随机森林二分类建模
由于对r相对比较熟悉,先用的r处理数据,但是跑模型太慢,因此用py跑的模型。用了逻辑回归和随机森林,显然后者要好很多,因为维度一千多个,而且逻辑回归要涉及到更详细的特征处理,第一部分是r代码,第二部分是py
一 r code
rm(list=ls())
library(caret)train_x<-read.csv("train_x.csv",header=T)#读取x
train_y<-read.csv("train_y.csv",header=T)#读取y
train<-merge(train_x,train_y,by.x="uid",by.y="uid")#合并x和y
rep<-train[train$y==0,]
for (i in 1:6){
rep<-rbind(rep,train[train$y==0,])
}#生成向上样本
train_add<-rbind(train,rep)#形成新添加7次负样本总数的样本
train_add_1<-train_add[,1]#存放合并以及增加样本后的uid
train_add_y<-train_add[,c(1,1140)]#存放合并以及增加样本后的y
names(train_add_y)<-c("uid","y")
train_add_x<-train_add[,-c(1,1140)]#提取需要进行清洗的变量(去掉uid和Y值)
zerovar <- nearZeroVar(train_add_x)#找出近似常量的变量
newdata1 <- train_add_x[,-zerovar]#去掉近似常量的变量
descrCorr <- cor(newdata1)#求出相关矩阵
highCorr <- findCorrelation(descrCorr, 0.90)#找出相关性强的变量
newdata2 <- newdata1[, -highCorr]#删除相关性强的变量
comboInfo = findLinearCombos(newdata2)#找出线性相关性强的变量
newdata2=newdata2[, -comboInfo$remove]#删除相关性强的变量
Process <- preProcess(newdata2)#数据预处理步骤(标准化,缺失值处理)
newdata3 = predict(Process, newdata2)
train_add_haveuid<-cbind(train_add_1,newdata3)
names(train_add_haveuid)[1]<-"uid"
train1<-merge(train_add_haveuid,train_add_y,by.x="uid",by.y="uid")#合并数据
names(train1)
write.csv("清洗好的训练数据.csv")
二 py code
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 09 13:23:36 2015
@author: Tanya_girl
"""
import sklearn
import os
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
os.getcwd()
os.chdir("D:\\competitions\\datacastle\\p2p")
train1=pd.read_csv("ok_train_without2.csv")
test1=pd.read_csv("ok_test_without2.csv")
y=train1['y']
x=train1.ix[:,:619]
x1=test1.ix[:,:619]
y1=test1['y']
print x.head()
clf = RandomForestClassifier(n_jobs=8)
s=clf.fit(x, y)
clf = LogisticRegression()
s1=clf.fit(x, y)
y_rd_pred = s.predict(x1)
y_lg_pred=s1.predict(x1)
tab_rd=pd.crosstab(y1,y_rd_pred,rownames=['actual'],colnames=['preds'])
tab_lg=pd.crosstab(y1,y_lg_pred,rownames=['actual'],colnames=['preds'])
print tab_rd,tab_lg
putin_x_filter=pd.read_csv("putin_x_filter1.csv") #读取测试数据
putin_rd_pred=s.predict(putin_x_filter)#获得随机森林预测结果
putin_lg_pred=s1.predict(putin_x_filter)#获得逻辑回归预测结果
result = pd.DataFrame(putin_lg_pred)#逻辑回归结果转化成pandas数据框
result.to_csv("predictions.csv", index=False)#输出预测结果到predictions文件
result = pd.DataFrame(putin_rd_pred)#逻辑回归结果转化成pandas数据框
result.to_csv("predictions_rd.csv", index=False)#输出预测结果到predictions_rd文件
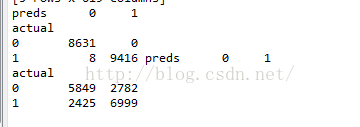
这里截取了两次交叉验证结果,第一个为随机森林,明显要比逻辑回归好很多。这里强调不是逻辑回归不好,而是应该对特征工程要求更加严格。