In Defense of MOT:读CVPR17《Deep Network Flow for Multi-Object Tracking》有感
多目标跟踪的帧间数据关联可以分为online(frame-by-frame)和offline(batch-by-batch)两类。前者讲究追求real-time tracking,跟踪结果的给出无时延,理论上讲可以拼Real-time(可惜往往没戏嘻嘻。。);后者讲究利用前后帧更多的信息,即在一个time window中一次性实现多帧的关联,用精度换速度换时效性。不可避免地带了了输出的迟滞,而且关联的问题也由online的二部图匹配提升到多部图匹配,且匹配的解空间随batch的增大而指数增长。
用Network flow(NF)解多目标跟踪中的帧间数据关联基本属于标准操作,隶属于上述的第二类batch-mode。此类用NF方法解detections或者tracklets之间关联的业界标杆是USC Nevatia大师的CVPR08佳作《Global Data Association for Multi-Object Tracking Using Network FLows》以及ECCV08《Robust Object Tracking by Hierarchical Association of Detection Responses》。当然,我的带教导师UCF Dr.Shah也在此方面多有建树。但是Shah大师更倾向于用multi-clique的方法来formulate多目标关联的问题,详情请搜GMCP tracker~~~
下接正文:
核心上说,Bipartite Matching是逐帧关联,是一种online method;Network Flow是一种batch-mode,offline多帧关联。不论是BM还是NF,都可以化作一个Linear Programming的优化问题求解。而且,Bipartite matching(乃至多步图匹配问题)也可以化作network flow的问题。而在这个优化问题中,最关键的是cost function。
Cost function和affinity metric是分不开的。作为衡量pair-wise cost而言,链各个entities之间的affinity往往是影响cost的重要依据。而这种pair-wise affinity的来源,一般有detector confidence,motion & appearance similarities,i.e. temporal & spatial distances。
本文是分步走的DA,先DR2DR生成TLs(没有用Detector,DR是直接用数据库给出的DR),再由TLs生成Traj。DR2DR DA用的是overlapping temporal window做的batch-wise network flow minimization bi-level optimization;而TL2TL用的是HA做二部图匹配,affinity用的是两个TL之间重合的DR数目。
在DR2DR用network flow解多步图匹配阶段establish E2E learning。学什么?学cost,准确说是学cost function中的参数。把多步图匹配求解的问题转化为一个bi-level minimization,其中的cost term是参数化的,学就学cost里面的参数。当然,因为是E2E,所以gradient BP回前段计算appearance affinity时的CNN feature extractor too。所谓参数化cost,就是省去原来hand-crafted cost function时1.对function的选择,2. Grid search优化调参。可学习的cost function就是一些MLP把输入feature转化为一个scalar value output。
- 如何把一个多帧DA的多步图匹配转化为一个Network Flow问题(即构建一个NF graph,在这个graph里面找出minimum flow):

- 如图所示是一个三帧的三步图匹配;分别有3,3,2个目标;
- 每个DR在NF graph里转化为一对儿nodes;
- NF graph中有一个源节点和一个终点(S and T);
- NF graph中一共有两类4种edge,每个edge有一个indicator x和一个cost c:
Unary edge:
- Xidet,Cidet :一个DR的一对儿Node之间的edge,(cost通常来自detector confidence);红色
- Xiin,Ciin :一个DR中的前一个node与源节点的edge;黑色
- Xiout,Ciout :一个DR中的后一个node与终节点的edge;黑
Pairwise edge:
Xi,jlink,Ci,jlink:前面帧DR的后一个节点与后面帧DR的前一个节点的edge(cost通常是连个DR的affinity)。注意,这里面前后DR可以跨帧连接,这样可以客服occlusion和missed DR带来的fragmentation;蓝色
在这个NF graph中,求最优association就是求最优的一组edge x*能够有最优的minimum over all全graph源点到终点的flow(图中粗线就是最优解,可见有些蓝色的pairwise edge没有在解中):要满足flow conservation constraint所以就不会出现最优解是0 flow,因为in-edge是正无穷的weight,而所有edge上的cost都是负值,相当于在还债。Affinity越大,confidence越大,越负,就能换越多的债,就越会出现在解中。

本文要E2E学的,就是上式子中的cost term c。传统方法中c是hand-made,固定的公式。这里,我们让c变成一个parameterized cost function,这样整个E2E train的loss minimization优化问题就变成了一个Bi-level的双优化问题,同时优化整个训练的loss,以及minimum flow as a constraint:

其中c = c(f,θ),θ就是要train要学的参数。
- 训练:
- 制作gt数据:
GT数据就是一组xgt indicators (0或1),指定那些edge是activated,就说明这条edge上相关的node的相关的DR在traj上。
在多目标跟踪库上有两组bbox:一组是由ID的人工画出来的bbox是GT,一组是没有ID的但是有detector confidence score的detector检测结果bbox是DRs。因为网络的输入时raw DR,所以做GT就是把同样这些DR给上标签的过程。做GT就是把和某个GT box IoU超过0.5的confidence最大的DR box assign给这个GT traj,即这个DR在NF graph中的xdet是1,且跨帧连接路径中有这个DR,它与上下帧中同样assign给这个GT traj的DR们之间的Xlink是1,若没有上下帧同样ID的DR,则这个DR的xin或者xout是1。
- Loss function:weighted L2 loss w.r.t. unary and pairwise edge,weight来reason不同的FP-TP-FN-TN连接的情况。
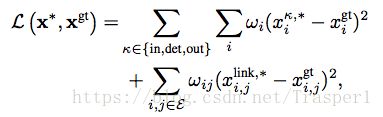
- 跟踪逻辑:
- 用密集overlapp的temporal滑窗得到一段一段帧的DRs,然后解决每个小窗里的基于NF的多步图匹配问题,得到TLs;
- Tl和TL之间的关联用基于overlapping DR numer为affinity的HA来做二部图匹配。
- cost function:
- hand-crafted:
![]()
![]()
![]()
上述式子中的hyper-parameters包括α,β,C,通过grid search来不断尝试最大化MOTA同时maintain Recall来确定。这个调参的过程是exponential的随着超参数的数量增长,然而这也正是使用hand-crafted cost的最大弊端。
- Learned with NF:
Unary cost与上述hand-crafted一样,而pairwise cost选用1 layer MLP with 64 neurons,or two layers MLP with 32 neurons each。就是用全连接层来,输入feature,转换产生scalar value cost,这样就省去了对β调参的过程。
- Features used to compute cost(affinity)with:
在Bipartite matching的场景下是最大化overall affinity,而在mini-network flow场景下就是最小化cost,而cost往往是affinity取倒数。
Motion-wise,用的是bbox IoU,ALFD;
Appearance-wise,用的是raw image with ResNet feature extractor,or Siamese CNN直接compute pairwise score。