一文读懂数据库最新技术趋势:TDSQL带你深度纵览VLDB 2019

一年一度的数据库领域顶级会议 VLDB 2019 于当地时间8月26日-8月30日在美国加利福尼亚州洛杉矶召开。来自学术界和工业界的参会者们汇聚一堂,共襄盛会,探讨交流数据库领域最前沿的技术和发展方向。

在本届大会上,腾讯公司与中国人民大学、新加坡国立大学合作,投中 Industry Paper 两篇。其中 TDSQL 团队的论文工作“A Lightweight and Efficient Temporal Database Management System in TDSQL”,介绍了基于分布式事务数据库 TDSQL扩展而来的全时态数据库系统T-TDSQL。该系统在保证OLTP性能的前提下,提供了轻量级的全时态数据管理功能和全时态数据的事务处理能力、以及集当前态数据于生产系统集历史态数据于分析型系统的集群架构,构成了全时态数据的完备解决方案。(论文原文)
腾讯 TDSQL 团队对本届大会的论文进行了汇总归纳,萃取精华与读者一同分享。
VLDB 简介
VLDB会议的全称是Very Large Data Bases Conferences,由 VLDB Endowment 主办,来自全球各地的数据库相关领域研究人员、供应商、参与者、应用开发者等共同参与和关注的国际重大学术会议。其目的在于促进和交换全世界范围内的数据库及其相关领域中的前沿学术工作。VLDB 与 ACM 主办的 SIGMOD、IEEE 主办的 ICDE 合称数据库领域三大顶级会议。而在发表论文难度和受关注程度上,VLDB 与 SIGMOD 可谓并驾齐驱。
值得一提的是,与多数计算机领域学术会议一年一次或两次的投稿周期不同,VLDB Endowment自 2008 年以来建立了 PVLDB(The Proceedings of the VLDB),此后以期刊的形式评审论文,每一个月为一次投稿周期,即每个月的1号为上个月投稿周期的截止时间,一年有12次投稿机会。而审稿周期较传统期刊更短,论文作者一般会在一个半月到两个月的时间内收到评审意见反馈。在每年的 VLDB 会议上,一年以来被 PVLDB 收录的论文将进行集中报告。
VLDB 2019
本年度的 VLDB 会议已是第 45 届会议,于8月26日至30日在美国西海岸的著名城市洛杉矶举办。大会议程包括3个主题演讲 (Keynote)、28个学术论文报告分会 (Research Session)、4个工业界论文报告分会 (Industry Session)、2个工业界邀请演讲 (Invited Industry Talks)、2个系统展示论坛 (Demo Session)、7个教程 (Tutorial),以及博士生论坛 (PhD Workshop) 和多个子研讨会 (Workshop)等。共历时5天,其中首尾两天是各个Workshop,正会3天。

今年一共有 128 篇 Research Paper,22 篇 Industry Paper,以及 48 篇 Demo Paper 入选。与去年相比,收录的 Research Paper 和 Demo Paper 数量保持基本稳定,而 Industry Paper 有了显著的提升,从去年的12篇增加到今年的22篇。从投稿数量与录用率来看,Research Paper投稿677篇,录用率18.9%,Industry Paper为72/30.6%,Demo Paper为127/37.8%。与去年相比,Research Paper的投稿数量略有下降,录用率则基本持平。
从工业界论文的收录数量增加可以看出,今年的 VLDB 会议学术界和工业界合作交流趋势进一步增强。而且除了 Industry Paper 以外,在 Research Paper 中也有许多工作是由企业或企业与高校联合完成的,例如 Google、Microsoft、IBM 等均有多篇 Research Paper 入选。大会的程序委员会中也能见到诸多业界人士担任分会主席或审稿人。
国内方面,今年由大陆高校(不含港澳台)和企业主导或参与的 Research Paper 共有 27 篇,数量上与去年相比略有提升,其中清华大学、浙江大学等高校均发表了多篇论文。来自大陆高校的论文中,最主要的研究方向集中在图数据和机器学习,其中有 7 篇论文与图数据相关。从往年大陆高校在 VLDB、SIGMOD 等数据库会议的论文发表情况来看,图数据一直是华人学者比较强势的研究方向。此外,在查询优化、隐私保护、空间数据、众包、区块链等主题上,国内高校也均有涉及。国内业界对于数据库学术会议的参与度进一步提高,腾讯、华为等国内企业在本届会议上均有论文发表,研究方向主要集中在 RDBMS 和分布式系统。

在本次VLDB会议上,腾讯公司也设立了展台,欢迎各位与会嘉宾、专家莅临交流。
接下来,本文主要从论文分布和技术发展动向对本届 VLDB 论文进行概览。
论文总体分布情况
为了便于统一安排论文报告分会的时间长度,本届大会将论文粗略地按照研究方向均分为了28个 Research Session 和4个 Industry Session,每个 Session 有4-5篇论文进行报告。
由于论文的研究方向分布不均衡,热门的方向会安排多个 Session,例如事务处理、查询优化、分布式系统和图数据,而论文数量较少的不同方向可能混杂在同一个 Session 中,因此各 Session 之间的界限和层级关系并不太清晰。
我们阅读了全部论文的内容,在 Session 划分的基础上,根据每篇论文的研究方向以及针对的数据类型,将论文进行了更加细致清晰的分类,便于大家了解各个领域的研究热度。

图1. VLDB 2019 各领域论文分布

图2. VLDB 2018 各领域论文分布
因为存在一篇论文涉及多个领域的情况,因此图1中各个领域论文的数量之和大于了总论文数量。从图1的分布情况可以看出,关系型数据库(RDBMS)的研究仍然是主流,但总体数量上比去年(见图2)有所减少(今年34,去年42),占总论文数量的约1/4;其次是关于图数据和图数据库系统的研究,相关论文涉及了大规模数据图上的子图匹配、社团发现、带约束的最短路径查询等经典算法问题,以及分布式环境下的图分割等问题。除了关系数据模型的统治地位不可撼动之外,近年来图数据模型也逐渐被应用于实际业务中。而无论是关系型数据、图数据或是其他数据类型,查询执行和查询优化始终是性能优化的核心问题。随着移动互联网、物联网近年来的快速发展,不断催生了依赖于时空信息且实时性强的应用,因而时空数据和流数据的相关论文在本届会议上也占据了一席之地。此外,机器学习与数据库逐渐联系紧密,也有一些论文尝试使用机器学习算法来优化查询算法。
RDBMS 中各子领域论文分布情况
在与RDBMS相关的论文中,我们进一步按照其涉及的子领域进行细分,如图3所示。本届会议上有关事务处理的论文数量与去年(见图4)相比有明显增加,分布式事务处理既是难点也是热点。而查询优化、存储优化、缓存优化这些与性能密切相关的主题始终是数据库领域研究的核心。此外,研究者们逐渐意识到如何促进用户更方便直观地访问数据库是一个需要解决的重要问题,学术界将其定义为数据可用性(Data Usability)问题,因而近年来也有不少论文围绕这一问题研究了交互式访问接口、数据可视化等技术。
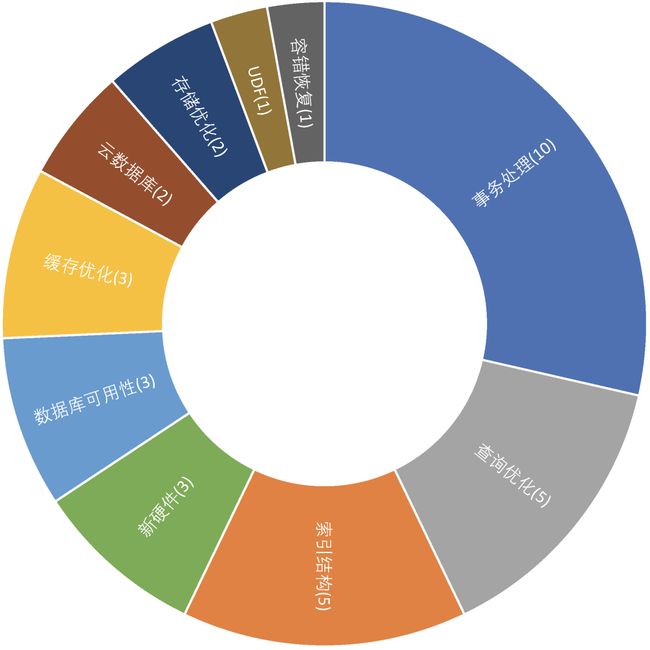
图3. VLDB 2019 RDBMS子领域论文分布
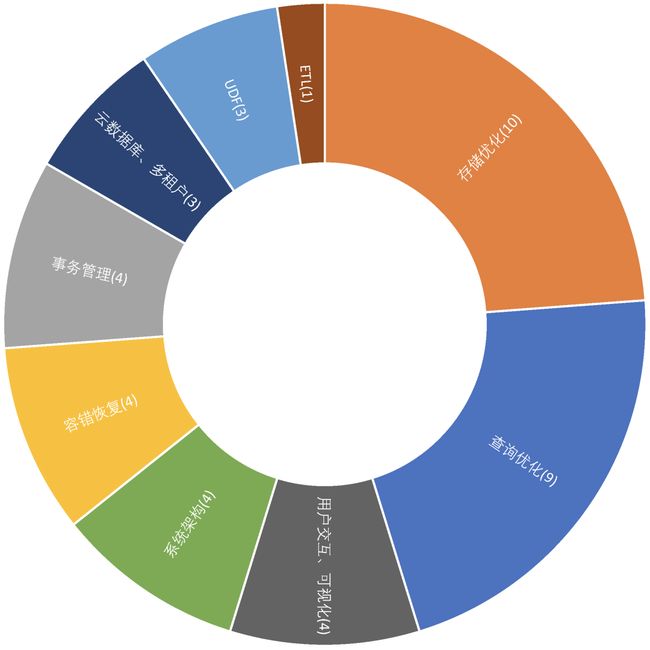
图4. VLDB 2018 RDBMS子领域论文分布
来自工业界的论文
工业界的论文来自 Google、Microsoft、IBM、Amazon、Facebook、SAP、eBay,以及国内的腾讯、华为等企业。除了 20 篇 Industry Paper 之外,根据我们的统计,在 Research Paper 中由企业独立完成或主导完成的论文有 11 篇,企业与高校合作的论文有 17 篇,占到 Research Paper 的 1/5;而 Demo Paper 中,也有 14 篇企业主导或参与的论文。由此可见工业界在数据库研究中参与度之高,企业与高校的合作日益密切。明显感到与学术界论文的区别是,工业界的论文更加注重系统实现和业务落地,而学术界论文则侧重于某个技术难点或者说算法问题的攻关。两者的优势结合则更有可能产出高质量的研究成果。
数据库技术发展动向
我们从本届 VLDB 论文中尝试观察总结数据库技术发展的新动向,抛砖引玉,期待与读者共同交流。如下是本届大会论文讨论到的一些重要话题。
分布式事务处理
随着摩尔定律的停滞失效,单机存储和计算能力增长遇到了瓶颈,现代数据库系统也朝着分布式多机集群发展,而其中遇到的最大的技术挑战即是分布式事务处理。如何保持分布式数据的一致性,事务隔离性不同级别的高效实现,都有待进一步深入研究。在本届 VLDB 中,事务处理的相关论文数量也有了明显增加。
例如论文“Adaptive Optimistic Concurrency Control for Heterogeneous Workloads”提出了一个简单有效的AOCC(自适应乐观并发控制)框架。根据查询读取的记录数,以及涉及更新操作的并发事务的写大小,AOCC自适应地选择合适的Validation 策略来降低开销,从而在不牺牲可串行化的前提下提升异质负荷的性能。论文“Improving Optimistic Concurrency Control Through Transaction Batching and Operation Reordering”则通过事务的批量执行和操作的重排序来提升OCC性能。恰巧,TDSQL的第二代事务处理机制,也是基于OCC机制,期待能有机会和大家深入进行探讨。
论文“SLOG: Serializable, Low-latency, Geo-replicated Transactions” 指出,现有的支持异地备援(Geo-replicated)的数据库通常需要在三个方面做取舍:(1)严格可串行化,(2)低延迟写入,(3)高事务处理吞吐量。该论文提出的SLOG系统利用了物理分区的局部性特征,能够同时满足以上三个要求。
在事务处理中,数据的故障恢复机制是很复杂的一项。传统的数据库实现通常需要维护WAL(Write Ahead Log)和数据本身的持久化存储,而且恢复算法渗透到了系统的各个模块,即数据库的各个模块在设计和实现时都需要考虑恢复功能的正确性,以保持事务的原子性。论文“FineLine: Log-structured Transactional Storage and Recovery” 中提出了FineLine——一个事务存储和恢复机制,舍弃了传统WAL,将所有需要持久化的数据存储到一个单一的数据结构,达到了数据库的持久化部分和内存中数据之间的设计解耦。
区块链技术 & Best Paper Award
区块链也是当下的热门话题之一,本届 VLDB 增加了一个关于区块链的单独 Session,共有 4 篇论文入围。值得一提的是,本届 VLDB 的 Best Paper Award 颁予了论文“Fine-Grained, Secure and Efficient Data Provenance on Blockchain Systems”。
这篇最佳论文的研究动机是,区块链系统还没有一个方便的方法来追溯数据的起源和变迁(Lineage,血统),只能依靠回放事务来重现过去的状态,这种方式适用于大规模的线下分析,但是不适合线上的事务处理系统。论文给出一个简单的例子:账户A给B转账,要求近期账户B的每日余额位于某一阈值以上,才可转账,现有系统需要重放近期B账户每天的交易,才能作出转账的决策。为了解决这样的问题,该论文提出了LineageChain系统,能够做到细粒度、安全高效地回溯区块链数据。LineageChain基于Hyperledger实现,底层存储为ForkBase (同一团队研发的面向区块链的存储系统,论文发表于VLDB 2018,“ForkBase: An Efficient Storage Engine for Blockchain and Forkable Applications”)。论文提出了一种新型的索引,针对区块链数据起源和变迁的查询作出优化。在线交易进行时,LineageChain能够精细、安全地保留下数据的变迁,并且对外提供简单的接口来访问这些数据变迁。
这篇论文提及“The management of that history, also known as data provenance or lineage, has been studied extensively in database systems”,其实,这是对于历史数据的一种管理理念,其核心是认为“历史数据具有价值”。这一理念,使得数据处理系统的数据处理疆域扩展,延伸到了历史数据的存储、管理和计算领域,非常有意义。作为“Best Paper”,该文有许多值得我们学习之处。而异曲同工的是,腾讯TDSQL在本届VLDB投中的《A Lightweight and Efficient Temporal Database Management System in TDSQL》一文,系统地阐述了腾讯TDSQL对于历史数据管理的完备方案和主要技术:从数据生命周期到全时态数据模型的建立、从事务处理到分布式系统的全局读一致,从查询优化到索引建立,从事务型生产系统到分析历史数据的分析型集群的数据无损、性能无损的体系结构的一体化构建,表明了腾讯公司TDSQL系统处理历史数据的完备性、先进性,以及技术的前瞻性。
无独有偶,AWS在2018年底发布的QLDB [Quantum Ledger Database (量子账本数据库) ],也意在解决历史态数据的存储、管理和计算。详情可参考《论亚马逊QLDB与腾讯TDSQL对历史数据的管理和计算》。
新硬件
新的存储硬件和计算硬件,例如NVM、SSD、NUMA,SIMD、多核CPU、GPU、FPGA等,为数据库性能的scale up带来了新的机会。如何充分利用新硬件的优势来提高数据库性能也是近年来的研究热点之一。本届VLDB有多达9篇论文涉及该方向,提供了使用GPU、SIMD加速RDBMS或者机器学习平台的并行计算能力,使用NUMA实现分布式数据库的高可用数据复制方案等新技术思路。
机器学习平台
机器学习、深度学习作为时下最为火热的研究领域,也受到了数据库学者的广泛关注。机器学习、深度学习算法通常是计算密集型任务,而且在实际应用中训练数据通常也远超单机所能承受的数据规模,因此如何利用大数据分布式存储与计算能力,为用户提供一站式的机器学习和深度学习平台服务,是两者的契合点。一个明显的体现是最近三年来的数据库领域会议如 VLDB、SIGMOD 增加了机器学习相关的 Track。
使用机器学习算法优化DBMS性能
这是机器学习与数据库技术的另一个结合点。例如论文“Towards a Learning Optimizer for Shared Clouds”研究了在多租户云数据库环境下,使用历史查询的执行统计数据进行训练学习,来预估未来查询的中间结果基数大小,从而指导生成更优的查询计划。此外,近两年的VLDB、SIGMOD也有使用机器学习模型来优化索引结构、存储、参数自动调优的相关研究工作。
图数据库与图计算平台
相比于关系表结构,图模型更能灵活地表示事物实体之间的关联关系。随着知识图谱的普及和应用,对图数据的研究在数据库领域占据了一席之地。但与关系表的Lookup、Scan、Join等基本操作不同,图的各种算法操作种类繁多,而且其中很多算法复杂度较高。大规模图数据的存储、查询和各种分析计算,成为了新的技术难点。相关的研究内容有图数据库和图分析计算平台的构建。
以上介绍了这么多,大家对本届VLDB是不是有了更多的了解呢?欢迎与我们交流感想与思考。在后续的文章中,他二哥也会继续为大家带来更多的现场报道和技术分享,期待大家继续关注今年VLDB的动态哦!
作者简介:
韩硕,2014年于北京邮电大学获得工学学士学位,2019年于北京大学获得理学博士学位。博士期间的主要研究方向为图数据管理和知识图谱。毕业后加入腾讯公司从事数据库技术研发工作。