深入简出的掌握InnoDB引擎 MVCC协议
MVCC(Multi-Version Concurrent Control),即多版本并发控制协议,广泛使用于数据库系统(mysql、HBase)。由于MVCC没有一个统一的实现标准,本人将针对mysql的InnoDB引擎谈谈它的应用。
目录
1. 概述
2. 产生背景
3.与事务隔离级别的关联
4. 原理
4.1 redo日志
4.2 undo日志
4.3 回滚段
4.4 行记录数据结构
5. 优缺点
6. 快照读 & 非快照读
7. 为什么select count(*)在myisam表上很快,而在Innodb的表上很慢?
8. 能禁用MVCC吗?
1. 概述
MVCC(也叫快照读)是行锁的一种变种,但是他在很多情况下避免了加锁的操作,因此开销更低。多版本并发控制实现了非阻塞的读操作,也可称之为一致性非锁定读。它通过行的多版本控制方式来读取当前执行时间数据库中的行数据。实质上使用的是快照数据(undo log中的行就是MVCC中的多版本)。
2. 产生背景
InnoDB并发控制之前讲过,总体的思路大概是:
- 普通锁,本质是串行执行
- 读写锁,可以实现读读并发
- 数据多版本,可以实现读写(修改)并发
3.与事务隔离级别的关联
| 读已提交(Read Committed) | 在该级别下,每次select时,都会通过MVCC获取当前数据的最新快照(总是读取被锁定行的最新的快照数据),不加任何锁,也无视任何锁, 它最大的问题就是不可重复的 |
| 可重复读(Repeatable Read) | 在该级别下,MVCC版本的生成时间,事务中只在第一次select时生成版本(总是读取事务开始时的行数据版本),后续的查询都是在这个版本上进行 它最大的问题就是幻读 |
不可重复读的重点是修改:同样的条件的select, 你读取过的数据, 再次读取出来发现值不一样了
幻读的重点在于新增或者删除:同样的条件的select, 第1次和第2次读出来的记录数不一样,在行锁的基础上,加上Gap Lock,从而形成Next-Key Lock。另一篇中重点介绍
4. 原理
- 写任务发生时(修改时),将数据克隆一份,以版本号区分;
- 写任务操作新克隆的数据,直至提交;
- 并发读任务可以继续读取旧版本的数据,不至于阻塞;
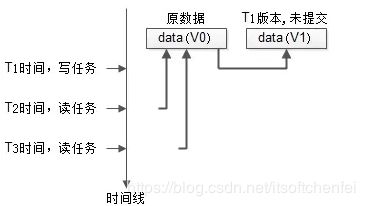
- 最开始数据的版本是V0;
- T1时刻发起了一个写任务,这是把数据clone了一份,进行修改,版本变为V1,但任务还未完成;
- T2时刻并发了一个读任务,依然可以读V0版本的数据;
- T3时刻又并发了一个读任务,依然不会阻塞;
可以看到,数据多版本,通过“读取旧版本数据”能够极大提高任务的并发度。
这里有一个误区:
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,各个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
啥?听起来含有乐观锁的味道,那你就大错特错了,而Innodb的真实实现是这样的:
本质的在于当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
- 事务以排他锁的形式修改原始数据(读除外)
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
4.1 redo日志
一句话,redo日志用于保障,已提交事务的ACID特性。假如某一时刻,数据库崩溃,还没来得及刷盘的数据,在数据库重启后,会重做redo日志里的内容,以保证已提交事务对数据产生的影响都刷到磁盘上。
为什么要有redo日志?
数据库事务提交后,必须将更新后的数据刷到磁盘上,以保证ACID特性。磁盘随机写性能较低,如果每次都刷盘,会极大影响数据库的吞吐量。
优化方式是,将修改行为先写到redo日志里(此时变成了顺序写),再定期将数据刷到磁盘上,这样能极大提高性能。随机写优化为顺序写,思路更重要。
4.2 undo日志
一句话,undo日志用于保障,未提交事务不会对数据库的ACID特性产生影响。
为什么要有undo日志?
数据库事务未提交时,会将事务修改数据的镜像(即修改前的旧版本)存放到undo日志里,当事务回滚时,或者数据库奔溃时,可以利用undo日志,即旧版本数据,撤销未提交事务对数据库产生的影响。
对于insert操作,undo日志记录新数据的PK(ROW_ID),回滚时直接删除;
对于delete/update操作,undo日志记录旧数据row,回滚时直接恢复;
他们分别存放在不同的buffer里。
4.3 回滚段
存储undo日志的地方,是回滚段。undo日志和回滚段和InnoDB的MVCC密切相关。
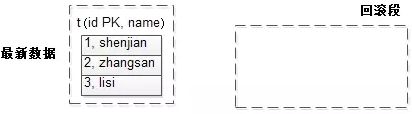
/**
* t(id PK, name);
* 数据为:
* 1, shenjian
* 2, zhangsan
* 3, lisi
**/
--事务T1:
start trx;
delete (1, shenjian);
update set(3, lisi) to (3, xxx);
insert (4, wangwu);
事务T1(未执行前),没有事务,故回滚段是空的(下图)
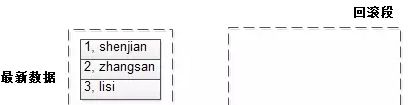
事务T1执行,并且事务处于未提交的状态(下图)

假设事务提交,回滚段里的undo日志可以删除。
假如事务rollback,此时可以通过回滚段里的undo日志回滚(下图1),直至成功(下图2)。

这里提问一个问题:旧版本数据存储在哪里?存储旧版本数据,对MySQL和InnoDB原有架构是否有巨大冲击?
通过上文undo日志和回滚段的铺垫,旧版本数据存储在回滚段里,这样对对MySQL和InnoDB原有架构体系冲击不大。
4.4 行记录数据结构
InnoDB的内核,会为每一行数据增加三个内部属性:
| DATA _TRX_ID | 6字节,记录每一行最近一次修改它的事务ID(每开启一个新的事务,其对应的事务id会自动递增) |
| DATA_ROLL_PTR | 7字节,一个指向此条记录项的undo信息的指针,undo信息是指此条记录被修改前的信息; |
| DB_ROW_ID | 6字节,单调递增的行ID |
当读取一行记录时会进入下面流程:

5. 优缺点
- 优点:回滚段里的数据,其实是历史数据的快照(snapshot),这些数据是不会被修改,select可以肆无忌惮的并发读取他们。这种一致性不加锁的读(Consistent Nonlocking Read),就是InnoDB并发如此之高的核心原因之一。
- 缺点:为了实现多版本,innodb必须对每行增加相应的字段来存储版本信息,同时需要维护每一行的版本信息,而且在检索行的时候,需要进行版本的比较,因而降低了查询的效率;innodb还必须定期清理不再需要的行版本,及时回收空间,这也增加了一些开销
6. 快照读 & 非快照读
快照读(Snapshot read)
普通的select语句都是快照读,例如:select * from t where id>2;
非快照读或叫当前读(current read)
显示加锁(前两种锁定读),这就复杂了可能是行锁、间隙锁、Next-Key锁,另一篇中重点介绍,例如:
select * from table where ? lock in share mode; (加S锁)
select * from table where ? for update; (加X锁)insert, update, delete 操作前会先进行一次当前读(加X锁)
注:这两种锁都必须处于事务中,事务commit,锁释放。所以必须begin或者start transaction 开启一个事务或者索性set autocommit=0把自动提交关掉(mysql默认是1,即执行完sql立即提交)
7. 为什么select count(*)在myisam表上很快,而在Innodb的表上很慢?
因为innodb采用了MVCC技术,对于相同的行,可能同时存在多个版本,innodb必须根据查询的时间来过滤掉一些行,才能得出结果,必然要执行全表扫描,而全表扫描是非常耗时的.对于myisam的表,任何行都只有一个版本,mysql甚至不需要扫描就可以直接返回精确的统计结果,我们用explain也可以看到,对于myisam的表,执行select count(*)的时候,mysql显示” Select tables optimized away”,查询直接被优化了;而对于innodb的表,可能是全表扫描,也可能是”using index”,总之,速度肯定会比myisam的表慢很多。
你想了解的更多,参考我另一篇索引底层原理
8. 能禁用MVCC吗?
禁用MVCC可以降低innodb引擎的开销,而同时innodb又可以支持外键约束,可以实现自动恢复.MVCC本身不支持read uncommitted等级,所以可以通过设置transaction_isolation = read uncommitted 来禁用MVCC.但是任何改变innodb默认隔离等级的操作,都会起到innodb_locks_unsafe_for_binlog=off类似的效果,这会导致诸如insert into t select * from t_src 之类的语句不再给源表t_src加锁,也不再使用innodb的间隙锁,从而产生幻读,直接导致binlog中记录的sql语句不能正确的串行化,从而主从数据库的数据不再一致,而且基于binlog的增量备份也不再有效.所以除非不需要记录binlog,否则别这么做.当然我们可以这样做来优化从库的性能,因为从库不需要记录binlog.
引用资源
- how-does-mvcc-multi-version-concurrency-control-work
- PostgreSQL Concurrency with MVCC