
前言
上一篇文章我们简单的说了如何通过WebCollector抓取到内容,但是这并不能满足我们的工作需求,在工作过程中我们通常会抓取某个网页的列表下的详情页数据,这样我们就不能单纯的只从某个列表页面抓取数据了,我们需要跳转到详情页进行数据的二次抓取.好了,废话不多说,我们开始上代码说明如何操作.
抓取列表信息
假定我们就抓取骚栋主页中的所有展示文章详情内容.如下图所示.
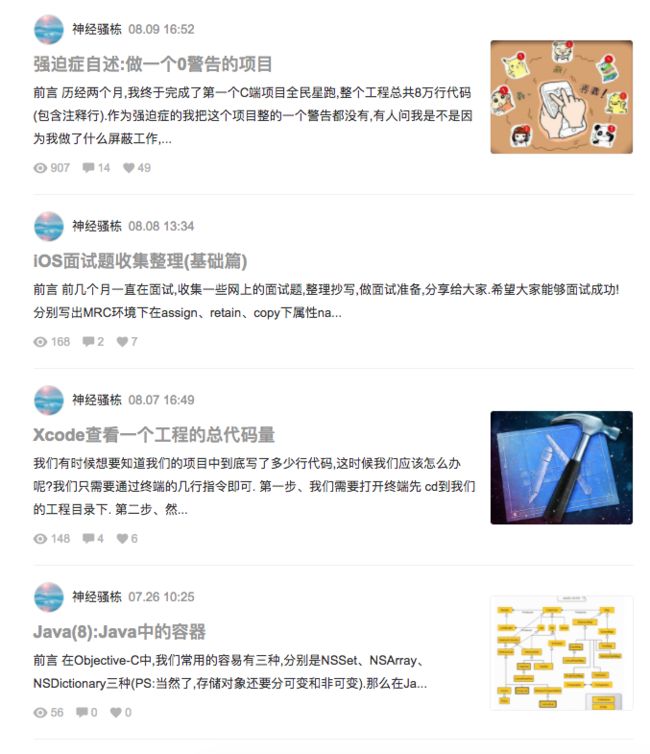
第一步,我们不忙创建爬虫,我们先分析我们所需要爬取网站的结构.根据我们需要Web页面的URL地址的特点来写出正确的正则表达式.如下所示.
http://www.jianshu.com/p/700e01a938ce
我写的一个匹配文章URL正则表达式如下所示.
"http://www.jianshu.com/p/.*"
第二步,正则表达式写好之后,我们需要分析我们抓取的网站的结构以及标签.以谷歌浏览器为例.开启开发者模式的控制台.(F12键 Mac的 commond +alt +i,这里不多啰嗦了),假定我们需要抓取文章的标题和内容.我们先选择"选择工具"(快捷键:commond +shift +c),然后点击标题,这时候在控制台就会出现所属标签信息了.如下所示.

我们发现,标题的标签h1的Class是title,如下所示.

标题已经准备好了,接下来我们看内容,还是如上步骤操作之后,我们发现内容在很多标签内,这时候我们只需要获取父类标签中所有内容即可.
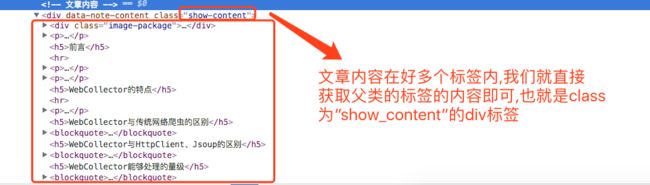
对了,首页的列表页面也是如上搞.如下所示,所有的超链接都是a标签.

第三步,我们还是创建好一个爬虫类JianshuCrawler继承于AbstractCrawler,然后在初始化方法中配置好我们的正则表达式以及我们需要爬取的网站种子等等一些其他配置.如下所示.
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
在visit方法中我们需要做两种处理,一是爬取文章列表,二是爬取文章详情页内容.所以我们需要拿详情页URL的正则表达式来区分文章详情页和列表首页,结构如下所示.
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
//详情页会进入这个模块
} else {
//列表首页会进入这个模块
}
}
通过第二步的分析,我们得知列表页面需要把所有超链接符合正则表达式的a标签添加到抓取序列中来.具体操作如下所示.
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
对于详情页面的逻辑,我们需要抓取对应元素的内容,我们可以根据class的名称(形式示例:div.xxx)也可以根据id名称(形式示例:div[id = xxx]),这里没有id,所以我们直接使用class的名称了,代码如下所示.
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
我们创建一个main函数,创建我们的爬虫对象.然后,我们需要设置抓取深度,因为我们这里是只需要一次跳转页面,所以我们的抓取深度为2.最后运行这个类.如下所示.
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
这样我们在控制台会得到我们想要的数据,当然了,数据的处理这里就不过多说明了.如下图所示.
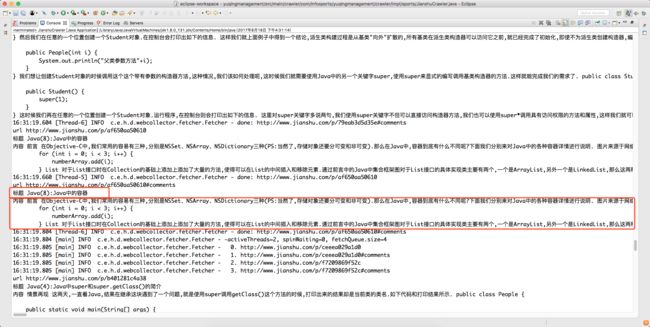
该爬虫类全部代码如下所示.
public class JianshuCrawler extends AbstractCrawler {
private static Logger logger = LoggerFactory.getLogger(JianshuCrawler.class);
private final static String crawlPath = "/Users/luying/data/db/sports";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
private final static String regexRuleString = "http://www.jianshu.com/p/.*";
public JianshuCrawler() {
super(crawlPath, false);
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
this.addRegex(regexRuleString);
setThreads(2);
}
@Override
public void visit(Page page, CrawlDatums next) {
if (page.matchUrl(regexRuleString)) {
String title = page.select("h1.title").text();
String content = page.select("div.show-content").text();
System.out.println("标题 " + title);
System.out.println("内容 " + content);
} else {
Elements aBodys = page.select("a");
for (int i = 0; i < aBodys.size(); i++) {
Element aElement = aBodys.get(i);
logger.debug("url=" + aElement.attr("abs:href"));
String regEx = regexRuleString;
if (aElement.attr("abs:href").matches(regEx)) {
CrawlDatum datum = new CrawlDatum(aElement.attr("abs:href")).meta("depth", "1").meta("refer",
page.url());
next.add(datum);
} else {
System.out.println("URL不匹配!!");
}
}
}
}
public static void main(String[] args) {
JianshuCrawler crawler = new JianshuCrawler();
crawler.start(2);
}
}
抓取图片信息
抓取图片就比较简单了假定我们还是抓取骚栋主页中的所有展示的图片.如下所示.

爬虫类基本的步骤就不不过多解释了,这里说一下visit方面中的处理,我们需要网页中标签的属性来进行判断,只有html属性和图片属性的标签才有可能是图片标签.所以我们首先获取标签名称如下所示.
String contentType = page.response().contentType();
然后判断标签所包含的名称.进行不同的操作,如下所示.
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
}
标签为网页属性的处理我们需要拿出里面的图片地址链接准备进行下一步的处理.代码如下所示.
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
如果是图片标签,我们直接拿去图片的byte数据,然后存储即可.代码如下所示.
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
由于,可能标签类型为网页,也就是说我们需要跳转到下一级页面中.这时候,我们在main函数中创建对象并需要把爬取深度设置为2.
public static void main(String[] args) throws Exception {
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
图片的存储过程就不过多解释了.,通过运行我们可以在对应的存储路径下找到我们的图片.如下所示.
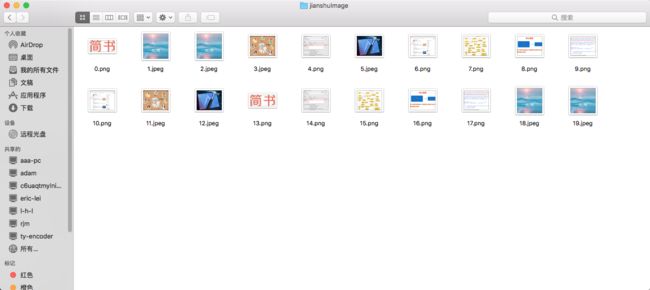
整体代码如下所示.
package com.infosports.yuqingmanagement.crawler.impl;
import java.io.File;
import java.io.IOException;
import java.util.concurrent.atomic.AtomicInteger;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.RegexRule;
public class JianshuImageCrawler extends BreadthCrawler {
// 用于保存图片的文件夹
File downloadDir;
// 原子性int,用于生成图片文件名
AtomicInteger imageId;
private final static String crawlPath = "/Users/luying/data/db/jianshu";
private final static String downPath = "/Users/luying/data/db/jianshuImage";
private final static String seed = "http://www.jianshu.com/u/e39da354ce50";
RegexRule regexRule = new RegexRule();
public JianshuImageCrawler() {
super(crawlPath, false);
downloadDir = new File(downPath);
if (!downloadDir.exists()) {
downloadDir.mkdirs();
}
computeImageId();
CrawlDatum datum = new CrawlDatum(seed).meta("depth", "2");
addSeed(datum);
regexRule.addRule("http://.*");
}
@Override
public void visit(Page page, CrawlDatums next) {
String contentType = page.response().contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
// 如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
next.add(imgSrc);
}
} else if (contentType.startsWith("image")) {
// 如果是图片,直接下载
String extensionName = contentType.split("/")[1];
String imageFileName = imageId.incrementAndGet() + "." + extensionName;
File imageFile = new File(downloadDir, imageFileName);
try {
FileUtils.write(imageFile, page.content());
System.out.println("保存图片 " + page.url() + " 到 " + imageFile.getAbsolutePath());
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
public void computeImageId() {
int maxId = -1;
for (File imageFile : downloadDir.listFiles()) {
String fileName = imageFile.getName();
String idStr = fileName.split("\\.")[0];
int id = Integer.valueOf(idStr);
if (id > maxId) {
maxId = id;
}
}
imageId = new AtomicInteger(maxId);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
JianshuImageCrawler crawler = new JianshuImageCrawler();
crawler.start(2);
}
总结
这篇博客写到这就到了尾声了,但是分享技术点过程却是没有结束.当然了,毕竟初学Java不久所以文章很多概念都可能模糊不清,所以如果有错误,欢迎指导批评,非常感谢.
