpg', 'id': '26916229', 'cover_y': 2993, 'is_new': False}, {'rate': '8.1', 'cover_x': 1383, 'title': '克里斯托弗·罗宾', 'url': 'https://movie.douban.com/subject/26359235/', 'playable': False, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2523016274.jpg', 'id': '26359235', 'cover_y': 2048, 'is_new': False}, {'rate': '8.0', 'cover_x': 1900, 'title': '超人总动员2', 'url': 'https://movie.douban.com/subject/25849049/', 'playable': True, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2522880251.jpg', 'id': '25849049', 'cover_y': 2663, 'is_new': False}, {'rate': '7.9', 'cover_x': 694, 'title': '解除好友:暗网', 'url': 'https://movie.douban.com/subject/26725678/', 'playable': False, 'cover': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2525020357.jpg', 'id': '26725678', 'cover_y': 1000, 'is_new': False}, {'rate': '6.7', 'cover_x': 1063, 'title': '精灵旅社3:疯狂假期', 'url': 'https://movie.douban.com/subject/26630714/', 'playable': True, 'cover': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2530591543.jpg', 'id': '26630714', 'cover_y': 1488, 'is_new': False}, {'rate': '7.3', 'cover_x': 2999, 'title': '动物世界', 'url': 'https://movie.douban.com/subject/26925317/', 'playable': True, 'cover': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2525528688.jpg', 'id': '26925317', 'cover_y': 4181, 'is_new': False}, {'rate': '6.5', 'cover_x': 1000, 'title': '阿尔法:狼伴归途', 'url': 'https://movie.douban.com/subject/26810318/', 'playable': True, 'cover': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2530871439.jpg', 'id': '26810318', 'cover_y': 1400, 'is_new': False}]}
10
HTTPS访问
HTTPS分为两种:信任的网站(百度)和不信任的网站(12306)。对于没有不可信任的HTTPS网站,怎么爬去它的页面信息。看一个例子,比如12306网站。没有使用CA认证。但是自己给自己颁发了证书。就是所谓的安装12306的根证书。所以如果针对这种不可信任的网站,需要导入ssl库。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 15 11:07:00 2018
@author: DELL
"""
from urllib.parse import urlencode
from urllib.request import Request,urlopen
import ssl
url_1 = 'https://www.baidu.com/' #信任的网站
url_2 = 'http://www.12306.cn/mormhweb/' #信任的网站
url='https://www.12306.cn/mormhweb/' #报SSL认证异常
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
req = Request(url,headers={
'User-agent':ua
})
context = ssl._create_unverified_context()
with urlopen(req,context = context) as res:
text = res.read()
print(type(text))
print(res._method)
print(res.geturl())结果如下
runfile('C:/Users/DELL/Desktop/python/spyder_ssl.py', wdir='C:/Users/DELL/Desktop/python')
GET
https://www.12306.cn/index/ 待续~