MySQL的主从复制延迟问题
主从复制延迟产生的原因
当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
解决方法:
1.最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。mysql-5.6.3已经支持了多线程的主从复制。原理和丁奇的类似,丁奇的是以表做多线程,Oracle使用的是以数据库(schema)为单位做多线程,不同的库可以使用不同的复制线程。
sync_binlog=1
This makes MySQL synchronize the binary log’s contents to disk each time it commits a transaction
默认情况下,并不是每次写入时都将binlog与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能binlog中最后的语句丢 失了。要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使binlog在每N次binlog写入后与硬盘 同步。即使sync_binlog设置为1,出现崩溃时,也有可能表内容和binlog内容之间存在不一致性。如果使用InnoDB表,MySQL服务器 处理COMMIT语句,它将整个事务写入binlog并将事务提交到InnoDB中。如果在两次操作之间出现崩溃,重启时,事务被InnoDB回滚,但仍 然存在binlog中。可以用--innodb-safe-binlog选项来增加InnoDB表内容和binlog之间的一致性。(注释:在MySQL 5.1中不需要--innodb-safe-binlog;由于引入了XA事务支持,该选项作废了),该选项可以提供更大程度的安全,使每个事务的 binlog(sync_binlog =1)和(默认情况为真)InnoDB日志与硬盘同步,该选项的效果是崩溃后重启时,在滚回事务后,MySQL服务器从binlog剪切回滚的 InnoDB事务。这样可以确保binlog反馈InnoDB表的确切数据等,并使从服务器保持与主服务器保持同步(不接收 回滚的语句)。
innodb_flush_log_at_trx_commit (这个很管用)
抱怨Innodb比MyISAM慢 100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电 池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据。
2.MySQL从库上有一个IO线程负责从主库取binlog到写到本地。另外有一个SQL线程负责执行这些本地日志,实现命令重放;正常网络状况下IO线程没有性能问题(这个待会会用到),问题是SQL线程只有一个,更新速度跟不上。所以经常会看到从库的CPU idle很高,但同步性能就是上不去。

单线程的SQL线程是造成这个问题的主要原因。比较直接的想法是把它改成多线程版本,这个据说官方版本开发中,其实我们也有一个这样的patch,但是直接写大片代码在线上提供服务的slave机器上这种事儿,都会因为担心稳定性而很难推动(写patch的和运维的同学,你们懂的)。
所以打算用一个“第三方”工具中转,来实现多线程同步。基本结构如下:
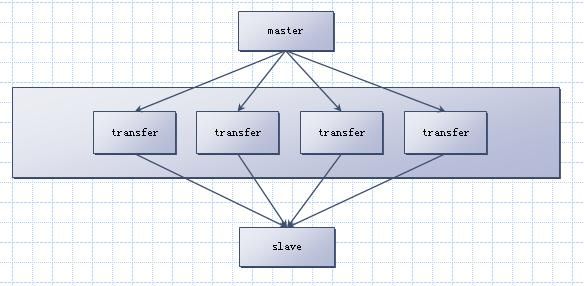
说明:
1、这些transefer从master上各自同步一部分的数据,分别独立更新slave。多进程还是多线程均可。
2、Transfer与master之间异步更新日志,transfer与slve之间同步更新数据
3、从这可以看出这个方案的缺点之一:更新能够被独立分开。比较直观的想法是,按照表分。
关于transfer
作为这个关键的转发工具transfer,需要提供如下功能:
1、能够指定同步master中的哪部分数据,并且能够方便地修改这个配置以应对master的加表需求;
2、支持stop slave、start slave。支持快速切换到新主库的change master命令。
3、能够记录读取点,transfer自己重启或master重启后能够按照记录点继续读后面的binlog;
4、能够记录分发点,transfer自己重启或slave重启后能够按照记录点继续同步给slave
Transfer的这么多功能,自己造轮子就累了。这里直接用MySQL来充当此角色。为了方便描述,下文还将之称为transfer。Transfer更新slave在功能上可以使用federated引擎,但由于其纠结的实现导致性能上达不到要求,因此在MySQL框架层中作了一点修改――读到同步日志后,直接发送给slave。
方案简单描述如下:
1、Slave机器上搭另外的若干个MySQL(transfer),将其设为Master的从库,且设置replicate-do-table, 每个transfer承担一部分的表。
2、所有Transfer的更新目标都设置为slave,其更新方式是读到日志后直接mysql_real_query执行到slave上。
从这可以看出这个方案的缺点之二:只能支持statement格式的同步方式。其实row也能支持,后面再说。
在transfer放弃federated引擎改用直接发送后,性能提升不少,从库同步性能增加一倍,但从本文第一个图的数据对比就知道,延迟还很大。
发现这个时候slave的机器cpu已经很忙了,idle 20%一下――这个算是好消息,总比idle很高但性能上不去好。
实际上是因为每个transfer,虽然设置只同步其中的部分表,但在实现上是IO线程把master上的所有命令都备份到本地,然后在SQL线程执行的时候再判断,若不符合replicate-do-table,再放弃。
这样存在的问题,是n个transfer,磁盘写了n倍,更严重的是导致SQL线程空转。
我们上文提到整个流程中IO线程是比较空闲的,因此修改IO线程逻辑,在写入磁盘前先判断,若不符合本transfer的replicate-do-table设置,不写盘,直接放弃。

从库的QPS由于线程切换会有抖动,但总的执行时间与主库相同。从库的cpu idle下降,与主库几乎同时恢复到100。
总结:
1、要求在slave机器上多配置n个transfer(是否在从库上均可)
2、目前只能支持statement的binlog格式,实际上row可以支持,方案定了,开发计划中。
3、跨表更新的语句,会按照其更新的第一个表,分发到唯一一个transfer,没有重复更新的问题,但有时序性问题。
转自:http://weadyweady.blog.51cto.com/3012956/1651169