摘要
Attention 注意力模型在神经网络中被广泛应用。在已有的工作中,Attention 机制一般是决定性的而非随机变量。我们提出了将 Attention 建模成隐变量,并应用 VAE 和 policy gradient 训练模型。在不使用 KL annealing 等 trick 的情况下训练,在 IWSLT 14 German-English 上建立了新的 state-of-the-art。
■ 论文 | Latent Alignment and Variational Attention
■ 链接 | https://www.paperweekly.site/papers/2120
■ 源码 | https://github.com/harvardnlp/var-attn
背景
近年来很多文章将 VAE 应用到文本生成上,通过引入隐变量对文本中的一些不确定性(diversity,如文章风格主题、蕴含情感等)进行建模。这样做往往会遇到一个常见的问题—— KL collapsing。这个问题最早在 16 年时由 Bowman 指出 [1],其描述的现象是直接训练 VAE 得到的 KL 接近 0——这也就意味着近似后验和先验一样,使得隐变量被模型忽略 [5]。
Bowman 的解决办法是使用 KL annealing [1](KL 项的权重从 0 开始逐渐增加到 1)或者 word dropout(不常用在此略过)。随后,17 年 Yang 等人对 KL collapsing 的问题进行了更细致的分析 [2],并提出降低 decoder 的 contextual capacity 改善这个现象。此外 Zhao 等人提出 bag-of-word loss 去解决这个问题 [3]。18年 Graves 等人也对 KL collapsing 进行了分析 [4]。
在我们的工作中,Attention 被建模成隐变量。值得注意的是,我们将 Attention 建模成隐变量并不是为了单纯应用 VAE 这个工具,而是因为我们认为将 Attention 建模成隐变量可以为 decoder 提供更 clean 的 feature,从而在不增加模型参数的情况下提高模型的表达能力(注意 inference network 在测试阶段不被使用因此不计入模型参数)。
以下是一个简单的直觉:下图蓝色部分展示的是传统 Attention,下图红色部分展示的我们提出的隐变量 Attention。传统的 Attention 机制仅能通过之前生成的单词确定当前即将生成单词的 Attention,而因为存在多种翻译方式,所以会出现 attend 到和实际翻译的单词并不对应的位置的问题。而在红色部分展示的我们提出的隐变量 Attention 中,我们可以通过全部的源文本和目标文本去得到更准确的后验 Attention,因此 Attention 和实际翻译应该 attend 的源单词对应得更好。并且,这样得到的更好的后验 Attention 可以提供给 decoder,从而使 decoder 拿到更 clean 的 feature,藉此可以得到更好的模型。

方法
基于这个直觉,我们将注意力 Attention 建模成隐变量。假定 x 是源文本,y 是目标文本,z 是 attention,根据标准的 VAE 方法,我们引入 inference network q(z | x, y) 去近似后验,那么 ELBO 可以表达为(为了简单我们考虑目标文本只有一个单词的情况):

上面不等式的右侧是 ELBO,其中第一项是从 q(z | x, y) 中采样出 Attention,使用采样出的 Attention 作为 decoder 的输入计算 cross entropy loss,第二项是确保后验分布接近先验分布。这里值得注意的是,此处的先验和一般的 VAE 不同,我们的先验是和模型一起学习的。
因为我们的 p(z | x) 和 q(z | x, y) 都是 categorical 分布,所以我们使用 policy gradient 去优化上面的目标函数。由于 decoder 和 encoder 之间的主要信息传输通道是通过 attention,如果忽略了这个隐变量,就会无法得到源文本的信息而得到很大的 penalty。这与之前的许多工作中直接把隐变量加入到每个 decoding step 不同,因为那样即使 decoder 忽略了隐变量,也可以达到很好的模型表现 [5]。因此通过直接优化目标函数这个隐变量也不易被忽略,我们的实验完全验证了这一点。
由于我们的后验 q 能看到全部的 x 和 y,因此后验中采样的 Attention 可以比先验 p(z | x) 好,比如以下的例子:
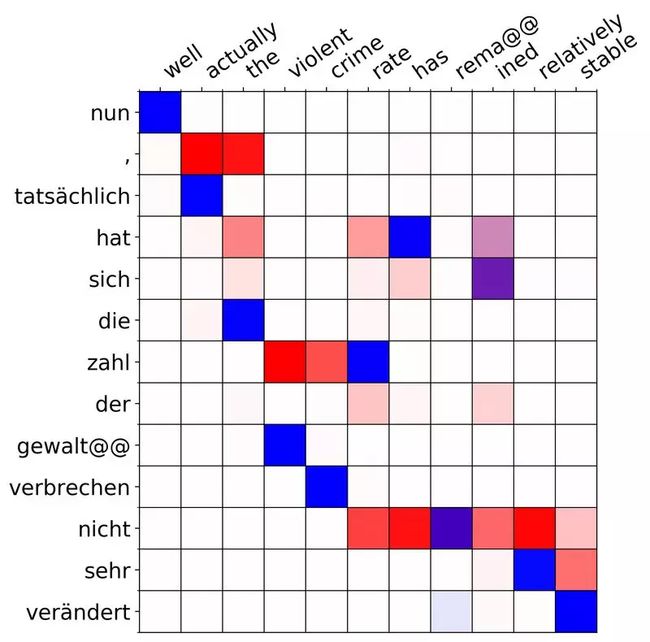
这里我们把德语(纵向)翻译成英语(横向)。红色代表先验,即只观测到 x 而不观测到 y 的 p(z | x),蓝色代表后验,即观测到全部信息的 p(z | x, y)。注意到在第二个单词 actually 处,红色的先验试图 attend 到 nun 后面的逗号“,”,从而试图生成一个 “well,” 的翻译结果。然而实际的英语翻译中并没有逗号,反而直接是 well actually。
由于后验 q(z | x, y) 可以看到实际的翻译,因此蓝色的后验正确 attend 到了 tatsachlich 上。注意到训练目标 ELBO 中我们从 q 中采样 Attention 给 decoder,因此通过使用 VAE 的方法,decoder 得到了更准确的 Attention 信号,从而可能提高模型的表达能力。
结果
实验上,我们在 IWSLT 14 German-English 上得到了新的 state-of-art。其中 KL 大约在 0.5,cross entropy loss 大约在 1.26,而且我们人工比较了很多后验和先验也很符合我们的建模直觉。
欢迎尝试我们的代码,我们提供了能复现我们 state-of-art 效果的 preprocessing、training、evaluation 的 command,以及我们报告的模型。
相比过去的大部分工作是从 Attention 计算出来的固定维度的 context vector,我们提出了将 Attention 建模成隐变量,即在 simplex 上的 Attention 本身。由于我们的工作是对 Attention 注意力机制的改进,因此理论上可以被应用到一切包含 Attention 的 task 中。文章里除了机器翻译外我们也做了个视觉问答系统的实验。我们的具体模型和 inference network 的结构请参见我们的论文和代码。
限于作者的水平,本文中有错误和纰漏在所难免,望读者朋友多多包涵。也欢迎发邮件给我[email protected] 交流。
参考文献
[1]. Bowman et al, Generating Sentences from a Continuous Space
[2]. Yang et al, Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
[3]. Zhao et al, Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders
[4]. Graves et al, Associative Compression Networks for Representation Learning
[5]. Zhang et al, Variational Neural Machine Translation