CUDA多线程
随着多核CPU和众核GPU的到来,并行编程已经得到了业界越来越多的重视,CPU-GPU异构程序能够极大提高现有计算机系统的运算性能,对于科学计算等运算密集型程序有着非常重要的意义。这一系列文章是根据《CUDA C语言编程指南》来整理的,该指南是NVIDIA公司提供的CUDA学习资料,介绍了CUDA编程最基本最核心的概念,是学习CUDA必不可少的阅读材料。
初学CUDA,笔记错误之处在所难免,还请发现问题的诸位读者不吝赐教。
1. 什么是CUDA?
CUDA全称是Compute Unified Device Architecture,中文名称即统一计算设备架构,它是NVIDIA公司提出了一种通用的并行计算平台和编程模型。使用CUDA,我们可以开发出同时在CPU和GPU上运行的通用计算程序,更加高效地利用现有硬件进行计算。为了简化并行计算学习,CUDA为程序员提供了一个类C语言的开发环境以及一些其它的如FORTRAN、DirectCOmpute、OpenACC的高级语言/编程接口来开发CUDA程序。
2. CUDA编程模型如何扩展?
我们知道,不同的GPU拥有不同的核心数目,在核心较多的系统上CUDA程序运行的时间较短,而在核心较少的系统上CUDA程序的执行时间较多。那么,CUDA是如何做到的呢?
并行编程的中心思想是分而治之:将大问题划分为一些小问题,再把这些小问题交给相应的处理单元并行地进行处理。在CUDA中,这一思想便体现在它的具有两个层次的问题划分模型。一个问题可以首先被粗粒度地划分为若干较小的子问题,CUDA使用被称为块(Block)的单元来处理它们,每个块都由一些CUDA线程组成,线程是CUDA中最小的处理单元,将这些较小的子问题进一步划分为若干更小的细粒度的问题,我们便可以使用线程来解决这些问题了。对于一个普通的NVIDIA GPU,其CUDA线程数目通常能达到数千个甚至更多,因此,这样的问题划分模型便可以成倍地提升计算机的运算性能。
GPU是由多个流水多处理器构成的,流水处理器以块(Block)为基本调度单元,因此,对于流水处理器较多的GPU,它一次可以处理的块(Block)更多,从而运算速度更快,时间更短。而反之对于流水处理器较少的GPU,其运算速度便会较慢。这一原理可以通过下图形象地看出来:
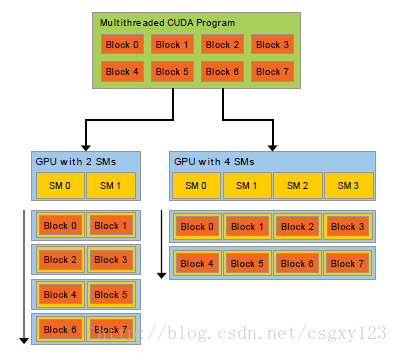
3. CUDA基本概念(上)
本节将介绍CUDA的一些基本的编程概念,该节用到的例子来自于CUDA Sample中的VectorAdd项目。
3.1 内核(Kernels)
CUDA C是C语言的一个扩展,它允许程序员定义一种被称为内核函数(Kernel Functions)的C函数,内核函数运行在GPU上,一旦启动,CUDA中的每一个线程都将会同时并行地执行内核函数中的代码。
内核函数使用关键字__global__来声明,运行该函数的CUDA线程数则通过<<<...>>>执行配置语法来设置。(参见章节"C语言扩展"),每一个执行内核函数的线程都由一个唯一的线程ID,这一ID可以通过在内核函数中访问threadIdx变量来得到。
下面通过一些示例代码来展示刚刚提到的这些概念该如何应用在编程中:
- // Kernel definition
- __global__ void VecAdd(float* A, float* B, float* C) {
- int i = threadIdx.x;
- C[i] = A[i] + B[i];
- }
- int main() {
- ...
- // Kernel invocation with N threads
- VecAdd<<<1, N>>>(A, B, C);
- ...
- }
3.2 线程层次(Thread Hierarchy)
CUDA的每一个线程都有其线程ID,线程的ID信息由变量threadIdx给出。threadIdx是CUDA C语言的内建变量,通常它用一个三维数组来表示。使用三维数组的方便之处在于可以很方便地表示一维、二维和三维线程索引,进而方便地表示一维、二维和三维线程块(thread block)。这样,无论是数组、矩阵还是体积的计算,都可以很容易地使用CUDA进行运算。
线程的索引与线程ID之间存在着直接的换算关系,对于一个索引为(x, y, z)的线程来说:
1、如果线程块(block)是一维的,则线程ID = x
2、如果线程块是二维的,假设块尺寸为(Dx,Dy),那么线程ID = x + y * Dx
3、如果线程块是三维的,设其尺寸为(Dx,Dy,Dz),那么线程ID = x + y * Dx + z * Dx * Dy
下面的例子展示了两个NxN矩阵相加的CUDA实现:
- // Kernel definition
- __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
- int i = threadIdx.x;
- int j = threadIdx.y;
- C[i][j] = A[i][j] + B[i][j];
- }
- int main() {
- ...
- // Kernel invocation with one block of N * N * 1 threads
- int numBlocks = 1;
- dim3 threadsPerBlock(N, N);
- MatAdd<<
- ...
- }
上面的例子中numBlocks代表线程块的数量,这里的值为1。在一般的CUDA程序中,这个值通常大于1,也就是说将会有多个线程块被分配到多个处理器核中同时进行处理,这样就大大提高了程序的并行性。
在CUDA中,线程块包含在线程格(grid)当中,线程格可以是一维、二维或者三维的,线程格的尺寸一般根据待处理数据的规模或者处理器的数量来指定。线程格中所包含的线程块数目通常远远大于GPU处理器核心的数目。下图展示了线程格(grid)、线程块(block)以及线程(thread)之间的关系:
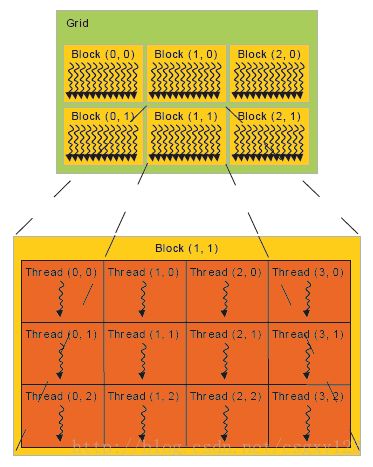
内核函数的调用可以简化为kernel<<>>(parameters),在尖括号中,A代表线程格(grid)的尺寸,它可以是三维的,用类型dim3表示,也可以是一维的,用int类型表示。B代表线程块(block)的尺寸,它与A类似,也可分别用dim3或int类型表示。
在内核函数内部,CUDA为我们内建了一些变量用于访问线程格、线程块的尺寸和索引等信息,它们是:
1. gridDim:代表线程格(grid)的尺寸,gridDim.x为x轴尺寸,gridDim.y、gridDim.z类似。拿上图来说,它的gridDim.x = 3,gridDim.y = 2,gridDim.z = 1。
2. blockIdx:代表线程块(block)在线程格(grid)中的索引值,拿上图来说,Block(1,1)的索引值为:blockIdx.x = 1,blockIdx.y = 1。
3. blockDim:代表线程块(block)的尺寸,blockDIm.x为x轴尺寸,其它依此类推。拿上图来说,注意到Block(1,1)包含了4 * 3个线程,因此blockDim.x = 4, blockDim.y = 3。
4. threadIdx:线程索引,前面章节已经详细探讨过了,这里不再赘述。
明白了这些变量的含义,那么下面的矩阵加法程序便不难理解了:
- // Kernel definition
- __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
- int i = blockIdx.x * blockDim.x + threadIdx.x;
- int j = blockIdx.y * blockDim.y + threadIdx.y;
- if (i < N && j < N)
- C[i][j] = A[i][j] + B[i][j];
- }
- int main() {
- ...
- // Kernel invocation
- dim3 threadsPerBlock(16, 16);
- dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
- MatAdd<<
- ...
- }
线程块(block)是独立执行的,在执行的过程中线程块之间互不干扰,因此它们的执行顺序是随机的。
同一线程块中的线程可以通过访问共享内存(shared memory)或者通过同步函数__syncthreads()来协调合作。这些概念将在以后的章节中详细解释。
文章转自:http://blog.csdn.net/csgxy123/article/details/9704461