EDVR——代码调试+训练
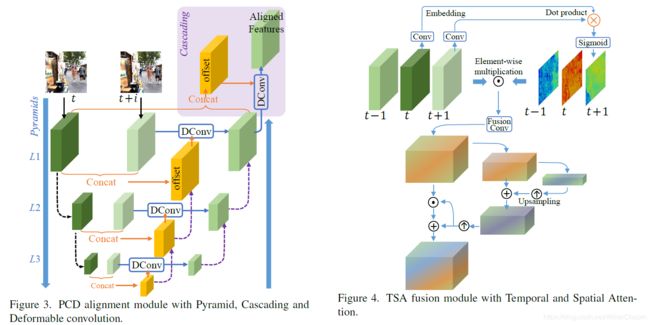
2019年CVPR的文章EDVR: Video Restoration with Enhanced Deformable Convolutional Networks,做的是视频处理(包括视频帧的超分辨率技术与去模糊),从结构上看能够处理应用于任意书品转换的强监督任务;文中最亮眼的地方在于他提出了保证时序一致性(temporal consistency)的新方法,不是使用光流(optical flow),而是借助可变形卷积对可追踪点进行追踪,成为PCD模块;以及提出了多帧处理时信息的融合的spatial-temporal维度的融合,成为TSA模块;代码见:EDVR.
小编受委托于一个师姐,帮她调试了代码。
(一)环境准备
老规矩哈,对每个项目新建一个虚拟环境,完了后再删除。虚拟环境的新建见我的另一篇博客:vid2vid 代码调试+训练+测试(debug+train+test)(一)测试篇。
(二)下载工程
$ git clone https://github.com/xinntao/EDVR.git
$ cd EDVR/目录结构如下,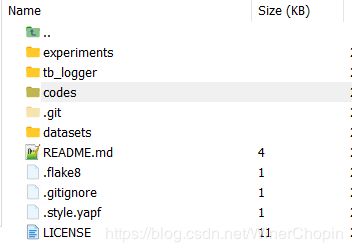 其中,experiments用来保存训练的模型和验证结果(checkpoints),tb_logger用来保存log日志;codes是主要的,包括了各种代码(包括train.py);datasets其实可以不管,用来存放数据集,但是后面你会发现数据集的引用是使用绝对路径(Σ( ° △ °|||)︴)!
其中,experiments用来保存训练的模型和验证结果(checkpoints),tb_logger用来保存log日志;codes是主要的,包括了各种代码(包括train.py);datasets其实可以不管,用来存放数据集,但是后面你会发现数据集的引用是使用绝对路径(Σ( ° △ °|||)︴)!
(三)数据集准备
这应该是本项目最繁琐的一部分了。
先 pip 安装 lmdb 。
准备好数据集后,修改代码“codes/data_scripts/create_lmdb_mp.py”。建议数据集结构如下:
"""
datasets
|--inputs
|--0000 # clip
|--00000000.png
|--00000001.png
...
|--00000029.png # 30 frames for each clip in our datasets
|--0001
|--00000000.png
...
...
|--GT
|--0000 # clip
|--00000000.png
|--00000001.png
...
|--00000029.png # 30 frames for each clip in our datasets
|--0001
|--00000000.png
...
...
"""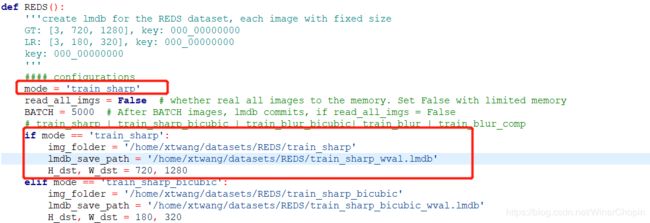
指定一个mode后,修改或者新增 if -else 结构,修改input或者GT的目录与保存路径。
针对input与GT分别执行create_lmdb_mp.py一次。
这之后,我们可以看看对应的"train_xxxx_wval.lmdb(是一个文件夹)"包含了什么。 ,其中的data.mdb就是图像数据了,是以字节形式存储,所以空间较小,读取快!lock.mdb仅是数据库中防止冲突的操作,当然代码中对数据的读取都是只读,所以影响不大。meata_info.pkl是一个字典,结构如下:(我们待会要使用它!)
,其中的data.mdb就是图像数据了,是以字节形式存储,所以空间较小,读取快!lock.mdb仅是数据库中防止冲突的操作,当然代码中对数据的读取都是只读,所以影响不大。meata_info.pkl是一个字典,结构如下:(我们待会要使用它!)
"""
{
'name': 'xxxxxxxxxxxx',
'resolution': '3_720_1280',
'keys': ['0000_00000000', '0000_00000001', ...]
}
"""仅仅如此还不够!因为meta_info.pkl的作用在于,帮助读取mdb文件中对应的图像数据。那么,我们还需要一个keys来告诉datatset 有哪一些keys,因此我们需要将生成的两个"train_xxxx_wval.lmdb"中的一个的meta_info.pkl复制到目录“codes/data/”下(因为input与GT的名字对应一般是相同的),注意到原先已经存在“REDS_trainval_keys.pkl”和“Vimeo90K_train_keys.pkl”了。我们这里是重命名为:EFRM_train_keys.pkl,待会在配置文件中的cache_keys指向它。
注意meta_info.pkl里存储的是字典,其中包含keys对应了文件名的列表;而原有的“REDS_trainval_keys.pkl”和“Vimeo90K_train_keys.pkl”则只是包含了列表;因此,我们还需要修改一下下面代码:
/* codes/data/REDS_dataset.py: __init__() */
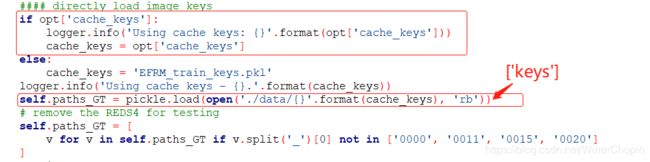
“cache_keys”是在配置文件中设置的,见(四), pickle是python读写pkl的一个包;我们载入刚刚的pkl后是一个字典,所以我们需要将在后面补上“[ 'keys' ]”表示只取keys键对应的值(文件名的列表)。
(四)设置配置文件
在路径“./codes/options/train/”下有两个“.yml”文件,这是参数配置文件。参数意义与配置如下:
#### general settings
name: 001_EDVRwoTSA_scratch_lr4e-4_600k_REDS_LrCAR4S # 为本次实验命名
use_tb_logger: true # 是否要输出和保存日志(一般都是要的吧~)
model: VideoSR_base # 使用的模型(不用改,这是作者文章的模型,通过参数配置可以构造文章所有的模型)
distortion: sr
scale: 4 # 输出大小是输入的4倍(不用改,实际上就是网络最后对应多了多少层上采样)
gpu_ids: [3] # 可以使用单核gpu(特别适合小编这种穷人)
#### datasets
datasets:
train:
name: REDS
mode: REDS
interval_list: [1] # 相邻帧:t-i, t, t+i
random_reverse: false # 是否随机对帧序取反
border_mode: false
dataroot_GT: /home/xyy/ssd/xwp/__temp__/train_EFGT_wval.lmdb # GT数据的绝对路径
dataroot_LQ: /home/xyy/ssd/xwp/__temp__/train_EF_wval.lmdb # 输入数据的绝对路径
cache_keys: EFRM_train_keys.pkl # 前面我们自定义的训练数据的文件名汇总(存储的是:List: ['0000_00000000', '0000_00000001', ..., '0001_00000000', ...])
N_frames: 5 # 输入的帧数(中间帧为key)
use_shuffle: true
n_workers: 3 # per GPU
batch_size: 8
GT_size: 256
LQ_size: 256 # 如果做得不是SR的任务,而是deblur/derain等输入输出的分辨率一样的话,这里要求设置:GT_size = LQ_size,具体数值不管;而如果是SR任务,则需要保证:GT_size/LQ_size = scale
use_flip: true # 随机翻转(水平/垂直)做数据增强
use_rot: true # 随机旋转
color: RGB
#### network structures
network_G:
which_model_G: EDVR
nf: 64 # 第一个conv的通道数
nframes: 5
groups: 8
front_RBs: 5
back_RBs: 10
predeblur: true # 是否使用一个预编码层,它的作用是对输入 HxW 经过下采样得到 H/4xW/4 的feature,以便符合后面的网络
HR_in: true # 很重要!!只要你的输入与输出是同样分辨率,就要求设置为true
w_TSA: true # 是否使用TSA模块
#### path
path:
pretrain_model_G: ~ # 假如没有与训练的模型,设置为~(表示None)
strict_load: true
resume_state: ~
#### training settings: learning rate scheme, loss
train:
lr_G: !!float 4e-4
lr_scheme: CosineAnnealingLR_Restart
beta1: 0.9
beta2: 0.99
niter: 600000
warmup_iter: -1 # -1: no warm up
T_period: [150000, 150000, 150000, 150000]
restarts: [150000, 300000, 450000]
restart_weights: [1, 1, 1]
eta_min: !!float 1e-7
pixel_criterion: cb
pixel_weight: 1.0
val_freq: !!float 2e3
manual_seed: 0
#### logger
logger:
print_freq: 10 # 每多少个iterations打印日志
save_checkpoint_freq: !!float 2e3 # 没多少个iterations保存模型
(五) 修改代码
下面小编将展示次工程比较不友好的一个地方。
以“codes/data/REDS_dataset.py”为例,在函数__getitem__(self, index)中有一个坑。
(本项目读取数据的规则是:在前面部分将所有的数据封装成lmdb的形式,需要通过key(图片名,无后缀)进行读取;在dataset的__getitem__中,是先将所有的keys读入(就是前面我们需要自己准备的"XXX_keys.pkl"文件)),然后每次读取连续的几个keys,再经过_read_img_mc_BGR函数去获取图像数组。
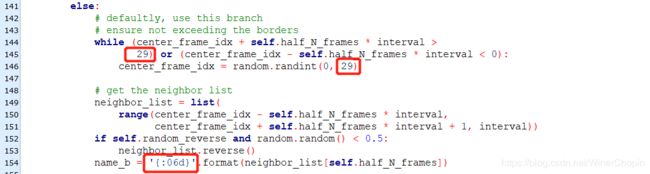
这里有几个数值我们需要修改:
1)上面的两个红框,原本的数值是99;这是因为作者用的训练数据每一个clip中含有100帧(xxxx_00000000, xxxx_00000001, ..., xxxx_00000099) ,为了保证不读取到两个clips的帧,需要对帧的索引做检查。师姐的数据中每个clip的帧数是30,所以这里要设置成29.
2)假如读者使用与作者相同的命名格式:“xxxx_xxxxxxxx”,那么底下的框就不需要修改;但假如不是,像师姐的命名是“xxxx_xxxxxx”,所以这里就需要改成“{:06d}”而不是原来的“{:06d}”。
这里最好奇的是,上面的“99”为什么不设置成一个超参数?
(六)训练
python -m torch.distributed.launch --nproc_per_node=2 --master_port=21688 train.py -opt options/train/<我自己的配置文件>.yml --launcher pytorch
# 注意这里的 master_port 不是固定的,根据自己服务器当前的端口使用,赋予一个没有使用的端口即可;否则会发生系统错误,甚至无法fork出子进程