C/C++ 学习笔记
以下是从右到左开始计算的(函数参数都是从右边到左边开始滴哟)
cout << i << ", " << i--<< endl;
printf("%d, %d", j, j--);
汉字的 ASCII 码小于0。
1Kb等于1000b、1Mb等于1000Kb
fork()给子进程返回一个零值,而给父进程返回一个非零值。即:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回-1;
fork函数创建的子程序,从当前位置开始执行。
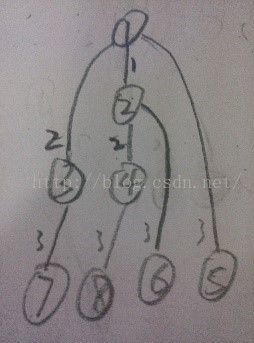
另外,三个连续的fork()如下:
fork();
fork();
fork();
进程产生如右图:总共产生8个进程。
无符号和有符号整数进行运算时,有符号整数会被提升为无符号整数。
如果下列的公式成立:84*148=B6A8。则采用的是____进制表示的。
解:
1、常规做法:假定数值是x进制的,则写出等式:(8x+4)*(x2+4x+8)=11x3+6x2+10x+8,化简得到(3x2+6x+2)*(x-12)=0,则x的非负整数解为x=12。
2、“启发式”做法:在十进制体系下,左侧个位乘积4*8=32;右侧个位为8,差32-8=24,从而进制必然是24的约数。只有C选项12是24的约数。
#pragma pack(2)
class A {
int i;
union U {
char tqh[13];
int i;
}u;
void func() { cout << "庚午步雲" << endl; }
typedef char* (*f)(void*);
enum{Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday} week;
}a;sizeof(a)的值是 22。
注意:
1. 这里 #pragma pack(2) 强制设定为 2 字节对齐;
2. 枚举类型的变量长度仅仅 enum 中一个元素的长度,即 sizeof(int)。
此外,还有:类的大小只与成员变量(非static数据成员变量)和虚函数指针有关,还要考虑到对齐。
sizeof结构体对界问题:
每个元素的起始偏移地址要能被其类型大小整除,结构体整体大小要能被结构体中最大数据类型整除。
*p++,后置 ++优先级高于解引用操作符 *,故先自加然后解引用,因为是后置++,故解引用的时候的地址为加加前的那个位置。
取余的函数定义 a%b = a - (a/b)*b,所以例如 -7%5 = -7 - (-1)*5 = -2
cin小数点后保留2位:
#include
cout << setiosflags(ios::fixed)<< setprecision(2)<< x<< endl; 利用字符流完成整型和字符串转换:
#include
// string 到 int
stringstream ss;
ss << str;
int n;
ss >> n;
// int 到 string
ss << n;// 假如正数前面有个正号,会自动去掉正号
string numStr = ss.str(); 联合,如果没有告诉是大端还是小端,则应该考虑两种情况。
采用 Little-endian 模式的 CPU 对操作数的存放方式是从低字节到高字节,而 Big-endian 模式对操作数的存放方式是从高字节到低字节。Intel 系列微处理器采用的是 Little-endian 模式。
eg:请写一个 C 函数,若处理器是 Big_endian 的,则返回 0;若是 Little_endian 的,则返回 1
int checkCPU() {
{
union w {
int a;
char b;
} c;
c.a = 1;
return (c.b == 1);
}
}把一个整数减去1,再和原整数做与运算,会把该整数最右边一个1变成0。那么一个整数的二进制表示中有多少个1,就可以进行多少次这样的操作了。同样,如果想判断一个数是不是2的整数次方,把这个整数减去1后再和它做与运算,这个整数中唯一的1就会变为0。
一个由 C/C++ 编译的程序占用的内存分为以下几个部分:
1、 栈区:由编译器自动分配和释放,存放函数的参数值、局部变量的值等。
2、 堆区:一般由程序员分配和释放,若程序员不释放,程序结束时可能由OS回收。
3、 全局区(静态区):全局变量和静态变量的存储都放在这个区,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由OS释放。
4、 文字常量区:常量字符串放在这里。程序结束后由OS释放。
5、 程序代码区:存放程序的二进制代码。(这个区只读,程序员不可修改)
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域,Windows下是1M吧。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈由系统自动分配,速度较快。但程序员是无法控制的。堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
静态分配是指在编译阶段就能确定大小,由编译器进行分配,堆不可以进行静态分配,堆的申请都是在执行过程中进行的。
堆和栈都可以动态分配。
全局变量一些知识:
1) 全局变量过多会占用更多的内存(因为其生命期长)
2) 提高了耦合性,牵一发而动全身,时间久了,代码长了,就不知道全局变量被哪些函数改过。
3) 提高了模块间的耦合性,对后期维护、拓展和复用都带来极大影响。
4) 使用全局变量程序运行时速度会更快一些(因为内存不需要再分配)
5) 便于传递参数。
malloc free 和 new delete
区别为:
1. malloc/free是标准库函数,new/delete是运算符。
2. new/delete返回的是所分配类型变量(对象)的指针,malloc/free返回的是void指针。
3. 数组的时候int *p=(int*)malloc(10*sizeof(int));释放的时候free(p)即可;这是因为编译器对malloc做了一些特殊的处理,以保证可以正确释放内存。而当int*p=newint[10];释放的时候应为delete[]p,注意[]的作用说明释放的是一个数组的内存,如果delete p则只是释放的p[0],其余9个int的内存没有释放;因为当指明为[]的时候,编译器实际上是做了一个循环来释放这个数组的所有内存。
4. 在类和对象的时候会有很大区别。在使用malloc和free来处理动态内存的时候,仅仅是释放了这个对象所占的内存,而不会调用这个对象的析构函数;使用new和delete就可以既释放对象的内存的同时,调用这个对象的析构函数。
共同之处:
都是只把指针所指向的内存释放掉了,并没有把指针本身干掉。在free和delete之后,还需要把指针置为空,即p =NULL,否则指针指向的内存空间虽然释放了,但指针p的值还是记录的那块地址,该地址对应的内存是垃圾,p就成了“野指针”。同样会使人认为p是个合法的指针,如果程序较长,我们通常在使用一个指针前会检查p!=NULL,这样就起不到作用了。此时如果再释放p指向的空间,编译器就会报错,因为释放一个已经被释放过的空间是不合法的。而将其置为NULL之后再重复释放就不会产生问题,因为delete一个0指针是安全的。
在这里关于指针和动态申请的内存空间总结如下:
1. 指针消亡了,并不表示它指示的动态内存会自动释放;
2. 动态内存释放掉了,如果这个内存是一个动态对象,则并不表示一定会调用这个对象的析构函数;
3. 动态内存释放掉了,并且调用了析构函数,并不表示指针会消亡或者自动变成了NULL。
设fp已定义,执行语句fp=fopen("file","w");后,以下针对文本文件file操作叙述的选项错误的是:
正确答案: A C D
A.可以随意读和写
B.只能写不能读
C.可以在原有内容后追加写
D.写操作结束后可以从头开始读
(用“w”打开的文件只能向该文件写入。若打开的文件不存在,则以指定的文件名建立该文件,若打开的文件已经存在,则将该文件删去,重建一个新文件)
x是一个行列数均为1000二维数组,下面代码效率执行最高的是()
正确答案: D
A. for(int j=0;j<1000;j++) for(int i=0;i<1000;i++) x[i][j]+=x[j][i];
B. for(int i=0;i<1000;j++) for(int j=0;j<1000;j++) x[i][j]+=x[j][i];
C. for(int i=0;i<1000;j++) for(int j=0;j<1000;j++) x[j][i]+=x[j][i];
D. for(int i=0;i<1000;i++) for(int j=0;j<1000;j++) x[i][j]+=x[i][j];
主要是考察了CPU cache的预取操作,数组x[1000][1000]在内存中,是按行进行存储。D选项外部循环是按行进行,因此操作第i行时,会将第i行后面的部分数预取到cache中,操作速度最快。
ABC选项其中都有跳列的操作,不能发挥cache的预取操作功能。
如下代码:
int main() {
const int i = 0;
int *j = (int *) &i;
*j = 1;
printf("%d,%d", i, *j);
return 0;
}在 C 语言中输出结果是 1, 1,所以 C 语言可以通过指针间接修改 const 变量的值。
我们重点要说的是在 C++ 中输出结构是 0, 1。 原因是:
C++中的常量折叠:指 const 变量(即常量)值放在编译器的符号表中,计算时编译器直接从表中取值,省去了访问内存的时间,从而达到了优化。编译器只对 const 变量的值读取一次。所以打印 i 是 0 。
但是,如果加上 volatile 能做到改变 C++ 中 const 变量的值,因为,volatile 告诉编译器不要去优化这个变量,所以,常量 i 就会每次都从内存读取。
struct st {
};
sizeof(st)是1
struct ss {
int status;
short * pdata;
char errstr[32];
};
ss st[16];
char *p = (char*)(st[2].errstr+32);
cout << (p-(char*)(st));
答案为 120。结构体的大小为40字节,p指向的是前三个结构体的末尾,所以答案为3×40 = 120
const int N = 10;
const int M = 2;
int *a = new int[N];
for(int i=0; i < N; i++)
a[i] = (0 == i%2)?(i+2):(i+0);// 2 1 4 3 6 5 8 7 10 9
int (*b)[N/M] = (int(*)[N/M])a;// 把这个以为数组转换成指针数组
for(int i=0; i < M; i++)
for(int j=0; j < N/M; j++)
cout << b[i][j];
结果是:21436587109
C语言: char a = 'a';sizeof(char) = 1 sizeof(a) = 1 sizeof('a') = 4
C++语言: char a = 'a';sizeof(char) = 1 sizeof(a) = 1 sizeof('a') = 1
字符型变量是1字节这个没错,奇怪就奇怪在C语言认为'a'是4字节,而C++语言认为'a'是1字节。
原因如下:
C99标准的规定,'a'叫做整型字符常量(integer character constant),被看成是int型,所以在32位机器上占4字节。
ISO C++标准规定,'a'叫做字符字面量(character literal),被看成是char型,所以占1字节