学习Python爬虫(四):模拟浏览器向服务器提交请求
有时候纯粹使用request.get()方法这样简单粗暴的方式似乎并不能获得我们想要的信息,这是因为有的网页自带了『反爬虫机制』——比如通过访问请求的HTTP header的user-agent进行来源审查——为了模拟浏览器访问,我们需要重新定义请求HTTP header的user-agent字段
复习requests.get()方法
再说一遍,requests库的get方法非常常用,务必熟练掌握
学好了get方法,其它几个方法的掌握也是水到渠成的事情
def get(url, params=None, **kwags):
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
学到现在我们对于这种形式已经和很熟悉了:
r = requests.get(url) #params=None,返回Responce对象
但是已经不满足这种简单的请求模式了,我们可以尝试使用另外两个参数
分析一下request.get()方法的三个参数字段(实际上说三个不准确因为第三个是一个关键字参数,大家懂就好~)
第一个参数,url参数表示参与拼接的url链接(如果与后面的params合并的话,没有就是其本身)
第二个参数,params=None是一个默认参数(默认为空),表示参数拼接的部分url,最终请求访问的url链接是第一个url参数和第二个params参数的合并结果(中间可能加上诸如问号之类的东西,这些琐事都由requests库代为完成)
第三个参数,**kwagrs是一个关键字参数(支持多个参数),可以写headers = xxx之类的,传入后以字典形式出现
背景知识:如何构造一个URL链接
关于url『是什么』的问题,前面已经讲过,这里不再赘述
下面讲解如何根据需要构造一个合法的url,有些地方看不懂没关系,具体操作见后文,这里只要知道『大概怎么做』就可以了
问号(?)
问号的作用有二:
1)连接作用
http://www.xxx.com/show.asp?id=101&nameid=100000000&page=1
2)清除缓存
http://www.xxx.com/index.html
http://www.xxx.com/index.html?text101010 #两个url打开的页面一样,但是后者的问号说明不调用缓存的内容而是以读取一个新地址的方式重新读取
“和”号(&)
用法比较单一,仅作为不同参数的间隔符号
http://www.xxx.com/show.asp?id=101&nameid=100000000&page=1
和问号第一点作用之区别:问号分隔的是url和参数,而和号分割的是不同的参数
除此之外,一个url链接中还常常出现井号(#),它的作用同样不容小嘘,但是这里我们先掌握前面两个(问号和和号)的作用就行了
至于它们具体怎么通过代码构造出来,详见下文……
使用params参数(组合url链接)
requests.get()方法的params参数是一个可选的参数,为一个字典或字节流,和url参数组合成为新的url链接
因为在get()方法原型声明中,params参数出现在第二个位置,所以可以不写params,也可以写params
可以这样写:
r = requests.get(url, params=keyword)
也可以这样写(相当于位置参数):
r = requests.get(url, keyword)
*一般推荐大家使用第一种写法(显式的写出params,反正就是一个英文单词的事,却大大提高了代码的可读性,避免与后面的*kwargs字段混淆);但是也不是绝对,怎么说呢,看具体情况吧,如果我们要访问一个登陆接口:
http://www.server.com/login
这时候写logininfo显然比params可读性要好
构造出来就是
longininfo = {'username':'me', 'password':xxxxxxxxxxx}
于是完整的url链接(url参数和params参数整合后)就变成了
http://www.server.com/login?username=me&password=xxxxxxxxxxx
举个栗子
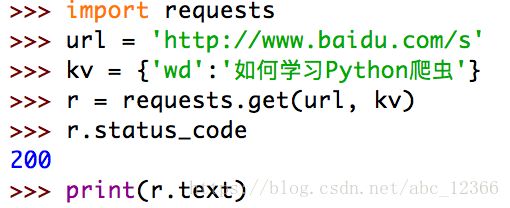


因为我知道百度的搜索接口是形如:
http://www.baidu.com/s?wd=你想要搜索的东西
在这个搜索接口中,问号由requests完成拼接,而后面的wd=你想要搜索的东西显然是一个字典被解压后的形式,于是我尝试加入一个字典到原始的url链接中,并成功完成拼接
类似的,360的搜索接口是:
http://www.so.com/s?q=你想要搜索的东西
大家可以自己尝试,很简单的
*使用*kwargs参数
**kwargs是一个关键字参数,最多可以提供十二种参数
因为是关键字参数,所以必须以字典的形式xx=xx的形式传入参数
1)data:字典、字节序列或文件对象,作为request的内容
2)json:JSON格式的数据作为request的内容
3)headers:字典,HTTP定制头
4)cookies:字典或Cookiejar
5)auth:元组,支持HTTP认证功能
6)file:字典,传输文件
7)timeout:超时时间,以秒为单位
8)proxies:字典,设置代理服务器,可以增加登陆认证
9)allow_redirects:True或False(默认True),重定向开关,是否允许对url进行重定向
10)stream:True或False(默认True),获取内容立即下载开关
11)verify:True或False(默认True),认证SSL认证开关
12)cert:保存本地SSL路径开关
这些名字要记住(新手只要记住几个常用的即可),名字不是没有意义的,这些命名都是和HTTP请求信息字段息息相关的,所以在传参数时名字不要写错(以字典形式传参)
我们以headers字段为例进行讲解(这个很常用)
想象这样一个情景:你通过Python爬虫尝试爬去某知名网站的某商品信息,但是在直接调用requests.get(url)方法后却发现r.status_code的返回值为503(不是200,表示出错),这种出错的可能有多种,我们假设就是因为该网页的来源审查机制限定了HTTP请求的来源——通过什么进行判断是否限制呢?我们假设就是通过HHTP header字段进行来源审查的(在HTTP请求头,Python爬虫的User-agent字段会诚实的显示其身份)
*怎么办呢?要能修改HTTP请求头自就好了——requests库刚好就提供了这个功能:只要在*kwargs参数对应的位置传入headers字段(以字典形式传入)就可以了,下面是一个示例
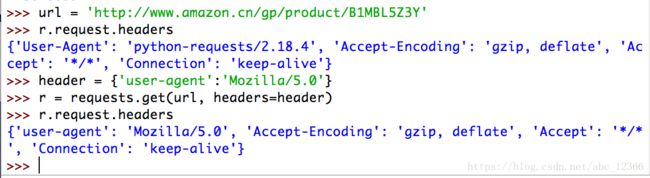
可以看到,在通过headers字段修改后,其中user-agent字段从python爬虫变成了标准的浏览器UA