Datax 与 Azkaban 实现数据抽取与调度
1.什么是DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github
DataX的安装省略
配置详情可见 https://github.com/alibaba/DataX
运行原理介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发(可在json配置文件中配置)运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出。
工作流程介绍:
工作流程大概就是用Reader模块从源数据库读数据,在Storage模块里将Reader模块读到的数据交换给Write模块,
Write模块将数据写进目的数据库。
DoubleQueue:
设立两块空间,一个存储源数据,一个存储目标数据。在开始,空间A和空间B都是空的,loading 任务从源数据库向A空间加载数据,A空间满后再向B空间加载数据,同时dumping任务将A空间数据转储到目的数据库。A空间清空后,交换AB两者的任务,即A空间的任务换成loading,B空间的任务换成dumping。不断重复上述操作。
RAMStorage:基于DoubleQueue,用内存作为数据交换的空间
基于RAMStorage的数据操纵接口:LineSender和LineReceiver
LineSender的作用:Reader用LineSender来放数据到Storage对象中。
在LineSender接口里,主要有这几个接口:
createLine():构造一个将要被用来交换数据的Line对象
sendToWriter(Line line): 用来将一个Line对象put到Storage抽象类里。
flush()用来将buffer的数据flush到Storage对象中。
LineReceiver的作用:Writer用LineReceiver来从到Storage对象中获取数据。在LineReceiver接口里,主要有一个接口:getFromReader():获取下一个Storage中的Line对象。
基于RAMStorage的批量数据交换:BufferedLineExchanger
内部初始化一个指定大小的数组缓冲,默认大小64 ,在push数据时会先写满64个数组再单次写入DoubleQueue队列,Poll时返回的大小可能会小于64个单位,由当时数组的实际大小决定。
2.什么是Azkaban
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies 来设置依赖关系,这个依赖关系必须是无环的,否则会被视为无效的工作流。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
需求:从Oracle抽取每天的用户行为日表到HIVE分区表中,即数据的ODS层
技术选型:利用Datax与azkaban,其中Datax可方便配置能与关系型数据库进行交互
其中Azkabn的调度job为:

把此job上传到azkaban的界面如图:

其中DataX的配置为:
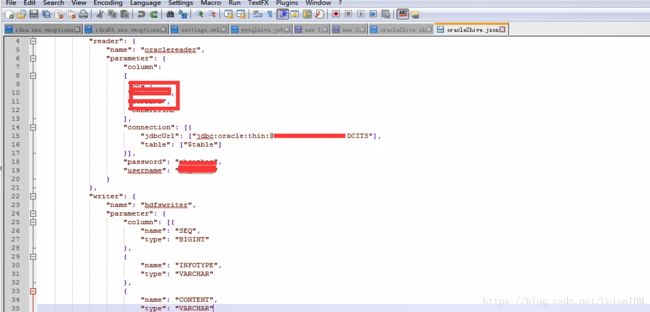
问题解决:
azkaban-web-start.sh启动时出现Table 'execution_flows' is marked as crashed and should be repaired Query
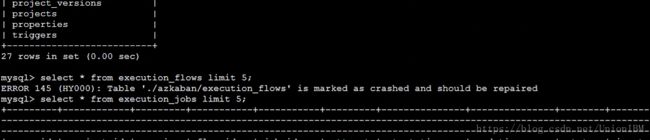
由于azkaban非正常关闭,导致数据表损坏现对数据进行修复

修复后对数据进行check如图,说明表已经repair
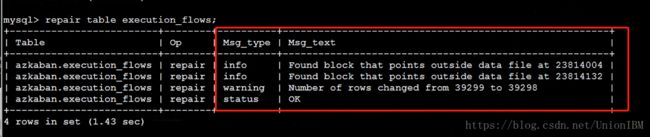
对表进行修复后,顺利启动了azkaban