深入浅出分布式存储性能优化方案
Latency指标对于存储系统性能的重要性
我们分析一套分布式存储系统,主要从可靠性、易用性和性能三个维度着手分析。
可靠性:是存储系统的基石,一款存储系统至少需要提供99.99%的数据可靠性,数据丢失或者错乱对于存储系统是致命的,对大数据、云存储这样大规模的分布式集群
易用性:是系统管理员最关心的问题,主要体现产品设计、故障处理和系统的扩展性
性能:如果可靠性是存储系统的基石,那么性能是存储系统的灵魂,对一款优秀存储系统,高可靠与高性能缺一不可
本文将从性能的维度分析分布式存储系统,那么如何分析一款分布式存储系统的性能呢?
让我们先了解评测存储系统的主要参数:IO Type、IO Mode、IO Size和IO Concurrency;这些参数的值的不同组合对应了不同的业务模型,场景的模型如下表所示:
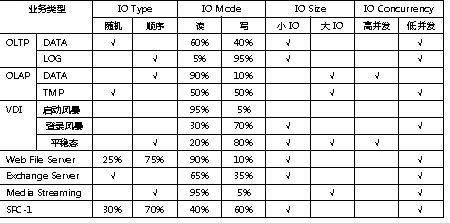
表一:常用业务类型
注1:SPC-1,主要衡量存储系统在随机小IO负荷下的IOPS,而SPC-2则主要衡量在各种高负荷连续读写应用场合下存储系统的带宽。
注2:SPC-1将测试区域抽象为ASU,ASU分为三类:ASU1临时数据区域,ASU2用户数据区域和ASU3日志区域。
根据上表可知,由于业务类型是多种多样的,很难做到全面覆盖,通常使用三个性能指标:IOPS、Throughput和Latency来测评一款存储系统。通常,大IO使用指标Throughput来评测系统性能;小IO使用IOPS来评测系统性能。那么,性能指标:Latency的作用是什么?并且Latency指标往往容易在性能评测中被忽视。在这里介绍一下性能指标Latency的作用,用户评测一款存储系统之前,测试系统的IOPS和Throughput都很满意,但上线后,反映业务系统卡顿,其核心便是Latency过高。
下面引用一段网络博文:“即使供应商新型的存储系统在60/40混合读写条件下能奇迹般地实现1,000,000 4K随机IOPS,我还是想知道它的延迟是多少。Dimitris Krekoukias在最近的一篇关于IOPS和延迟的博客中写道:某供应商的系统能实现15000的IOPS,平均延迟为25ms。但是数据库引擎还是提示高水平I/O等待时间。
一位批评家在Krekoukias's Ruptured Monkey博客中详细叙述了只有在延迟小于4ms的情况下,信用卡处理器才不会减慢防诈骗或提款授权等进程。”同样,冬瓜哥在博文中讲解了如何理解时延,这里简单复述下:“每秒执行 1000 个 IO ,平均每个 IO 的执行耗费了 1000ms/1000IOPS=1ms ,所以每个 IO 的平均时延就是 1ms,这有什么不对呢?”上面的计算忽略了并发度这个因素。对于异步、高并发的业务,这个存储系统可以满足业务需求。但基于OLTP和OLAP的业务一般是同步的且低并发的业务,这款存储系统是否满足业务需求,这仍是一个问号。
通过上面的资料我们得出:实现高性能的关键是高IOPS和低Latency的结合。当存储系统提供更高的IOPS时,单IO的时延不应同步提高过多,否则将影响业务系统的性能。比如JetStress建议平均时延应小于20ms,最大值应小于100ms。
分布式存储中的Latency问题
我们先看下传统存储的时延,在传统存储系统中,其IO时延有着天然的优势。优势一是物理IO路径较短,通常为机头控制器后端再挂载JBOD;优势二是使用Raid5、RAID10或者RAID 2.0等数据保护算法,这些算法是基于Disk或者Chunk,比基于故障域的副本模式开销小很多。
图一:传统SAN IO架构

图二:Raid 2.0原理
在分布式存储中,由多台或者上百台的服务器组成,且使用副本模式。所以一个IO通过网络,在多个副本服务器上处理,且每个副本都有数据一致性检查算法,这些操作都将增加IO的时延。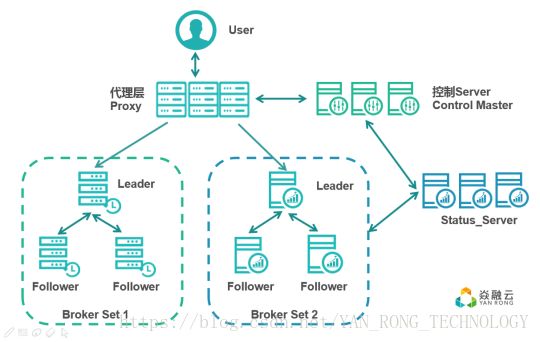

图三:分布式集群IO流
从上图可知,三副本的分布式存储系统,一个写IO,需要从写Leader和写两个Follower完成后才返回给user;
分布式存储的副本模式对性能的影响到底有多大呢?为了感性的认识,我们先看两个性能对比:

图四:在本地存储跑OLTP业务

图五:在分布式存储上跑OLTP业务
根据上面两图的性能数据,分布式存储的IO时延的确很高。
分布式存储系统的另一个性能问题是IO的抖动,体现在时延上是平均时延与最小时延和最大时延偏离值很大,出现这个问题的主要原因是分布系统的架构原理与IO请求处理不当引起;比如,副本之间的强一致性,只要有一个副本响应稍慢,整个IO的时延将增加或者一致性算法引起IO短暂堆积,IO都发送到相同的存储节点。
焱融自研分布式存储cache引擎
对于如何降低分布式存储Latency,其实是一个系统又复杂的事情,牵一发而动全身,让我们先来看看阿里云云存储和华为的闪存阵列都做了哪些工作:
阿里云ESSD
-
硬件升级:服务器、SSD、网络(40GB/s, 25GB/s)、网络交换机、RDMA协议
-
网络通信框架:Luna, RDMA+用户态驱动+私有I/O协议
-
线程模型改进:用户态驱动,加入co-routine协程,加run to completion模式
-
数据布局:采用追加写,修改元数据模式(元数据记录数据的位置)
-
更细致的分层和抽象;针对不同的IO属性,提供更定制化的策略模块,满足不同的IO Profile需求
华为闪存OceanStor Dorado V3
-
硬件优化,硬盘框采用12Gbps的SAS直连控制框模式;精简NVMe SSD协议
-
对时延敏感的关键处理不被频繁打断、不被其他任务阻塞
-
处理器分组技术,将处理器中的各个核按照业务需求划分成不同的分区,关键业务在各个分区上运行,不被打断
-
为了保证请求的稳定低时延,读请求和写入cache的写请求可以在存储系统内优先拥有各种关键的处理资源,包括:cpu、内存、访盘并发等;cache异步刷盘的请求优先级低
-
有效聚合,保证大块顺序写入SSD,实现请求处理效率最优
-
冷热数据分区,减少写放大,提升性能
-
充分发挥SSD的垃圾回收机制,在擦除块时减少数据搬移量,较少对SSD的性能和寿命的影响
等等。。。
可见通常提高性能,优化时延的主要方法概括起来有以下几个方面:
-
硬件升级,诸如NVMe,RDMA
-
优化IO路径,通信框架
-
优化每个模块的处理时间
-
优化磁盘布局
-
增加数据缓存层
以NVMe为例,NVMe驱动层直接透过SCSI协议栈,由驱动层与通用块层直接交互,以达到降低IO时延的目标,同时使用通用块层的多队列机制,进一步的提升性能。不过这种方式的弊端是对于客户的成本上升较高。
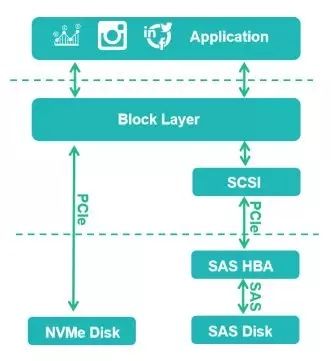
图七:通用存储设备协议栈与NVMe协议栈
一般存储厂商的通用有效方式是利用增加数据缓存层来降低延迟,即利用在存储节点给多块HDD配置一块SSD,再使用开源BCache方案,此种方案是一种通用的经济实惠解决方案。如下图所示,不过这种方案对性能提升有限,主要原因还是IO路径过长,分布式存储核心层逻辑过于复杂,同时采用开源BCache方案也存在着很多问题诸如:BCache虽然开源,但如果出现问题,基本没有维护的能力;BCache增加运维难度;BCache对成员盘的故障处理能力较弱。

 图八:后端缓存原理
图八:后端缓存原理
焱融科技存储研发团队,根据多年的技术经验及参考国内外厂商的设计思路,在最初设计焱融分布式存储软件时,针对如何提升性能降低IO延迟的方案设计上,自主设计实现了前后两端的缓存引擎即在后端缓存的基础上增加客户端缓存层,分拆存储核心层的部分功能,在网络层与存储核心层之间实现一个分布式缓存读写层,在网络收到请求后,将数据写入到缓存层中,实现分布式缓存读写,同时可保证数据的可靠性。整体设计思路如下:
图九:分布式读写缓存
通过这种实现方式,焱融分布式存储软件在性能上相对其他只有后端缓存方案有着明显的性能提升,在IOPS上提升近30%,能够达到裸盘SSD性能的85%以上,延迟降低近3倍,具体对比数据如下:



图十:性能比较
目前焱融研发团队,根据现有设计的基础,持续迭代,计划在下个版本的产品release中整体cache引擎架构如下,即通过本地缓存读、分布式缓存读写和后端缓存读写多层次的缓存,满足不同业务对性能高且平稳的总体需求。在IO路径上多层次的缓存,整个集群的IO将更加平稳,从IO处理的层面上降低IO波动。预计性能达到裸盘SSD 90%以上。
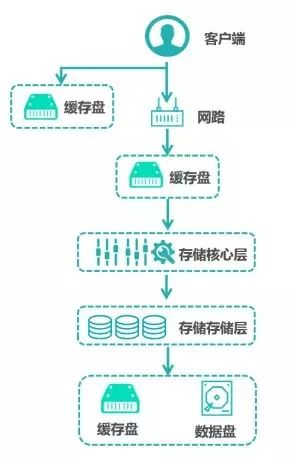
图十一:分布式层级缓存
关于焱融云
焱融云聚集了IBM、华为、VMware等世界顶级IT公司以及阿里云、百度云、腾讯云、金山云等国内一流云计算互联网企业的技术精英,组成了强大的技术团队,是一家以超融合技术为核心竞争力的高新技术企业,在分布式存储等关键技术上拥有自主知识产权。焱融超融合系列产品已服务于金融、政府、制造业、互联网等行业的众多客户。了解更多焱融科技信息,请访问官网www.yanrongyun.com。