sqoop导入数据到hive查询全部为null,sqoop导入到hive数据增多的解决方法
- sqoop导入数据到hive查询全部为null.
最近在用sqoop导入数据到hive的时候,遇到一个问题.用sqoop将数据导入到hive后,在hive查询,发现数据全部为null.
而用sqoop导入命令的时候,没有报错,提示成功
bin/sqoop import --connect jdbc:mysql://xxxxxxxxxxxxx:3306/xxxxxx --username xxxx--password xxxxxxx --table xxxxxxxxxx --hive-import --hive-table ods.test1 --hive-overwrite --m 1
在网上查找了原因,发现原因是在于,建hive表是设定的分割符不恰当,跟从postgresql导入过来的数据的分隔符不一样,所以导致hive切分不了数据,于是查询为空,但是这个过程,是不属于导入失败的,所以导入命令没有报错。
因为sqoop import实际上是把数据存放到hdfs对应路径上了,而不是“直接导入表里”,查询时,hive会从hdfs的路径上提取数据,再根据hive表的结构和定义,来向我们展示出类似表格的形式。因此,导入过程是不会报错的,但是因为hive定义的分隔符和存在hdfs上数据的分隔符不一致,所以查询是全为NULL的。
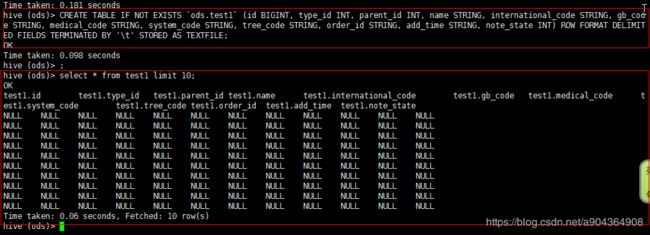
查看自己hive的建表语句
CREATE TABLE IF NOT EXISTS `ods.test1` (id BIGINT, type_id INT, parent_id INT, name STRING, international_code STRING, gb_code STRING, medical_code STRING, system_code STRING, tree_code STRING, order_id STRING, add_time STRING, note_state INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
可以看到分隔符为:FIELDS TERMINATED BY '\t',而从postgresql或者mysql来的数据的分隔符则应该为:FIELDS TERMINATED BY '\u0001',那我们只要改回来就可以正常导入了。
把表删了,重新建表,指定分隔符为FIELDS TERMINATED BY '\u0001'.
CREATE TABLE IF NOT EXISTS `ods.test1` (id BIGINT, type_id INT, parent_id INT, name STRING, international_code STRING, gb_code STRING, medical_code STRING, system_code STRING, tree_code STRING, order_id STRING, add_time STRING, note_state INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' STORED AS TEXTFILE;
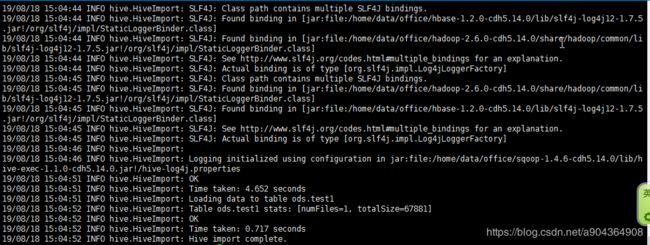
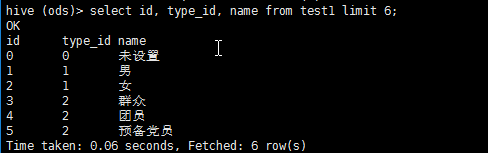
再重新执行sqoop的导入命令.执行完以后查看果然数据已经能够展示了
2. sqoop导入数据到hive数据增多
在一次使用sqoop导入数据到hive,使用的hive自动建表.在查询的时候发现,hive中的数据比mysql数据库中多.
在网上查找了以后,发现是分隔符的问题.
导入的数据默认的列分隔符是'\001',默认的行分隔符是'\n'。
这样问题就来了,如果导入的数据中有'\n',hive会认为一行已经结束,后面的数据被分割成下一行。这种情况下,导入之后hive中数据的行数就比原先数据库中的多,而且会出现数据不一致的情况。
简单的解决办法就是加上参数--hive-drop-import-delims来把导入数据中包含的hive默认的分隔符去掉。
参考 往hive导入查询数据全为NULL,但导入过程无报错,mysql/postgresql
sqoop导出到hive数据增多
sqoop官方文档