SQL基础语法
1 什么是SQL
结构化查询语言(Structured Query Language)简称SQL
SQL语句就是对数据库进行操作的一种语言
2 SQL语句的分类
1、DDL(Data Definition Language) 数据定义语言 用来定义数据库对象:数据库,表,列等。关键字:create, drop,alter等
2、DML(Data Manipulation Language) 数据操作语言 用来对数据库中表的数据进行增删改。关键字:insert, delete, update等
3、DQL(Data Query Language) 数据查询语言 对数据库进行数据查询,关键字select
4、DCL(Data Control Language)数据控制语言(了解)是用来设置或更改数据库用户或角色权限的语句,这个比较少用到
3 SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾
2、可使用空格和缩进来增强语句的可读性
3、MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
4 SQL的注释
单行注释: - - 注释
多行注释: /注释 /
MYSQL特有的单行注释:# 注释
5 DDL 操作(操作数据库和表)
5.1 DDL 操作数据库
5.1.1 创建数据库
1、直接创建数据库
CREATE DATABASE 数据库名;
2、判断是否存在并创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;
3、创建数据库并指定字符集(编码表)
CREATE DATABASE 数据库名 DEFAULT CHARACTER SET 字符集;
5.1.2 查看数据库
1、查看所有的数据库
SHOW DATABASES;
2、查看某个数据库的定义信息
SHOW CREATE DATABASE 数据库名;
5.1.3 修改和删除数据库
1、修改数据库字符集
ALTER DATABASE 数据库名 DEFAULT CHARACTER SET 新字符集;
2、删除数据库
DROP DATABASE 数据名;
5.1.4 使用和切换数据库
1、查看正在使用的数据库
SELECT DATABASE();
2、使用/切换数据库
USE 数据库名;
5.2 DDL 操作表
5.2.1 创建表
1、创建表
CREATE TABLE 表名(
字段名 数据类型,
字段名 数据类型
);
2、快速创建一个表结构相同的表,只是表没有数据
CREATE TABLE 表名 LIKE 其他表;
5.2.2 查看表
1、查看某个数据库中的所有表
SHOW TABLES;
2、查看表结构
DESC 表名;
3、查看创建表的SQL语句
SHOW CRETE TABLE 表名;
5.2.3 删除表
1、直接删除表
DROP TABLE 表名;
2、判断表是否存在并删除表
DROP TABLE IF EXISTS 表名;
5.2.4 修改表结构
1、添加一列(字段)
ALTER TABLE 表名 ADD 字段名 字段类型;
2、修改列类型(MODIFY只能修改类型)
ATLER TABLE 表名 MODIFY 字段名 新的类型;
3、修改列名(CHANGE可以同时修改字段和类型)
ALTER TABLE 表名 CHANGE 老字段名 新字段名 类型;
4、删除列
ALTER TABLE 表名 DROP 字段名;
5、修改表名
RENAME TALBE 旧表名 TO 新表名;
6、修改表的字符集
ALTER TABLE 表名 DEFAULT CHARACTER SET 新字符集;
6 DML 操作(操作数据/记录)
DML是对表中的数据进行增删改
6.1 插入操作
6.1.1 插入全部字段
-- 所有的字段名都写出来:
INSERT INTO 表名 (字段名1, 字段名2...) VALUES (字段值1, 字段值2);
-- 不写字段名
INSERT INTO 表名 VALUES (字段值1, 字段值2);
-- 同时参入多个条记录
INSERT INTO 表名 VALUES (字段值1, 字段值2),(字段值1, 字段值2),(字段值1, 字段值2);
6.1.2 插入部分字段
-- 只需要指定要插入数据的字段,没有添加数据的字段会使用NULL
INSERT INTO 表名 (字段名1, 字段名2...) VALUES (字段值1, 字段值2);
6.1.3 注意事项
1、值与字段必须对应,个数相同,类型相同
2、值的数据大小必须在字段的长度范围内
3、除了数值类型外,其它的字段类型的值必须使用引号引起。(建议单引号)
4、如果要插入空值,可以不写字段,或者插入null
6.1.4 DOS命令窗口操作数据乱码问题
/*
在dos命令窗口执行sql操作的时候,由于MySQL的客户端设置编码是utf8,
而系统的DOS命令行编码是gbk,编码不一致会导致乱码问题
以下方式为临时方案,退出DOS命令行就失效了,需要每次都配置
*/
set names gbk;
6.2 更新/修改操作
6.2.1 不带条件的更新数据库记录
UPDATE 表名 SET 字段名=新的值;
6.2.2 带条件更新数据库记录
UPDATE 表名 SET 字段名=新的值 WHERE 条件;
6.3 删除操作
6.3.1 带条件删除数据
DELETE FROM 表名 WHERE 字段名=值;
6.3.2 不带条件删除数据
DELETE FROM 表名;
6.3.3 DELETE和TRUNCATE的区别
-- 扩展delete和truncate的区别
-- delete只删除数据,不会重置主键的值,比如删表前最后的id=100,那么重新插入数据会从id=101开始
DELETE FROM st6;
INSERT INTO st6 (NAME,age) VALUES ('哈吉',21),('敬理',23),('王大',29);
-- truncate删除这张表,在创建一张一样的表,主键重置,比如删表前最后的id=100,那么重新插入数据会从id=1开始
TRUNCATE st6;
INSERT INTO st6 (NAME,age) VALUES ('哈吉',21),('敬理',23),('王大',29);
7 DQL 操作
查询不会对数据库中的数据进行修改,只是一种显示数据的方式
7.1 查询表中的所有数据
1、写出查询每列的名称
SELECT 字段名1, 字段名2,... FROM 表名;
2、使用*表示所有列
SELECT * FROM 表名;
7.2 查询表中指定列
SELECT 字段名1, 字段名2 FROM 表名;
7.3 查询时使用别名
-- AS可以省略,使用别名的好处是方便观看和处理查询到的数据
SELECT 字段名1 AS 别名, 字段名2 AS 别名... FROM 表名 AS 表别名;
7.4 清除重复值查询
SELECT DISTINCT 字段名 FROM 表名;
7.5 查询结果参与运算
参与运算的必须是数值类型
1、某列数据和固定值运算
SELECT 字段名 + 数值 FROM 表名;
2、某列数据和其他列数据参与运算
SELECT 字段1 + 字段2 FROM 表名;
7.6 蠕虫复制
7.6.1 什么是蠕虫复制
将一张表的数据复制,插入到另一张表中
7.6.2 语法格式
INSERT INTO 表名1 SELECT * FROM 表名2;
7.6.3 具体操作步骤
1、创建student2表,student2结构和student表结构一样
CREATE TABLE student2 LIKE student;
2、将student表中的数据添加到student2表中
INSERT INTO student2 SELECT * FROM student;
注意事项:如果只想复制student表中name,age字段数据到student2表中使用如下格式
INSERT INTO student2(NAME, age) SELECT NAME, age FROM student;
7.7 条件查询
7.7.1 格式
SELECT 字段 FROM 表名 WHERE 条件;
7.7.2 查询条件可能用到的运算符
7.7.2.1 比较运算符
> -- 大于
< -- 小于
<= -- 小于等于
>= -- 大于等于
= -- 等于
<>、!= -- 不等于
7.7.2.2 逻辑运算符
and(&&) -- 多个条件同时满足
or(||) -- 多个条件其中一个满足
not(!) -- 不满足,取反
7.7.2.3 IN关键字
1、in里面的每个数据都会作为一次条件,只要满足条件的就会显示
2、格式:
SELECT * FROM 表名 WHERE 字段名 IN (值1, 值2, 值3);
7.7.2.4 BETWEEN…AND…范围查询
1、范围包括头也包括尾
2、格式:
SELECT * FROM 表名 WHERE 字段名 BETWEEN 值1 AND 值2;
7.8 模糊查询 LIKE
1、格式
SELECT * FROM 表名 WHERE 字段名 LIKE '通配符字符串';
2、说明
满足通配符字符串规则的数据就会显示出来
-- MySQL通配符有两个:
% 表示任意多个字符
_ 表示一个字符
7.9 排序查询
1、格式
SELECT * FROM 表名 WHERE 条件 ORDER BY 字段名 [ASC|DESC];
[]表示可以不要
|表示二选一
ASC: 升序(默认的)
DESC: 降序
7.9.1 单列排序
单列排序就是使用一个字段排序
-- 按照年龄的降序查询学生所有的信息
select * FROM student order by age DESC;
7.9.2 组合排序
组合排序就是先按第一个字段进行排序,如果第一个字段相同,才按第二个字段进行排序,依次类推
1、格式
SELECT * FROM 表名 WHERE 条件 ORDER BY 字段名 [ASC|DESC], 字段名 [ASC|DESC];
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩降序排序
SELECT * FROM student ORDER BY age DESC, math DESC;
7.10 聚合函数查询
聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。另外聚合函数会忽略空值NULL。
-- 五个聚合函数:
count: 统计指定列记录数,记录为NULL的不统计
sum: 计算指定列的数值和,如果不是数值类型,那么计算结果为0
max: 计算指定列的最大值(要求是数值类型才计算)
min: 计算指定列的最小值(要求是数值类型才计算)
avg: 计算指定列的平均值(要求是数值类型才计算)
1、格式
SELECT 聚合函数 FROM 表名 WHERE 过滤条件;
-- 注意:统计数量常用*号
SELECT COUNT(*) FROM student;
7.11 分组查询(和聚合函数一起使用)
对查询后的结果进行分组
7.11.1 格式
SELECT * FROM 表名 WHERE 条件 GROUP BY 字段名;
上面的SQL会将sex相同的数据作为一组,然后返回每组的第一条数据

7.11.3 案例说明分组函数的原理
GROUP BY将分组字段的相同值作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
分组后聚合函数的作用:不是操作所有数据,而是分别操作每组数据。
一般按什么字段名分组,SELECT后面就写什么字段名
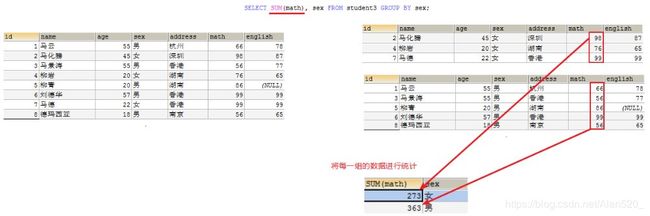
SELECT SUM(math), sex FROM student3 GROUP BY sex;
执行上面SQL后效果如下:

实际上是将每组的math进行求和,返回每组统计的结果
7.11.4 案例
需求:查询年龄大于25岁的人,按性别分组,统计每组的人数
1.先过滤掉年龄小于25岁的人
2.再分组
3.最后统计每组的人数
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex;

注意事项:对于分组后的条件需要使用having子句(WHERE先执行,然后执行GROUP BY,最后才执行HAVING)
-- having与where的区别
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用聚合函数
where后面不可以使用聚合函数
7.12 LIMIT语句:用做分页
1、格式
-- offset 跳过的记录数,不写则默认为0。
-- length 要显示的总记录数
SELECT * FROM 表名 WHERE 条件 LIMIT offset, length;
-- 跳过前面2条,显示(取)6条数据
SELECT * FROM student3 LIMIT 2,6;
7.13 SQL查询的执行顺序
SELECT 字段名 FROM 表名 WHERE 条件 GROUP BY 分组列名 HAVING 条件 ORDER BY 排序列名 LIMIT 跳过的行数, 显示的行数;
-- 顺序如下
1.FROM: 从哪个表中获取数据
2.WHERE: 过滤表中的数据
3.GROUP BY: 将过滤后的数据进行分组
4.HAVING: 对分组后的数据再进行过滤
5.SELECT: 获得结果集(过滤、分组之后的数据-- 看做是一张新的表)
6.ORDER BY: 将结果集按照某种顺序对数据进行排序
7.LIMIT: 将排序后的数据分页显示
注意:GROUP BY之后计算SELECT后面的集合函数
8 数据库约束
8.1 数据库约束的作用
对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性
8.2 数据库约束的种类
PRIMARY KEY: 主键约束
UNIQUE: 唯一约束
NOT NULL: 不为空
DEFAULT: 默认约束
FOREIGN KEY: 外键约束 (笔记在多表的查询)
8.3 主键约束(PRIMARY KEY)
每张表都应该有一个主键,并且每张表只能有一个主键
8.3.1 主键的作用
== 区分表中的记录==
8.3.2 那个字段作为主键
通常不用业务字段作为主键,单独给每张表设计一个id的字段,把id作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行
8.3.3 主键的特点
主键必须唯一,不能重复
主键不能为NULL
8.3.4 创建主键的方式
8.3.4.1 在创建表的时候给字段添加主键
CREATE TABLE 表名 (
字段名 字段类型 PRIMARY KEY,
字段名 字段类型
);
8.3.4.2 在已有表中添加主键
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);
8.3.4.3 删除主键
ALTER TABLE 表名 DROP PRIMARY KEY;
8.3.4.4 主键自增(PRIMARY KEY AUTO_INCREMENT)
CREATE TABLE 表名 (
字段名 字段类型 PRIMARY KEY AUTO_INCREMENT,
字段名 字段类型
);
注意事项:AUTO_INCREMENT表示自动增长(修饰的字段类型必须是整数类型)
8.3.4.5 修改自增长起始值
默认地AUTO_INCREMENT 的开始值是1,如果希望修改起始值,请使用下列SQL语法
ALTER TABLE 表名 AUTO_INCREMENT=起始值;
8.4 唯一约束(UNIQUE)
8.4.1 唯一约束的作用
这个字段的值不能够重复
8.4.2 唯一约束的格式
CREATE TABLE 表名 (
字段名 字段类型 UNIQUE,
字段名 字段类型
);
8.5 非空约束(NOT NULL)
8.5.1 非空约束的作用
限制表中数据不能为空
8.5.2 非空约束的格式
CREATE TABLE 表名 (
字段名 字段类型 NOT NULL,
字段名 字段类型
);
8.5.3 主键和定义为非空唯一的普通字段的区别
1.一张表只能有一个主键,可以有多个唯一非空的字段
2.主键可以自动增长,普通字段不行
8.6 默认值(DEFAULT)
8.6.1 默认值的作用
如果这个字段不设置值,就使用默认值。
8.6.2 默认值的格式
CREATE TABLE 表名 (
字段名 字段类型,
字段名 字段类型 DEFAULT 默认值
);