MySQL 8.0 初学与基础项目实践
本文主要参考 《SQL必知必会(第四版)》 以及**MySQL 8.0 Reference Manual**
不再更新 --Last update: 2019/05/07:更新项目12
欢迎大家评论交流
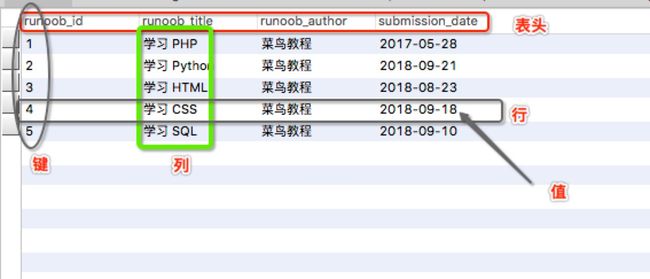
一.数据库基础知识
1.数据库定义
数据库(database),保存有组织的数据的容器(通常是一个文件或一组文件)。
最简单的办法是将数据库想象为一个文件柜。这个文件柜是一个存放数据的物理位置,不管数据是什么,也不管数据是如何组织的。
2.关系型数据库
关系数据库(Relational database),是创建在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。标准数据查询语言SQL就是一种基于关系数据库的语言,这种语言执行对关系数据库中数据的检索和操作。
关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
3.表
表(table),某种特定类型数据的结构化清单。
你往文件柜里放资料时,并不是随便将它们扔进某个抽屉就完事了,而是在文件柜中创建文件,然后将相关的资料放入特定的文件中。在数据库领域中,这种文件称为表。表是一种结构化的文件,可用来存储某种特定类型的数据。表可以保存顾客清单、产品目录,或者其他信息清单。
数据库中的每个表都有一个名字来标识自己。这个名字是唯一的,即数据库中没有其他表具有相同的名字。
4.行
行(row),表中的一个记录。
表中的数据是按行存储的,所保存的每个记录存储在自己的行内。如果将表想象为网格,网格中垂直的列为表列,水平行为表行。例如,顾客表可以每行存储一个顾客。表中的行编号为记录的编号。
5.列
列(column),表中的一个字段。所有表都是由一个或多个列组成的。
表由列组成。列存储表中某部分的信息。理解列的最好办法是将数据库表想象为一个网格,就像个电子表格那样。网格中每一列存储着某种特定的信息。例如,在顾客表中,一列存储顾客编号,另一列存储顾客姓名,而地址、城市、州以及邮政编码全都存储在各自的列中。
6.主键
主键(primary key),一列(或一组列),其值能够唯一标识表中每一行。
表中每一行都应该有一列(或几列)可以唯一标识自己。唯一标识表中每行的这个列(或这几列)称为主键。主键用来表示一个特定的行。没有主键,更新或删除表中特定行就极为困难,因为你不能保证操作只涉及相关的行。
7.外键
外键(foreign key)。其实在关系数据库中,每个数据表都是由关系来连系彼此的关系,父数据表(Parent Entity)的主键(primary key)会放在另一个数据表,当做属性以创建彼此的关系,而这个属性就是外键。
比如,学生跟老师之间是教学的关系,学生数据表会有个属性叫指导老师(FK),而这个值就是对应到老师数据表的老师代号(PK),学生的指导老师就是外键。
二.MySQL数据库管理系统
MySQL 是一个关系型数据库管理系统,由瑞典 MySQLAB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
1.数据库
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理的大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
2.数据表
在关系数据库中,数据库表是一系列二维数组的集合,用来代表和储存数据对象之间的关系。表是构成表空间的基本结构,由区间构成。它由纵向的列和横向的行组成,例如一个有关作者信息的名为 authors 的表中,每个列包含的是所有作者的某个特定类型的信息,比如“姓氏”,而每行则包含了某个特定作者的所有信息:姓、名、住址等等。
对于特定的数据库表,列的数目一般事先固定,各列之间可以由列名来识别。而行的数目可以随时、动态变化,每行通常都可以根据某个(或某几个)列中的数据来识别,称为候选键。
3.视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
MySQL从版本5起开始支持视图。
输入▼
SELECT cust_name, cust_contact
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num
AND prod_id = 'RGAN01';
此查询用来检索订购了某种产品的顾客。任何需要这个数据的人都必须理解相关表的结构,知道如何创建查询和对表进行联结。检索其他产品(或多个产品)的相同数据,必须修改最后的WHERE子句。
现在,假如可以把整个查询包装成一个名为ProductCustomers的虚拟表,则可以如下轻松地检索出相同的数据:
输入▼
SELECT cust_name, cust_contact
FROM ProductCustomers
WHERE prod_id = 'RGAN01';
这就是视图的作用。ProductCustomers是一个视图,作为视图,它不包含任何列或数据,包含的是一个查询(与上面用以正确联结表的相同查询)。
4.存储过程
迄今为止,我们使用的大多数 SQL语句都是针对一个或多个表的单条语句。并非所有操作都这么简单,经常会有一些复杂的操作需要多条语句才能完成,例如以下的情形。
- 为了处理订单,必须核对以保证库存中有相应的物品。
- 如果物品有库存,需要预定,不再出售给别的人,并且减少物品数据以反映正确的库存量。
- 库存中没有的物品需要订购,这需要与供应商进行某种交互。
- 关于哪些物品入库(并且可以立即发货)和哪些物品退订,需要通知相应的顾客。
执行这个处理需要针对许多表的多条 SQL语句。此外,需要执行的具体 SQL语句及其次序也不是固定的,它们可能会根据物品是否在库存中而变化。
那么,怎样编写代码呢?可以单独编写每条 SQL语句,并根据结果有条件地执行其他语句。在每次需要这个处理时(以及每个需要它的应用中),都必须做这些工作。
可以创建存储过程。简单来说,存储过程就是为以后使用而保存的一条或多条 SQL语句。可将其视为批文件,虽然它们的作用不仅限于批处理。
三.语句
1.SELECT语句
SQL语句是由简单的英语单词构成的。这些单词称为关键字,每个 SQL语句都是由一个或多个关键字构成的。最经常使用的SQL语句大概就是 SELECT语句了。它的用途是从一个或多个表中检索信息。
为了使用SELECT检索表数据,必须至少给出两条信息——想选择什么,以及从什么地方选择。
SELECT columna columnb FROM mytable;
上面这行语句,如果忘记两个列名之间的逗号,则会出现一个微妙的问题:MySQL将选择第二个列名,即columnb,但是返回的是columna所有行的记录。
返回的数据中也许会包含重复的记录,那么如何检索出不同的值?办法就是使用 DISTINCT关键字,顾名思义,它指示数据库只返回不同的值。
SELECT DISTINCT vend_id FROM Products;
如果使用DISTINCT关键字,它必须直接放在列名的前面。它将只返回不同(具有唯一性)的行。
SELECT语句返回指定表中所有匹配的行,很可能是每一行。如果你只想返回第一行或者一定数量的行,该怎么办呢?
SELECT TOP 5 prod_name FROM Products; #通过TOP关键字只返回前5行
SELECT prod_name FROM Products LIMIT 5 OFFSET 5; # 返回从第5行起的5行记录
可以使用TOP关键字来限制最多返回多少行。或者,我更喜欢的是下面这种方式,因为更加灵活。LIMIT 5 OFFSET 5,LIMIT指定返回的行数,OFFSET指定从哪儿开始。
2.CASE语句
存储程序的CASE语句实现了复杂的条件构造。
CASE case_value # 或者没有case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE
3.ORDER子语
其实,检索出的数据并不是随机显示的。如果不排序,数据一般将以它在底层表中出现的顺序显示,这有可能是数据最初添加到表中的顺序。为了明确地排序用SELECT语句检索出的数据,可使用ORDER BY子句。
ORDERBY子句取一个或多个列的名字,据此对输出进行排序。
SELECT prod_name FROM Products ORDER BY prod_name;
这样,将对prod_name列以字母顺序排序数据。在指定一条 ORDER BY子句时,应该保证它是 SELECT语句中最后一条子句。如果它不是最后的子句,将会出现错误消息。
除了能用列名指出排序顺序外,ORDER BY还支持按相对列位置进行排序。ORDER BY 2,3 表示按SELECT清单中的第二个列进行排序,再按第三个列进行排序。
SELECT prod_id, prod_price, prod_name FROM Products ORDER BY 2, 3;
数据排序不限于升序排序(从 A到 Z),这只是默认的排序顺序。还可以使用ORDER BY子句进行降序(从 Z到 A)排序。为了进行降序排序,必须指定DESC关键字。
SELECT prod_id, prod_price, prod_name FROM Products ORDER BY prod_price DESC;
3.WHERE子语
数据库表一般包含大量的数据,很少需要检索表中的所有行。通常只会根据特定操作或报告的需要提取表数据的子集。只检索所需数据需要指定搜索条件(search criteria),搜索条件也称为过滤条件(filter condition)。
在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。WHERE子句在表名(FROM子句)之后给出,如下所示:
SELECT prod_name, prod_price FROM Products WHERE prod_price = 3.49;
SQL支持表 4-1列出的所有条件操作符。

-
AND与OR操作符,用来联结或改变 WHERE子句中的子句的关键字,也称为逻辑操作符(logical operator)。SQL允许给出多个WHERE子句。这些子句有两种使用方式,即以AND子句或OR子句的方式使用。
SELECT prod_name, prod_price FROM Products WHERE vend_id = ‘DLL01’
OR vend_id = ‘BRS01’ AND prod_price >= 10; #<=>(vend_id = ‘DLL01’)
OR (vend_id = ‘BRS01’ AND prod_price) #实际上我们想实现的是(vend_id = ‘DLL01’
OR vend_id = ‘BRS01’) AND prod_price >= 10SQL(像多数语言一样)在处理OR操作符前,优先处理AND操作符。所以为了避免操作符被错误地组合了,需使用圆括号对操作符进行明确分组。
-
IN操作符,IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN取一组由逗号分隔、括在圆括号中的合法值。N操作符可以完成与OR相同的功能,下面两个语句功能一致。
SELECT prod_name, prod_price FROM Products WHERE vend_id IN ( 'DLL01', 'BRS01' ) ORDER BY prod_name; /*********************************************************/ SELECT prod_name, prod_price FROM Products WHERE vend_id = 'DLL01' OR vend_id = 'BRS01' ORDER BY prod_name; -
NOT操作符,WHERE子句中的NOT操作符有且只有一个功能,那就是否定其后所跟的任何条件。因为NOT从不单独使用(它总是与其他操作符一起使用),所以它的语法与其他操作符有所不同。NOT关键字可以用在要过滤的列前,而不仅是在其后。
SELECT prod_name FROM Products WHERE NOT vend_id = 'DLL01' ORDER BY prod_name; -
LIKE操作符,通配符本身实际上是 SQL的WHERE子句中有特殊含义的字符,SQL支持几种通配符。为在搜索子句中使用通配符,必须使用LIKE操作符。LIKE指示 DBMS,后跟的搜索模式利用通配符匹配而不是简单的相等匹配进行比较。
通配符搜索只能用于文本字段(字符串),非文本数据类型字段不能使用通配符搜索。
-
百分号(%)通配符,最常使用的通配符是百分号(%)。在搜索串中,%表示任何字符出现任意次数。例如,为了找出所有以词Fish起头的产品,可发布以下SELECT语句:
SELECT prod_id, prod_name FROM Products WHERE prod_name LIKE 'Fish%';或者
SELECT prod_name FROM Products #根据邮件地址的一部分来查找电子邮件 WHERE prod_name LIKE 'A%@abcd.com'; -
下划线(_)通配符,另一个有用的通配符是下划线。下划线的用途与%一样,但它只匹配单个字符,而不是多个字符。
-
方括号([ ])通配符,方括号([])通配符用来指定一个字符集,它必须匹配指定位置(通配符的位置)的一个字符。
-
4.函数
与大多数其他计算机语言一样,SQL也可以用函数来处理数据。函数一般是在数据上执行的,为数据的转换和处理提供了方便。
时间函数、数值函数、字符串函数的具体释义及使用可见link
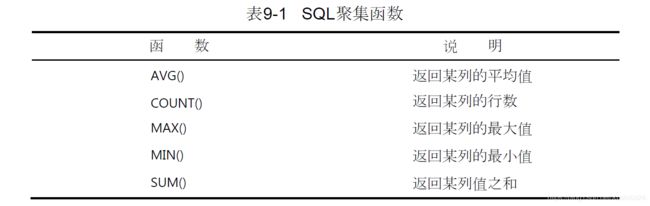
聚集函数,对某些行运行的函数,计算并返回一个值,主要有以下几个:
5.GROUP BY子句
分组是使用SELECT语句的GROUP BY子句建立的。理解分组的最好办法是看一个例子:
SELECT vend_id, COUNT(*) AS num_prods FROM Products
GROUP BY vend_id;
------输出如下-----
vend_id num_prods
------- ---------
BRS01 3
DLL01 4
FNG01 2
上面的 SELECT语句指定了两个列:vend_id包含产品供应商的ID,num_prods为计算字段(用 COUNT(*)函数建立)。GROUP BY子句指示DBMS按vend_id排序并分组数据,统计每个vend_id有多少条记录。
6.HAVING子句
HAVING非常类似于WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是,WHERE过滤行,而HAVING过滤分组。
SELECT cust_id, COUNT(*) AS orders FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
7.关于注释
SELECT prod_name -- 这是一条注释
FROM Products;
# 这是一条注释
SELECT prod_name
FROM Products;
/* SELECT prod_name, vend_id
FROM Products; */
SELECT prod_name
FROM Products;
四.项目实践
1.查找重复的电子邮箱(难度:简单)
创建 email表,并插入如下三行数据
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
编写一个 SQL 查询,查找 Email 表中所有重复的电子邮箱。
根据以上输入,你的查询应返回以下结果:
| [email protected] |
说明:所有电子邮箱都是小写字母。
代码如下:
create table email(
Id int not null,
Email varchar(100),
primary key(Id));
insert into email values('1','[email protected]'),('2','[email protected]'),('3','[email protected]');
select Email from email group by Email having count(Email)>1;
2.查找大国(难度:简单)
创建如下 World 表
| name | continent | area | population | gdp |
|---|---|---|---|---|
| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
| Albania | Europe | 28748 | 2831741 | 12960000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000 |
| Andorra | Europe | 468 | 78115 | 3712000 |
| Angola | Africa | 1246700 | 20609294 | 100990000 |
如果一个国家的面积超过300万平方公里,或者(人口超过2500万并且gdp超过2000万),那么这
编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
| name | population | area |
|---|---|---|
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
代码如下:
create table country(
name varchar(100) not null,
continent varchar(20),
area int,
population int,
gdp int,
primary key(name));
insert into country values
('Afghanistan','Asia',652230,25500100,20343000),
('Albania','Europe',28748,2831741,12960000),
('Algeria','Africa',2381741,37100000,188681000),
('Andorra','Europe',468,78115,3712000),
('Angola','Africa',1246700,20609294,100990000);
select name,population,area from country
where area>3000000 or (population>25000000 and gdp>20000000);
3.超过5名学生的课(难度:简单)
创建如下所示的courses 表 ,有: student (学生) 和 class (课程)。
例如,表:
| student | class |
|---|---|
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
| A | Math |
编写一个 SQL 查询,列出所有超过或等于5名学生的课。
应该输出:
| class |
|---|
| Math |
Note:
学生在每个课中不应被重复计算。
代码如下:
CREATE TABLE courses(
student VARCHAR(100) NOT NULL,
class VARCHAR(100) NOT NULL);
INSERT INTO courses VALUES('A','MATH'),
('B', 'English'),
('C','Math'),
('D','Biology'),
('E','Math'),
('F','Computer'),
('G','Math'),
('H','Math'),
('I','Math'),
('A','Math');
SELECT class
FROM courses
GROUP BY class
HAVING COUNT(DISTINCT student)>=5;
4.交换工资(难度:简单)
创建一个 salary表,如下所示,有m=男性 和 f=女性的值 。
例如:
| id | name | sex | salary |
|---|---|---|---|
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求使用一个更新查询,并且没有中间临时表。
运行你所编写的查询语句之后,将会得到以下表:
| id | name | sex | salary |
|---|---|---|---|
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
代码如下:
CREATE TABLE salary(
id INT NOT NULL,
name VARCHAR(100),
sex enum('m','f'),
salary int,
PRIMARY KEY(id));
INSERT INTO salary VALUES(1,'A','m',2500),
(2,'B','f',1500),
(3,'C','m',5500),
(4,'D','f',500);
UPDATE salary
SET sex =
CASE sex
WHEN 'm'
THEN 'f'
ELSE 'm'
END;
5.组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person
| 列名 | 类型 |
|---|---|
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
PersonId 是上表主键
表2: Address
| 列名 | 类型 |
|---|---|
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State
代码如下:
CREATE TABLE person(
personID INT NOT NULL,
firstname VARCHAR(100),
lastname VARCHAR(100),
PRIMARY KEY(ID));
INSERT INTO person values(1,'zhao','da'),
(2,'qian','er'),
(3,'sun','san');
CREATE TABLE address(
addressID INT NOT NULL,
personID INT NOT NULL,
city VARCHAR(100),
state VARCHAR(100),
PRIMARY KEY(addressID));
INSERT INTO address VALUES(12201,1,'Albany','NY'),
(21401,3,'Annapolis','MD'),
(30301,2,'Atlanta','GA');
SELECT firstname,lastname,city,state
FROM address INNER JOIN person
ON person.personID=address.personID;
6.删除重复的邮箱(难度:简单)
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person表应返回以下几行:
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
代码如下:
CREATE TABLE email2(
ID INT NOT NULL,
EMAIL VARCHAR(100) NOT NULL,
PRIMARY KEY(ID));
INSERT INTO email2 VALUES(1,'[email protected]'),
(2,'[email protected]'),
(3,'[email protected]');
DELETE tmp1
FROM email2 tmp1,email2 tmp2
where tmp1.EMAIL=tmp2.EMAIL
AND tmp1.ID>tmp2.ID;
SELECT * from email2;
AND tmp1.ID>tmp2.ID;
SELECT * from email2;
7.各部门工资最高的员工(难度:中等)
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
创建Department 表,包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| Sales | Henry | 80000 |
代码如下:
CREATE TABLE
IF NOT EXISTS Employee (
Id INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
Salary INT NOT NULL,
DepartmentId INT NOT NULL,
PRIMARY KEY (Id)
);
CREATE TABLE
IF NOT EXISTS Department (
Id INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
PRIMARY KEY (Id)
);
INSERT INTO Employee
VALUES
(1, 'Joe', 70000, 1),
(2, 'Henry', 80000, 2),
(3, 'Sam', 60000, 2),
(4, 'Max', 90000, 1);
INSERT INTO Department
VALUES
(1, 'IT'),
(2, 'Sales');
SELECT
Department. NAME AS Department,
Employee. NAME AS Employee,
Salary
FROM
Employee,
Department
WHERE
Department.Id = Employee.DepartmentId
AND Salary IN (
SELECT
MAX(Salary)
FROM
Employee
WHERE
DepartmentId = Department.Id
GROUP BY
DepartmentId
)
ORDER BY
Salary DESC;
Department,
Employee,
max(Salary) AS Salary
FROM
(
SELECT
d. NAME AS Department,
e. NAME AS Employee,
Salary
FROM
Department d
INNER JOIN Employee e ON d.Id = e.DepartmentId
) AS a
GROUP BY
Department, Employee;
*/
SELECT
Department. NAME,
MAX(Salary)
FROM
Employee,
Department
WHERE
Employee.DepartmentId = Department.Id
GROUP BY
Employee.DepartmentId;
8.换座位(难度:中等)
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
| id | student |
|---|---|
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
假如数据输入的是上表,则输出结果如下:
| id | student |
|---|---|
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
代码如下:
CREATE TABLE
IF NOT EXISTS seat (
id INT NOT NULL,
student VARCHAR (20) NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO seat
VALUES
(1, 'Abbot'),
(2, 'Doris'),
(3, 'Emerson'),
(4, 'Green'),
(5, 'Jeames');
SELECT
*
FROM
(
SELECT
id,
student
FROM
seat
WHERE
id % 2 = 1
AND id = (SELECT count(*) FROM seat) # determine if exchange the last student seat/ output the odd last one
UNION
SELECT
id + 1,
student
FROM
seat
WHERE
id % 2 = 1
AND id != (SELECT count(*) FROM seat) # exchange the former one
UNION
SELECT
id - 1,
student
FROM
seat
WHERE
id % 2 = 0 # exchange the later on
) s1
ORDER BY
id;
9. 分数排名(难度:中等)
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
| Id | Score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
代码如下:
CREATE TABLE
IF NOT EXISTS score (
Id INT NOT NULL,
Score NUMERIC (3, 2) NOT NULL,
PRIMARY KEY (Id)
);
INSERT INTO score
VALUES
(1, 3.50),
(2, 3.65),
(3, 4.00),
(4, 3.85),
(5, 4.00),
(6, 3.65);
SELECT
FORMAT(Score, 2) AS Score,
(
SELECT
COUNT(DISTINCT Score)
FROM
score
WHERE
Score >= s.Score # current score's level
) AS 'Rank'
FROM
score AS s
ORDER BY
Score DESC;
10.行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
| Id | Client_Id | Driver_Id | City_Id | Status | Request_at |
|---|---|---|---|---|---|
| 1 | 1 | 10 | 1 | completed | 2013-10-01 |
| 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-01 |
| 3 | 3 | 12 | 6 | completed | 2013-10-01 |
| 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-01 |
| 5 | 1 | 10 | 1 | completed | 2013-10-02 |
| 6 | 2 | 11 | 6 | completed | 2013-10-02 |
| 7 | 3 | 12 | 6 | completed | 2013-10-02 |
| 8 | 2 | 12 | 12 | completed | 2013-10-03 |
| 9 | 3 | 10 | 12 | completed | 2013-10-03 |
| 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-03 |
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
| Users_Id | Banned | Role |
|---|---|---|
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
| Day | Cancellation Rate |
|---|---|
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
代码如下:
CREATE TABLE
IF NOT EXISTS Trips (
Id INT NOT NULL,
Client_Id INT NOT NULL,
Driver_Id INT NOT NULL,
City_Id INT NOT NULL,
STATUS ENUM (
'completed',
'cancelled_by_driver',
'cancelled_by_client'
) NULL,
Request_at DATE NOT NULL,
PRIMARY KEY (Id),
FOREIGN KEY (Client_Id) REFERENCES Users (Users_Id),
FOREIGN KEY (Driver_Id) REFERENCES Users (Users_Id)
);
CREATE TABLE
IF NOT EXISTS Users (
Users_Id INT NOT NULL,
Banned VARCHAR (5) NOT NULL,
Role ENUM (
'client',
'driver',
'partner'
) NULL,
PRIMARY KEY (Users_Id)
);
INSERT INTO Trips
VALUES
(
1,
1,
10,
1,
'completed',
'2013-10-01'
),
(
2,
2,
11,
1,
'cancelled_by_driver',
'2013-10-01'
),
(
3,
3,
12,
6,
'completed',
'2013-10-01'
),
(
4,
4,
13,
6,
'cancelled_by_client',
'2013-10-01'
),
(
5,
1,
10,
1,
'completed',
'2013-10-02'
),
(
6,
2,
11,
6,
'completed',
'2013-10-02'
),
(
7,
3,
12,
6,
'completed',
'2013-10-02'
),
(
8,
2,
12,
12,
'completed',
'2013-10-03'
),
(
9,
3,
10,
12,
'completed',
'2013-10-03'
),
(
10,
4,
13,
12,
'cancelled_by_driver',
'2013-10-03'
);
INSERT INTO Users
VALUES
(1, 'No', 'client'),
(2, 'Yes', 'client'),
(3, 'No', 'client'),
(4, 'No', 'client'),
(10, 'No', 'driver'),
(11, 'No', 'driver'),
(12, 'No', 'driver'),
(13, 'No', 'driver');
SELECT
t.Request_at AS 'Day',
ROUND(
(
SUM(
CASE
WHEN t. STATUS LIKE 'cancelled%' THEN
1
ELSE
0
END
)
) / COUNT(*),
2
) AS 'Cancellation Rate'
FROM
Trips AS t
INNER JOIN Users AS u ON u.Users_Id = t.Client_Id
AND u.Banned = 'No'
GROUP BY
t.Request_at;
11.各部门前3高工资的员工(难度:中等)
将7中的employee表清空,重新插入以下数据(其实是多插入5,6两行):
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
此外,请考虑实现各部门前N高工资的员工功能。
代码如下:
TRUNCATE TABLE Employee;
# Insert values again
(
SELECT
d. NAME AS Department,
e. NAME AS Employee,
e.Salary AS Salary
FROM
Department AS d,
Employee AS e
WHERE
e.DepartmentId = 1
AND e.DepartmentId = d.Id
ORDER BY
Department,
Salary DESC
LIMIT 3
)
UNION
(
SELECT
d. NAME AS Department,
e. NAME AS Employee,
e.Salary AS Salary
FROM
Department AS d,
Employee AS e
WHERE
e.DepartmentId = 2
AND e.DepartmentId = d.Id
ORDER BY
Department,
Salary DESC
LIMIT 3
);
12.分数排名(难度:中等)
对9中的分数表,实现排名功能,但是排名是非连续的,如下:
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 3 |
| 3.65 | 4 |
| 3.65 | 4 |
| 3.50 | 6 |
代码如下:
SELECT
format(Score, 2) AS Score,
(
SELECT
count(*)
FROM
score
WHERE
Score > s.Score
) + 1 AS 'Rank'
FROM
score s
ORDER BY
Score DESC;