【GANs学习笔记】(十六)CGAN、TRIPLEGAN
完整笔记:http://www.gwylab.com/note-gans.html
———————————————————————
第三章 GANs的应用
Part1 GANs在图像生成上的应用
1. CGAN
1.1 传统GANs的问题
我们假设现在要做一个项目:输入一段文字,输出一张图片,要让这张图片足够清晰并且符合这段文字的描述。我们搭建一个传统的NeuralNetwork(下称NN)去训练。
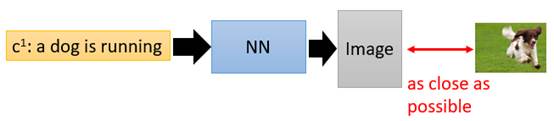
考虑我们输入的文字是“train”,希望NN能输出清晰的火车照片,那在数据集中,下面左图是正面的火车,它们统统都是正确的火车图片;下面右图是侧面的火车,它们也统统都是正确的火车。


那在训练这个NN的时候,network会觉得说,火车既要长得像左边的图片,也要长得像右边的图片,那最终network的output就会变成这一大堆images的平均,可想而知那会是一张非常模糊并且错误的照片。
我们需要引入GANs技术来保证NN产生清晰准确的照片。
我们把原始的NN叫做G(Generator),现在它吃两个输入,一个是条件word:c,另外一个是从原始图片中sample出的分布z,它的输出是一个image:x,它希望这个x尽可能地符合条件c的描述,同时足够清晰,如下图。

在GANs中为了保证输出image的质量会引入一个D(Discriminator),这个D用来判断输入的x是真实图片还是伪造图片,如下图。
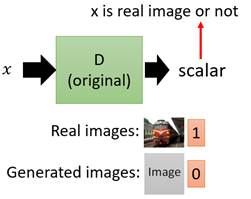
但是传统GANs只能保证让x尽可能地像真实图片,它忽略了让x符合条件描述c的要求。于是,为了解决这一问题,CGAN便被提出了。
1.2 CGAN的原理
我们的目的是,既要让输出的图片真实,也要让输出的图片符合条件c的描述。Discriminator输入便被改成了同时输入c和x,输出要做两件事情,一个是判断x是否是真实图片,另一个是x和c是否是匹配的。
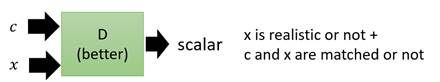
比如说,在下面这个情况中,条件c是train,图片x也是一张清晰的火车照片,那么D的输出就会是1。

而在下面两个情况中,左边虽然输出图片清晰,但不符合条件c;右边输出图片不真实。因此两种情况中D的输出都会是0。
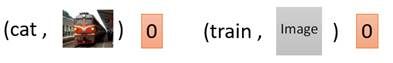
那CGAN的基本思路就是这样,下面我们具体看一下CGAN的算法实现。
1.3 CGAN的算法实现

因为CGAN是supervised学习,采样的每一项都是文字和图片的pair。CGAN的核心就是判断什么样的pair给高分,什么样的pair给低分。
我们先关注Discriminator:
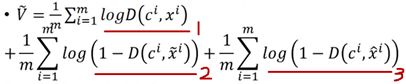
第一项是正确条件与真实图片的pair,应该给高分;第二项是正确条件与仿造图片的pair,应该给低分(于是加上了“1-”);第三项是错误条件与真实图片的pair,也应该给低分。
可以明显的看出,CGAN与GANs在Discriminator上的不同之处就是多出了第三项。
下面再关注一下Generaotor:
![]()
生成器的目的就是让判别器给仿造图片的得分越高越好,这与传统GANs本质上是一致的,只是在输入上多了一个参数c。
CGAN的最终目标表达式写为:
![]()
1.4 CGAN的讨论
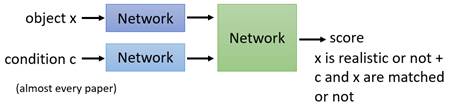
大部分的CGAN Discriminator都采用上述架构,为了把图片和条件结合在一起,往往会把x丢入一个network产生一个embedding,condition也丢入一个network产生一个embedding,然后把这两个embedding拼在一起丢入一个network中,这个network既要判断第一个embedding是否真实,同时也要判断两个embedding是否逻辑上匹配,最终给出一个分数。但是也有一种CGAN采用了另外一种架构,并且据李宏毅老师的介绍这种架构的效果是不错的。
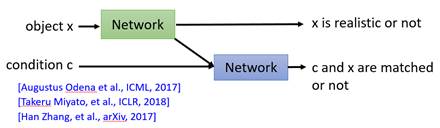
首先有一个network它只负责判断输入x是否是一个真实的图片,并且同时产生一个embedding,与c一同传给第二个network;然后第二个network只需判断x和c是否匹配。最终两个network的打分依据模型需求进行加权筛选即可。
第二种模型有一个明显的好处就是Discriminator能区分出为什么这样的pair会得低分,它能反馈给Generator得低分的原因是c不匹配还是x不够真实;然而对第一种模型而言它只知道这样的pair得分低却不知道得分低的原因是什么,这会造成一种情况就是Generator产生的图片已经足够清晰了,但是因为不匹配 c而得了低分,而Generator不知道得分低的原因是什么,依然以为是产生的图片不够清晰,那这样Generator就有可能朝着错误的方向迭代。不过,目前第一种模型还是被广泛应用的,其实事实上二者的差异在实际中也不是特别明显。
2. TripleGAN
2.1 TripleGAN解决的问题
TripleGAN是基于CGAN的改进,它主要想解决的问题是,在实际训练中,我们拥有的已配对的数据(c,x)往往是非常少量的,而人工标注配对数据(c,x)又比较麻烦,于是我们可以增添一个classifier去学习如何给图片x标注配对条件c,这样就能形成比较好的训练数据。
2.2 TripleGAN的模型架构
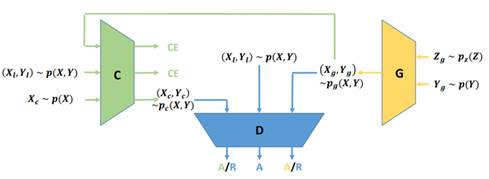
在上述架构图中,x是图片,y是条件(也就是c),(x,y)构成一个配对。从图中可以看出,TripleGAN由三个部分组成,第一个是Classifier,它负责学习并提供更多的配对信息给discriminator,主要是从生成配对、真实配对和仅有图片三种输入中学会提取出它们的配对信息![]() ,并将这个配对信息
,并将这个配对信息![]() 与图片
与图片![]() 整合成一个新的配对(
整合成一个新的配对(![]() )传递给discriminator;而第二个部分discriminator就需要学会鉴别输入的配对是来自真实数据,还是generator,还是classifier,最终在discriminator的帮助下
)传递给discriminator;而第二个部分discriminator就需要学会鉴别输入的配对是来自真实数据,还是generator,还是classifier,最终在discriminator的帮助下![]() ,
,![]() 都会越来越接近
都会越来越接近![]() ;至于第三个部分generator,就与CGAN中的generator一模一样了,输入一个条件y和先验分布z,产生一个输出图片x和条件y的配对。
;至于第三个部分generator,就与CGAN中的generator一模一样了,输入一个条件y和先验分布z,产生一个输出图片x和条件y的配对。
2.3 TripleGAN的应用价值
TripleGAN最大的应用价值就是不仅generator能够被提取出来,成为一个文字生成图片的模型,classifier也能被提取出来,成为一个图片标注文字的模型。