Git原理入门解析
前言: 之前听过公司大佬分享过 Git 原理之后就想来自己总结一下,最近一忙起来就拖得久了,本来想塞更多的干货,但是不喜欢拖太久,所以先出一版足够入门的;
一、Git 简介
Git 是当前流行的分布式版本控制管理工具,最初由 Linux Torvalds (Linux 之父) 创造,于 2005 年发布。
Git,这个词其实源自英国俚语,意思大约是 “混账”。Linux 为什么会以这样自嘲的名字来命名呢?这其中还有一段儿有趣的历史可以说一说:
以下摘自:https://www.liaoxuefeng.com/wiki/896043488029600/896202815778784
Git 的诞生:
很多人都知道,Linus 在 1991 年创建了开源的 Linux,从此,Linux 系统不断发展,已经成为最大的服务器系统软件了。
Linus 虽然创建了 Linux,但 Linux 的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为 Linux 编写代码,那 Linux 的代码是如何管理的呢?
事实是,在 2002 年以前,世界各地的志愿者把源代码文件通过 diff 的方式发给 Linus,然后由 Linus 本人通过手工方式合并代码!
你也许会想,为什么 Linus 不把 Linux 代码放到版本控制系统里呢?不是有 CVS、SVN 这些免费的版本控制系统吗?因为 Linus 坚定地反对 CVS 和 SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比 CVS、SVN 好用,但那是付费的,和 Linux 的开源精神不符。
不过,到了 2002 年,Linux 系统已经发展了十年了,代码库之大让 Linus 很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是 Linus 选择了一个商业的版本控制系统 BitKeeper,BitKeeper 的东家 BitMover 公司出于人道主义精神,授权 Linux 社区免费使用这个版本控制系统。
安定团结的大好局面在 2005 年就被打破了,原因是 Linux 社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发 Samba 的 Andrew 试图破解 BitKeeper 的协议(这么干的其实也不只他一个),被 BitMover 公司发现了(监控工作做得不错!),于是 BitMover 公司怒了,要收回 Linux 社区的免费使用权。
Linus 可以向 BitMover 公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是:Linus 花了两周时间自己用 C 写了一个分布式版本控制系统,这就是 Git!一个月之内,Linux 系统的源码已经由 Git 管理了!牛是怎么定义的呢?大家可以体会一下。
Git 迅速成为最流行的分布式版本控制系统,尤其是 2008 年,GitHub 网站上线了,它为开源项目免费提供 Git 存储,无数开源项目开始迁移至 GitHub,包括 jQuery,PHP,Ruby 等等。
历史就是这么偶然,如果不是当年 BitMover 公司威胁 Linux 社区,可能现在我们就没有免费而超级好用的 Git 了。
版本控制系统
不管是集中式的 CVS、SVN 还是分布式的 Git 工具,实际上都是一种版本控制系统,我们可以通过他们很方便的管理我们的文件、代码等,我们可以先来畅想一下如果自己来设计这么一个系统,你会怎么设计?
摁,这不禁让我想起了之前写毕业论文的日子,我先在一个开阔的空间创建了一个文件夹用于保存我的各种版本,然后开始了我的 “毕业论文版本管理”,参考下图:

这好像暴露了我写毕业论文愉快的经历..但不管怎么样,我在用一个粗粒度版本的制度,在对我的毕业论文进行着管理,摁,我通过不停在原基础上迭代出新的版本的方式,不仅保存了我各个版本的毕业论文,还有这清晰的一个路径,完美?NO!
问题是:
每一次的迭代都更改了什么东西,我现在完全看不出来了!
当我在迭代我的超级无敌怎么样都不改的版本的时候,突然回想起好像之前版本 1.0 的第一节内容和 2.0 版本第三节的内容加起来才是最棒的,我需要打开多个文档并创建一个新的文档,仔细对比文档中的不同并为我的新文档添加新的东西,好麻烦啊…
到最后文件多起来的时候,我甚至都不知道是我的 “超级无敌版” 是最终版,还是 “打死都不改版” 是最终版了;
更为要命的是,我保存在我的桌面上,没有备份,意味着我本地文件手滑删除了,那我就…我就…就…
并且可能问题还远不止于此,所以每每想起,就不自觉对 Linux 膜拜了起来。

集中式与分布式的不同
Git 采用与 CSV/SVN 完全不同的处理方式,前者采用分布式,而后面两个都是集中式的版本管理。
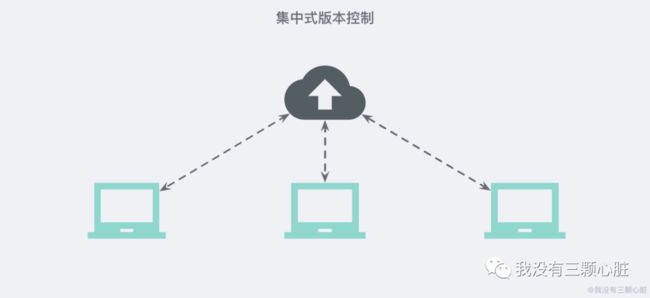
先说集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
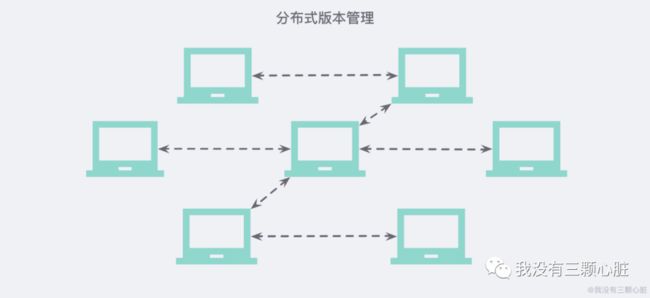
那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统根本没有 “中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件 A,你的同事也在他的电脑上改了文件 A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当 “中央服务器” 的电脑,但这个服务器的作用仅仅是用来方便 “交换” 大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
当然,Git 的强大还远不止此。
二、Git 原理入门
Git 初始化
首先,让我们来创建一个空的项目目录,并进入该目录。
$ mkdir git-demo-project
$ cd git-demo-project
如果我们打算对该项目进行版本管理,第一件事就是使用 git init 命令,进行初始化。
$ git init
git init 命令只会做一件事,就是在项目的根目录下创建一个 .git 的子目录,用来保存当前项目的一些版本信息,我们可以继续使用 tree -a 命令查看该目录的完整结构,如下:
$ tree -a
.
└── .git
├── HEAD
├── branches
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── prepare-commit-msg.sample
│ └── update.sample
├── index
├── info
│ └── exclude
├── objects
│ ├── .DS_Store
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
Git 目录简单解析
config 目录
config 是仓库的配置文件,一个典型的配置文件如下,我们创建的远端,分支都在等信息都在配置文件里有表现;fetch 操作的行为也是在这里配置的:
[core]
repositoryformatversion = 0
filemode = false
bare = false
logallrefupdates = true
symlinks = false
ignorecase = true
[remote "origin"]
url = [email protected]:yanhaijing/zepto.fullpage.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
[branch "dev"]
remote = origin
merge = refs/heads/dev
objects 目录
Git 可以通过一种算法可以得到任意文件的 “指纹”(40 位 16 进制数字),然后通过文件指纹存取数据,存取的数据都位于 objects 目录。
例如我们可以手动创建一个测试文本文件并使用 git add . 命令来观察 .git 文件夹出现的变化:
$ touch test.txt
$ git add .
git add . 命令就是用于把当前新增的变化添加进 Git 本地仓库的,在我们使用后,我们惊奇的发现 .git 目录下的 objects/ 目录下多了一个目录:
$ tree -a
.
├── .git
│ ├── HEAD
│ ├── branches
│ ├── config
│ ├── description
│ ├── hooks
│ │ ├── 节省篇幅..省略..
│ ├── index
│ ├── info
│ │ └── exclude
│ ├── objects
│ │ ├── .DS_Store
│ │ ├── e6
│ │ │ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391
│ │ ├── info
│ │ └── pack
│ └── refs
│ ├── heads
│ └── tags
└── test.txt
我们可以使用 git hash-object test.txt 命令来看看刚才我们创建的 test.txt 的 “文件指纹”:
$ git hash-object test.txt
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
这时候我们可以发现,新创建的目录 e6 其实是该文件哈希值的前两位,这其实是 Git 做的一层类似于索引一样的东西,并且默认采用 16 进制的两位数来当索引,是非常合适的。
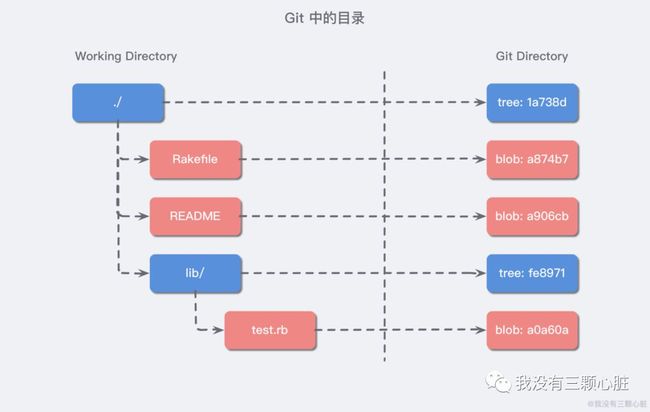
objects 目录下有 3 种类型的数据:
Blob;
Tree;
Commit;
文件都被存储为 blob 类型的文件,文件夹被存储为 tree 类型的文件,创建的提交节点被存储为 Commit 类型的数据;
一般我们系统中的目录(tree),在 Git 会像下面这样存储:
而 Commit 类型的数据则整合了 tree 和 blob 类型,保存了当前的所有变化,例如我们可以再在刚才的目录下新建一个目录,并添加一些文件试试:
$ mkdir test
$ touch test/test.file
$ tree -a
.
├── .git
│ ├── HEAD
│ ├── branches
│ ├── config
│ ├── description
│ ├── hooks
│ │ ├── 节省篇幅..省略..
│ ├── index
│ ├── info
│ │ └── exclude
│ ├── objects
│ │ ├── .DS_Store
│ │ ├── e6
│ │ │ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391
│ │ ├── info
│ │ └── pack
│ └── refs
│ ├── heads
│ └── tags
├── test
│ └── test.file
└── test.txt
提交一个 Commit 再观察变化:
$ git commit -a -m "test: 新增测试文件夹和测试文件观察.git文件的变化"
[master (root-commit) 30d51b1] test: 新增测试文件夹和测试文件观察.git文件的变化
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 test.txt
$ tree -a
.
├── .git
│ ├── COMMIT_EDITMSG
│ ├── HEAD
│ ├── branches
│ ├── config
│ ├── description
│ ├── hooks
│ │ ├── 节省篇幅..省略..
│ ├── index
│ ├── info
│ │ └── exclude
│ ├── logs
│ │ ├── HEAD
│ │ └── refs
│ │ └── heads
│ │ └── master
│ ├── objects
│ │ ├── .DS_Store
│ │ ├── 30
│ │ │ └── d51b1edd2efd551dd6bd52d4520487b5708c0e
│ │ ├── 5e
│ │ │ └── fb9bc29c482e023e40e0a2b3b7e49cec842034
│ │ ├── e6
│ │ │ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391
│ │ ├── info
│ │ └── pack
│ └── refs
│ ├── heads
│ │ └── master
│ └── tags
├── test
│ └── test.file
└── test.txt
首先我们可以观察到我们提交了一个 Commit 的时候在第一句话里面返回了一个短的像是哈希值一样的东西:[master (root-commit) 30d51b1] 中 的 30d51b1,对应的我们也可以在 objects 找到刚才 commit 的对象,我们可以使用 git cat-file -p 命令输出一下当前文件的内容:
$ git cat-file -p 30d5
tree 5efb9bc29c482e023e40e0a2b3b7e49cec842034
author 我没有三颗心脏 1565742122 +0800
committer 我没有三颗心脏 1565742122 +0800
test: 新增测试文件夹和测试文件观察.git文件的变化
我们发现这里面有提交的内容信息、作者信息、提交者信息以及 commit message,当然我们可以进一步看到提交的内容具体有哪些:
$ git cat-file -p 5efb
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 test.txt
我们再试着提交一个 commit 来观察变化:
$ touch test/test2.file
$ git commit -a -m "test: 新增加一个 commit 以观察变化."
[master 9dfabac] test: 新增加一个 commit 以观察变化.
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 test/test.file
create mode 100644 test/test2.file
$ git cat-file -p 9dfabac
tree c562bfb9441352f4c218b0028148289f1ea7d7cd
parent 30d51b1edd2efd551dd6bd52d4520487b5708c0e
author 龙滔 1565878699 +0800
committer 龙滔 1565878699 +0800
test: 新增加一个 commit 以观察变化.
可以观察到这一次的 commit 多了一个 parent 的行,其中的 “指纹” 和上一次的 commit 一模一样,当我们提交两个 commit 之后我们的 Git 仓库可以简化为下图:
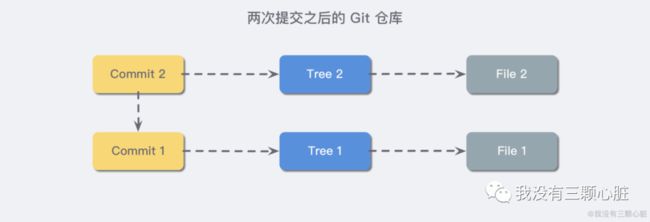
说明:其中因为我们 test 文件夹新增了文件,也就是出现了变化,所以就被标识成了新的 tree 类型的对象;
refs 目录
refs 目录存储都是引用文件,如本地分支,远端分支,标签等
refs/heads/xxx 本地分支
refs/remotes/origin/xxx 远端分支
refs/tags/xxx 本地tag
引用文件的内容都是 40 位长度的 commit
$ cat .git/refs/heads/master
9dfabac68470a588a4b4a78742249df46438874a
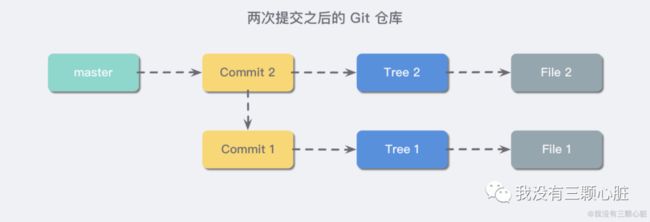
这就像是一个指针一样,它指向了你的最后一次提交(例如这里就指向了第二次提交的 commit),我们补充上分支信息,现在的 Git 仓库就会像下图所示:
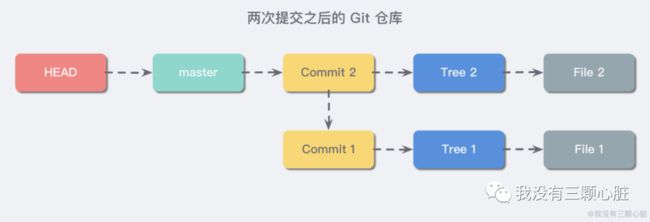
HEAD 目录
HEAD 目录下存储的是当前所在的位置,其内容是分支的名称:
$ cat HEAD
ref: refs/heads/master
我们再补充上 HEAD 的信息,现在的 Git 仓库如下图所示:
Git 中的冲突
您也在上面了解到了,在 Git 中分支是一种十分轻便的存在,仅仅是一个指针罢了,我们在广泛的使用分支中,不可避免的会遇到新创建分支的合并,这时候不论是选择 merge 还是 rebase,都有可能发生冲突,我们先来看一下冲突是如何产生的:
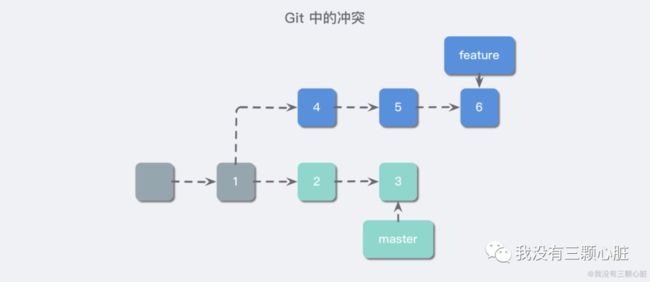
图上的情况,并不是移动分支指针就能够解决问题的,它需要一种合并策略。首先我们需要明确的是谁与谁的合并,是 2,3 与 4, 5, 6 两条线的合并吗?其实并不是的,真实合并的其实只有 3 和 6,因为每一次的提交都包含了项目完整的快照,即合并只是 tree 与 tree 的合并。
这可能说起来有点绕,我们可以先来想一个简单的算法,用来比较 3 和 6 的不同。如果我们只是单纯的比较 3 和 6 的信息,其实并没有意义,因为它们之间并不能确切的表达出当前的冲突状态。因此我们需要选取它们两个分支的分歧点(merge base)作为参考点,进行比较。
首先我们把 1 作为基础,然后把 1、3、6 中所有的文件做一个列表,然后依次遍历这个列表中的文件。我们现在拿列表中的一个文件进行举例,把在提交在 1、3、6 中的该文件分别称为版本1、版本3、版本6,可能出现如下几种情况:
1. 版本 1、版本 3、版本 6 的 “指纹” 值都相同:这种情况则说明没有冲突;2. 版本 3 or 版本 6 至少有一个与版本 1 状态相同(指的是指纹值相同或都不存在):这种情况可以自动合并,比如版本 1 中存在一个文件,在版本 3 中没有对该文件进行修改,而版本 6 中删除了这个文件,则以版本 6 为准就可以了;3. 版本 3 or 版本 6 都与版本 1 的状态不同:这种情况复杂一些,自动合并策略很难生效了,所以需要手动解决;
merge 操作
在解决完冲突后,我们可以将修改的内容提交为一个新的提交,这就是 merge。
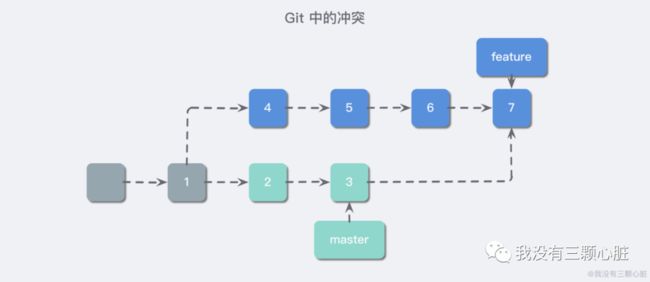
可以看到 merge 是一种不修改分支历史提交记录的方式,这也是我们常用的方式。但是这种方式在某些情况下使用起来不太方便,比如我们创建了一些提交发送给管理者,管理者在合并操作中产生了冲突,还需要去解决冲突,这无疑增加了他人的负担。
而我们使用 rebase 可以解决这种问题。
rebase 操作
假设我们的分支结构如下:
rebase 会把从 Merge Base 以来的所有提交,以补丁的形式一个一个重新打到目标分支上。这使得目标分支合并该分支的时候会直接 Fast Forward(可以简单理解为直接后移指针),即不会产生任何冲突。提交历史是一条线,这对强迫症患者可谓是一大福音。
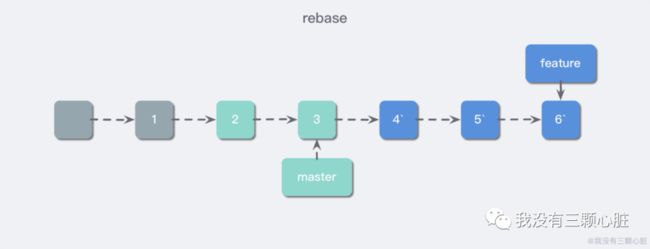
其实 rebase 主要是在 .git/rebase-merge 下生成了两个文件,分别为 git-rebase-todo 和 done 文件,这两个文件的作用光看名字就大概能够看得出来。git-rebase-todo 中存放了 rebase 将要操作的 commit,而 done 存放正操作或已操作完毕的 commit,比如我们这里,git-rebase-todo 存放了 4、5、6 三个提交。
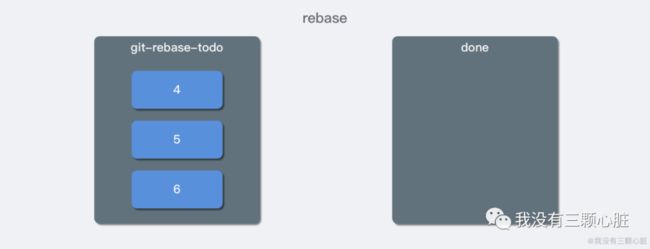
首先 Git 会把 4 这个 commit 放入 done,表示正在操作 4,然后将 4 以补丁的方式打到 3 上,形成了新的 4,这一步是可能产生冲突的,如果有冲突,需要解决冲突之后才能继续操作。 接着按同样的方式把 5、6 都放入 done,最后把指针移动到最新的提交 6 上,就完成了 rebase 的操作。
从刚才的图中,我们就可以看到 rebase 的一个缺点,那就是修改了分支的历史提交。如果已经将分支推送到了远程仓库,会导致无法将修改后的分支推送上去,必须使用 -f 参数(force)强行推送。
所以使用 rebase 最好不要在公共分支上进行操作。
Squash and Merge 操作
简单说就是压缩提交,把多次的提交融合到一个 commit 中,这样的好处不言而喻,我们着重来讨论一下实现的技术细节,还是以我们上面最开始的分支情况为例,首先,Git 会创建一个临时分支,指向当前 feature 的最新 commit。

然后按照上面 rebase 的方式,变基到 master 的最新 commit 处。
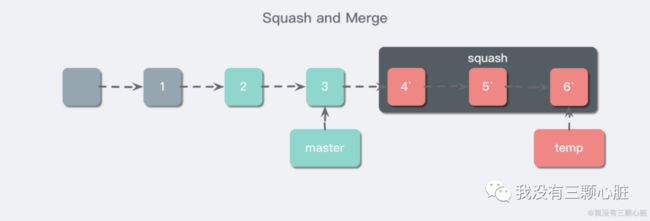
接着用 rebase 来 squash 之,压缩这些提交为一个提交。

最后以 fast forward 的方式合并到 master 中。
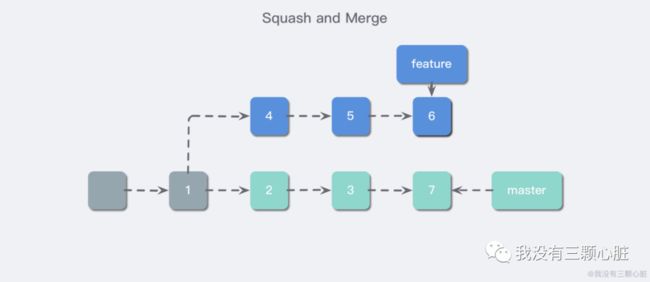
可见此时 master 分支多且只多了一个描述了这次改动的提交,这对于大型工程,保持主分支的简洁易懂有很大的帮助。
说明:想要了解更多的诸如 checkout、cherry-pick 等操作的话可以看看参考文章的第三篇,这里就不做细致描述了。
三、总结
通过上面的了解,其实我们已经大致的掌握了 Git 中的基本原理,我们的 Commit 就像是一个链表节点一样,不仅有自身的节点信息,还保存着上一个节点的指针,然后我们以 Branch 这样轻量的指针保存着一条又一条的 commit 链条,不过值得注意的是,objects 目录下的文件是不会自动删除的,除非你手动 GC,不然本地的 objects 目录下就保留着你当前项目完整的变化信息,所以我们通常都会看到 Git 上面的项目通常是没有 .git 目录的,不然仅仅通过 .git 目录理论上就可以还原出你的完整项目!
参考文章
https://www.liaoxuefeng.com/wiki/896043488029600/896202780297248 - 集中式vs分布式(廖雪峰的官方网站)
https://yanhaijing.com/git/2017/02/08/deep-git-3/ - 起底Git-Git内部原理
https://coding.net/help/doc/practice/git-principle.html - 使用原理视角看 Git