Spark的Graphx学习笔记--Pregel
1、PregelAPI
图本质上是一种递归的数据结构,其顶点的属性值依赖于其邻接顶点,而其邻接顶点属性又依赖于其邻接顶点,许多重要的图算法通过迭代计算每个顶点的属性直到到达定点条件,这些迭代的图算法被抽象成一系列图并行操作。
2、Pregel的计算模型
主要分为三个函数:
1、vertexProgram函数
2、sendMessage函数
3、messageCombiner函数
在进行了解之前,先对相关知识进行粗略的了解:
知识点1:在第一次迭代的时候,所有的顶点都会接收到initialMsg消息,在次轮迭代的时候,如果顶点没有接收到消息,verteProgram就不会被调用。
知识点2:对相关参数的了解(详细看黑体部分)
VD:顶点的数据类型。
ED:边的数据类型
A:Pregel message的类型。
graph:输入的图
initialMsg:在第一次迭代的时候顶点收到的消息。
maxIterations:迭代的次数
vprog:用户定义的顶点程序运行在每一个顶点中,负责接收进来的信息,和计算新的顶点值。在第一次迭代的时候,所有的顶点程序将会被默认的defaultMessage调用,在次轮迭代中,顶点程序只有接收到message才会被调用。
sendMsg:用户提供的函数,应用于边缘顶点在当前迭代中接收message
mergeMsg:用户提供定义的函数,将两个类型为A的message合并为一个类型为A的message。(thisfunction must be commutative and associative and ideally the size of A shouldnot increase)
其中用到的Graph类的API
mapReduceTriplets():计算每个节点的相邻的边缘和顶点的值,用户定义的mapFunc函数会在图的每一条边调用,产生0或者多个message发送到这条边两个顶点其中一个当中,reduceFunc函数用来合并map阶段的输出到每个节点。
3、实例
以下通过spark1.0.1上的最短路径来举个例子.
源码的路径为graphx包的lib文件夹内。
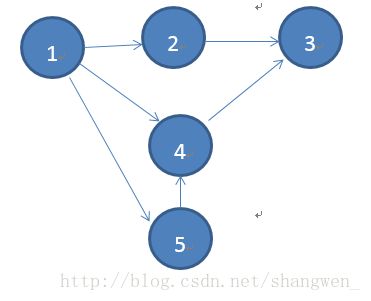
以下为计算最短路径的基本的图信息(图为有向图)。
主要函数:
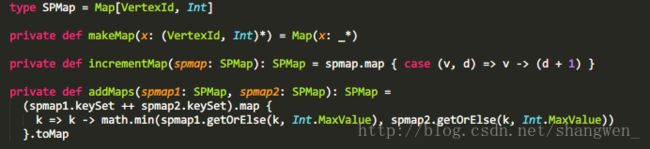
SPMap:定义一个Map[VertexId,Int]类型的Map函数,别名为SPMap,函数的属性Key为VertexId类型,其实也就是scala中的Long类型,它在图中的别名是VertexId,还有Int类型的路径的长度。
makeMap函数:用来初始化图的属性信息。
incrementMap函数:主要用于将自身的属性值(即源顶点属性值)中路径的长度加1,然后和目标定点的属性值比较,下面会详细描述。
addMaps函数:比较源顶点属性和发送信息过来顶点的属性取最小值。
下面是ShortestPaths.scala的run函数:
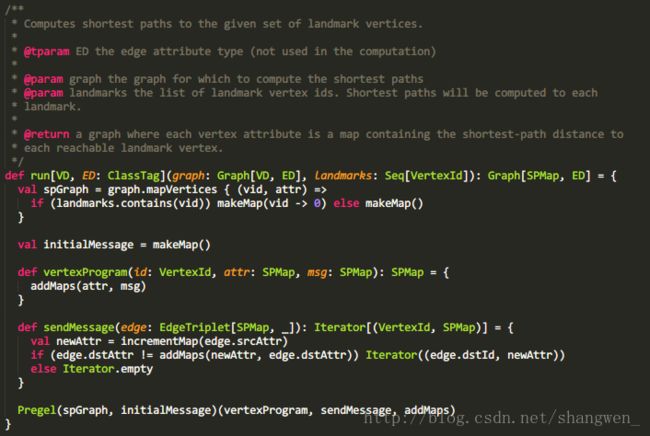
run函数传入的参数为:已经构造好的图graph和landmarks
landmarks:是我们要求最短路径的顶点的集合。
初始化节点属性:
程序的第一步初始化图的节点的属性,为了方便举例,假设我给定的landmarks的集合为{1}。
注意:mapVertices函数是图的基本常用函数之一,它作用于graph中的每一个顶点。
在Graph类中,它是这么定义的:

程序的API上的定义为:通过map函数转换图中每个节点的属性值,VD2代表的是新的数据类型。(嗯,我英文不是很好,就大概这个意思哈)。
根据程序的意思,初始化图,将landmarks中的顶点初始化为Map(1-> 0),即自身到自身的距离为0,其余的顶点属性初始化为Map()。
接下来定义一个initMessage它的值为Map(),作用是在Pregel第一次运行的时候,所有图中的顶点都会接收到initMessage。
在接下来定义了一个vertexProgramProgram函数和sendMessage函数。
在这里,vertexProgram函数调用了addMaps函数,通过程序显而易见的是:两个消息来的时候,取它们当中路径的最小值。其实在下面也就是相当于messageCombiner函数。
SendMessage函数的原理是:
1、通过incrementMap函数把源顶点的距离属性加1得到新的属性值newAttr。
2、新的属性newAttr和原来的属性比较取最小值,如果新的属性是最小的,则通过Iterator发送该信息到目标顶点的函数。该信息的结构为(dstId,newAttr),否则不发送。
最后把以上信息传递给Pregel去执行。
执行的流程简图如下:
1、初始化图的属性值
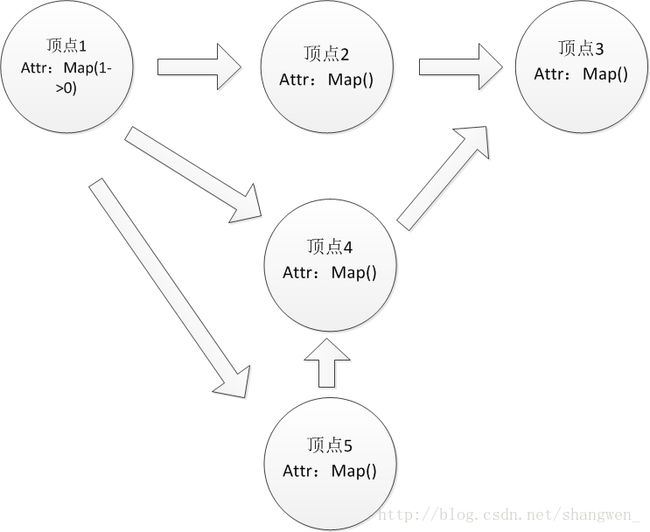
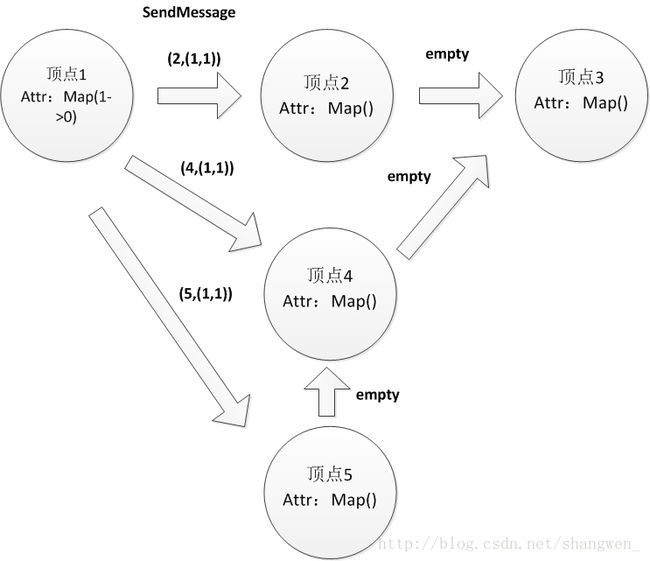
2、调用sendMessage函数:
调用sendMessage函数,包含出度的顶点才能发送消息。
首先第一步,假设从顶点1开始:
步骤和上面说的一样,顶点1的距离属性值加1即从(1,0)变为(1,1),和顶点2的属性值比较(具体看代码吧),得出顶点1的属性值最小,满足发送的条件,发送消息Iterator(2,(1,1))。
顶点4、5类似,顶点2、4、5由于他们之间的属性值为Map(),所以不满足发送条件,顶点3没有出度,所以不发送消息。
点1->2:(2,(1,1))
点1->4:(4,(1,1))
…
点2->3:empty
….
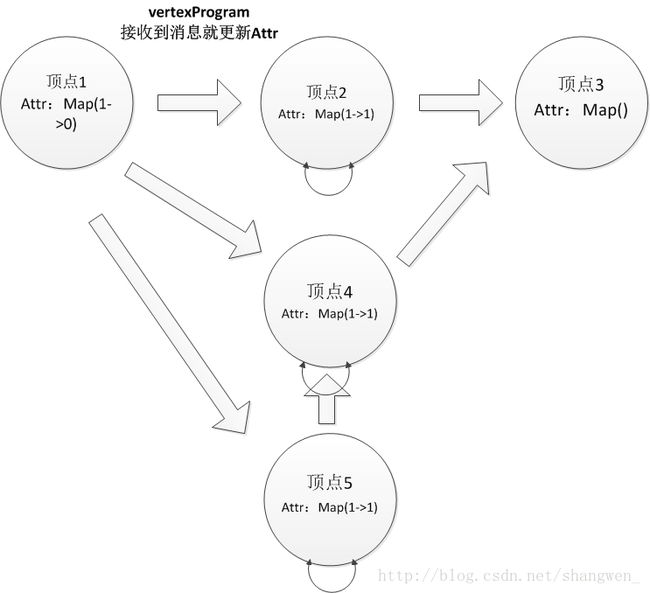
3、调用vertexProgram函数:
在看API文档或者代码可以知道,vertexProgram在第一次在初始化的时候,会在所有顶点上运行,之后,只有接收到消息的顶点才会运行vertexProgram,所以接下来容易可以知道,只有顶点2,4,5运行程序,并改变他们自身的属性值。
4、然后类似的重复步骤2、3直到图中的message为0,或者 满足我们给定的迭代次数,
嗯,怎么知道会有迭代次数呢?往下看
接下来就简略的看看Pregel的代码,看看他是怎么运行的,由于我还在初步的学习阶段,仅供参考,如果有好的理解可以交流交流。
从传入的参数可以知道,我们可以通过maxIterations指定迭代次数,mergeMsg函数也就是刚才所说的addMaps函数。
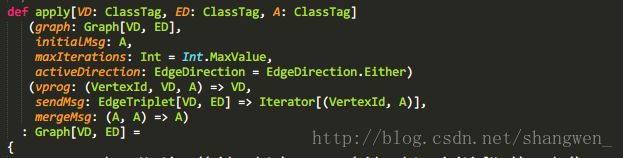
接下来就是主要的实现逻辑:
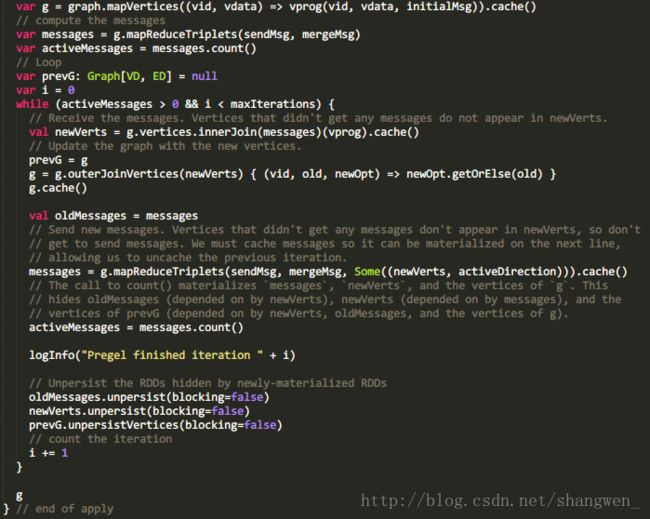
看了第一句,通过调用graph的mapVertices函数就初始化所有图的属性信息,然后调用mapReduceTriplets函数,它返回一个VertexRDD[A]类型的RDD,mapReduceTriplets也是常用的函数之一。
注意:由于mapReduceTriplets里面的代码个人觉得过于复杂,看了很久没看懂,如果有兴趣希望可以交流一下。
接下来就是我个人的假设阶段了:
通过注释可以看出
message应该就是接收到消息的顶点,那activeMessages就是顶点的数量了。
接下来通过迭代
通过图的所有顶点和接收到消息的顶点进行内连接,然后运行顶点的vertexProgram函数,即刚才我们所说的只有接受到消息的顶点才会运行vertexProgram函数。得到新的newVerts集合。
图和newVerts进行outerJoinVertices把newVerts的新信息update到图中。
然后继续发送新的消息。
判断activeMessages 和 指定的迭代次数
继续迭代直到activeMessages为零和满足设定的迭代次数值为止。
本文的基本介绍就到这里了,如果有兴趣可以大家一起探讨探讨。