【GANs学习笔记】(十七)STACKGAN、STACKGAN++
完整笔记:http://www.gwylab.com/note-gans.html
———————————————————————
本章借鉴内容:
https://blog.csdn.net/zlrai5895/article/details/81292167
3. StackGAN
3.1 StackGAN解决的问题
StackGAN也是基于CGAN的改进,它主要想解决的问题是,CGAN没有办法产生高清的大图,StackGAN希望输入一个描述语c,能够产生一张256*256的清晰大图,核心思想就是搭建两个generator,第一个产生一个64*64的小图,然后把第一个generator的结果放入第二个generator中,在第二个generator中产生256*256的大图。
3.2 StackGAN的模型架构

StackGAN模型主要分为两个阶段。如图所示,第一阶段的StackGAN就是一个标准的条件对抗生成网络(Conditional GAN),输入就是随机的标准正态分布采样的z和文本描述刻画的向量c。第一步的对抗生成网络生成一个低分辨率的64*64的图片和真实数据进行对抗训练得到粗粒度的生成模型。第二阶段的StackGAN将第一阶段的生成结果和文本描述作为输入,用第二个对抗生成网络生成高分辨率的256*256的图片。
第一阶段
由结构图可见,对于获得的text_embedding,stackGAN 没有直接将 embedding 作为 condition,而是用embedding 接了一个 FC 层得到了一个正态分布的均值和方差,然后从这个正态分布中 sample 出来要用的 condition。最终的condition(![]() )是
)是
![]()
![]() 意为逐元素乘积(element_wise multiply)。 之所以这样做的原因是,embedding 通常比较高维(1024),而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个潜变量在潜空间里就比较稀疏,这对我们的训练不利。(实际上降了维,在处理后1024维降到了128维)。为了避免过拟合,generator 的 loss 里面加入了对这个分布的正则化:
意为逐元素乘积(element_wise multiply)。 之所以这样做的原因是,embedding 通常比较高维(1024),而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个潜变量在潜空间里就比较稀疏,这对我们的训练不利。(实际上降了维,在处理后1024维降到了128维)。为了避免过拟合,generator 的 loss 里面加入了对这个分布的正则化:
![]()
得到的c与服从标准正态分布的z连接起来,作为第一阶段generator的输入。
generator 使用的并不是常用的 Deconv ,而是若干个上采样加保持大小不变的 3x3 的 conv 的组合,这是最近提出的一种避免 Deconv 棋盘效应的上采样方法。discriminator 是若干步长为 2 的 conv ,再与 resize 的 embedding 合起来,接一个 FC。
第一阶段的输出是64*64的低分辨率图像。
第二阶段
第二阶段的 generator 并没有噪声输入,而是将第一阶段生成的低分辨率图像下采样以后与replicated的![]() 连接起来作为输入。经过若干 residual blocks ,再进行与第一阶段相同的上采样过程得到图片。
连接起来作为输入。经过若干 residual blocks ,再进行与第一阶段相同的上采样过程得到图片。
第二阶段的 discriminator 与第一阶段大体相同。
两个阶段的损失函数分别如下:
第一阶段
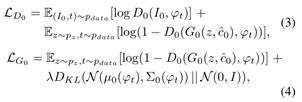
第二阶段
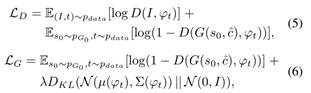
3.3 *StackGAN的改进
1.StackGAN++
StackGAN++是ICCV 2017 的文章《StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks》。与前作StackGAN相比,StackGAN v2有三点改进:
? 采用树状结构,多个生成器生成不同尺度的图像,每个尺度对应一个鉴别器。从而生成了多尺度fake images。
? 除了conditional loss,引入了unconditional loss。即不使用条件信息,直接使用服从标准正态分布的噪声z生成fake image的损失。
? 引入了color regulation,对生成的fake images 的色彩信息加以限制。
效果是提高了训练的稳定性,且提高了生成的图像质量。
具体的模型架构就不作介绍了,感兴趣的读者可以前往论文地址处查阅:
https://arxiv.org/abs/1710.10916
*李飞飞团队Text-To-Image Paper
在翻阅文本生成图像的相关工作,目前比较新的有突破性的工作是李飞飞工作团队18年cvpr发表的《Image Generation from Scene Graphs》。
不同于StackGAN存在比较突出的问题是不能处理比较复杂的文本,李飞飞小组提出的新方法能处理更长更复杂的文本,并且有不错的生成效果,感兴趣的读者可以前往论文地址处查阅:https://arxiv.org/abs/1804.01622。