分布式数据库中间件 TDDL 学习笔记
之前介绍过从分库分表到数据访问层中间件,Tddl是一个分布式数据库中间件,它在阿里内部被广泛的使用,主要是为了解决分布式数据库产生的相关问题,分布式数据库与数据库中间件息息相关。最近三年社区最流行的是Sharding-Sphere(目前已进入Apache孵化器),但这不妨碍我们学习Tddl,主要是学习它优秀的设计及原理。
目录
1. 演变历史
2. 组件架构
3. 关于读写分离
4. 执行流程
5. 结果集合并
6. 全局sequence的生成
7. 分区片键规则介绍
8. SQL的优化器
引用资料
1. 演变历史
1)TDDL 2.0 (2009~2011) 第一个流行版本
2)TDDL 3.1 (2012~) 规则版本升级
3)TDDL 3.3 (2013~) 引入druid链接池
4)Andor (2012~2013) 一次全新的尝试,支持跨库查询
5)TDDL 5.0 (2013) 基于Andor + TDDL3.3的发展而来,保留各自的优点
6)TDDL 5.1 (2014~) 集成cobar,提供server模式,解决跨语言查询
2. 组件架构
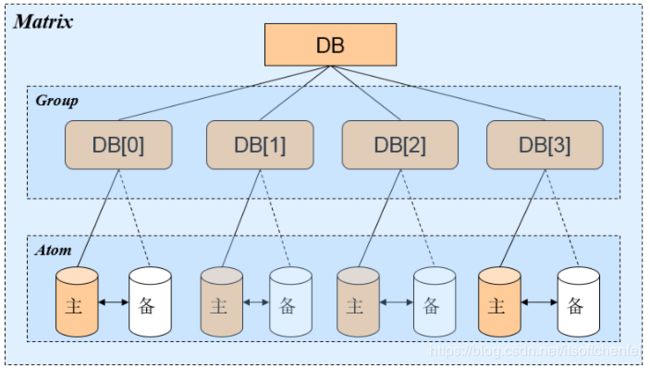
Matrix 层
Matrix 层可以解决分库分表带来的问题,从本质上来看,分库分表带来的最直接的影响是数据访问的路由。常见的数据访问路由算法有以下几种:
- 固定哈希算法,基本能保证数据均匀分布,它也是 TDDL 的默认路由算法。根据某个字段(如整形的 id 或者字符串的 hashcode)对分库的数量或者分表的数量进行取模,根据余数路由到对应的位置。
- 一致性哈希算法,固定哈希算法带来的数据迁移成本是非常大的,而一致性哈希算法的原理就是通过该算法计算出 key 的 hashcode 之后对 2^32 取模,那么数据都会落在 0~2^32 所组成的环中,然后数据存储在顺时针方向最近的机器上。一致性哈希已经可以解决大部分数据迁移需求了,但是对于数据集中在热点的情况,一致性哈希同样面临比较大的挑战,引入虚拟节点之后,情况就不一样了,所谓虚拟节点,它就是物理节点的映射,一个物理节点可以复制出多个虚拟节点,尽可能的让它均匀分布在环上,那么即使数据再集中,很好地起到了负载均衡的作用。
- 自定义路由规则,TDDL 也支持
Matrix 层除了要解决数据访问路由问题之外,还需要顺带提供其他的功能(围绕着数据访问路由这个功能展开的):
- 规则的管理(上面讲过)
- SQL语句的解释、优化
和执行 - 各个子表查询出来结果集的Merge
- 事务的管理
Group层
中间的数据库层,是逻辑上的各个数据库节点,这层的作用在于数据库读写分离,功能特性:
- 数据库读写分离
- 主备切换
- 权重的选择(根据权重选择要去读哪些库)
- 数据保护,数据库down掉后的线程保护, 数据库挂掉后的线程保护,不会因为一个数据库挂掉导致所有线程卡死。
Atom层
底层数据源的管理,主要功能是:
- 动态创建,添加,减少数据源
- 底层对物理数据库做了代理,对单库的JDBC做了一层封装,执行底层单库的SQL
- 统计计数(线程数、执行次数)
3. 关于读写分离
读写分离最大的问题是数据复制(之前也讲过),通常有两种复制场景:
| 镜像复制 | 即主库和从库的数据结构是一模一样的,通常根据主库上的日志变化,在从库中执行相同的操作 |
| 非对称复制 | 主库与备库是以不同的方式分库的,它们的结构虽然相同,但是主备库中存储的记录是不相同的 为何要这样设计?主要是查询条件不同时,把请求分发到更加适合的库去操作。在TDDL中,数据复制使用了中间件愚公,真是个好名字。 比如:对于订单数据库,买家会根据自己的 ID 去查自己的交易记录,所以主库可以用买家 ID 分库,保证单个买家的记录在同一个数据库中。但是卖家如果想看交易记录的话可能就得从多个库中进行查询,这时候可以利用卖家 ID 进行分库作为备库,这样一来主备库的复制就不能简单的镜像复制了 |
4. 执行流程
client发送一条SQL的执行语句,会优先传递给Matrix层。由Martix 解释 SQL语句,优化,并根据查询条件路由到各个group,转发sql进行查询,各个group根据权重选择其中一个Atom进行查询,各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client。

也可以拆分成下图
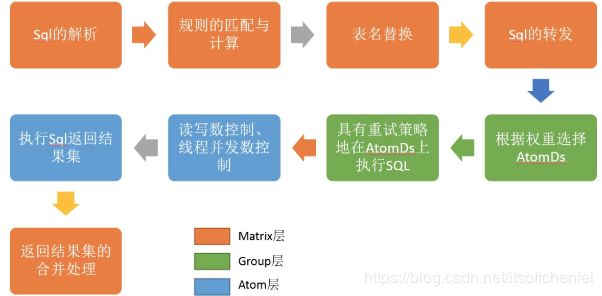
稍微解析下可能存在理解差异点:
- 规则的匹配与计算,定义数据库怎么进行分库分表
- 表名替换,查询语句是select * from A.B limit 10(A为库名,B为表名)。但底层其实会把它替换为类似select * from A_000.B_001,select * from A_000.B_002,select * from A_001.TABLE_001这样的形式
- 根据权重选择AtomDs,通常会在主节点和副节点上读取数据,只在主节点上写入数据
- 具有重试的策略地在AtomDs上执行SQL,可以防止单个的AtomDs发生故障
- 执行sql,返回结果集,Atom底层利用druid进行连接池的管理
5. 结果集合并
tddl的结果集合并也没有什么高科技,同Elasticsearch的深度的分页问题是一样的,都会极大的浪费分布式系统的资源。比如:
limit这样的查询因为会在每个子表中执行,所以对于limit 100000,2 这样需要深度分页的查询是很浪费资源的,相当于每个子表都查询了100000条以上的数据,合并完最后返回给客户端两条。
6. 全局sequence的生成
在单库单表的情况下,直接由数据库层面来设置一个唯一自增的主键就可以满足需求。在分库分表下,TDDL提供了TDDL Sequence的方案来解决这样的问题。
原理:基于数据库更新+内存分配:在数据库中维护一个ID,获取下一个ID时,会对数据库进行ID=ID+100 WHERE ID=XX,拿到100个ID后,在内存中进行分配 。
单机房的多库多表
比如有这样的配置,group数量为2(库),步长为1000。
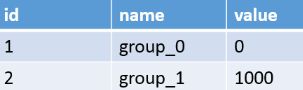
应用启动的时候,可能某一个节点上去取id,随机取到了group_0,那么这台机器上的应用会拿到0-999这一千个id。另外一个节点可能随机取到了group_1,占用了1000-1999这一千个id。而取回来id会缓存在应用的本地内存,当应用用完这批或者重启时才会重新向sequence获取id序列。这样从gourp_0中产生的id序列就为 0-999,2000-2999,4000-4999...,而gourp_1就产生了1000-1999,3000-3999...。
注:存在物理表中的主键自然不能保证严格递增
多机房的多库多表
前面的单机房多库多表,其实是一个数据源,对应了一个逻辑上的库。而两个机房的Sequence生成相当于是两个库,有两个数据源,同时这两个数据源还需要相互间进行同步。也就是说,那么两个的数据库的主键也必须的全局唯一,不能发生冲突的,TDDL提供了一个单元化多机房的解决方案。
两个机房相当于两个单元,每个单元配置数据源时,通过unit的接口,可以获取当前的总的单元数和当前所属的单元。
比如现在有两个单元:A和B,每个单元里会读到相同的A,B单元顺序. 最终在A单元会读到自己是在第一个位置,B单元会读到自己是第二个位置。B单元启动时会自动为A单元预留一个空位:因为B在第二个位置,就给A第一个位置上加上DUMMY-OFF。相当于两边的其他配置一样,但A单元用了一半。B单元用了一半,各自给那一边留了空位。
A单元配置:
GROUP_0
DUMMY-OFF
B单元配置:
DUMMY-OFF
GROUP_1
基于这样的A/B单元的配置方式,可以达到一种效果:A/B单元各自在确定自己的ID段时,不会使用另一个单元的ID段。比如假定步长为1000,杭州的机房是A单元,拿到的id应该就是0-999,2000-2999…,而美国的机房对应的B单元,拿到的id应该就是1000-1999,3000-3999…最终的解决方法可能与单机房类似。但具体实现,这里利用了占位符或者说是预留空位的这样的机制,使得多个数据源可以生成全局唯一的Sequence。
7. 分区片键规则介绍
规则是TDDL的核心组件之一,也是用户在使用时最主要要配置的信息。规则主要解决的问题维护一张逻辑表到一张或者多张物理表的映射关系,如何定义一个规则,决定了数据库如何进行分库分表,也极大的影响你查询的效率。
规则:user_id,1_number,4
规则解析:
user_id:代表分区键(列的字段名)
1_number:当前的数据自增步长和类型(下划线_做为分隔符),字段类型支持number,hour,date,month,year
4:分表总数,当你全表扫描时需要遍历的表的数量
比如:select * from user where user_id>2
根据1_number,起始给定的参数值是2,每次枚举都会+1,计算顺序:
1.user_id = (2+1=3)%4 运算得到 user_03,枚举次数1
2.user_id = (3+1=4)%4 运算得到 user_00,枚举次数2
3.user_id = (4+1=5)%4 运算得到 user_01,枚举次数3
4.user_id = (5+1=6)%4 运算得到 user_02,枚举次数4
最终TDDL会将请求转发到user_03,user_00,user_01,user_02这四子表上进行执行比如:select * from user where user_id>2 and user_id <=4
枚举到 user_03 ,user_00,这两张表,不会再枚举下去,并转发执行
如果查询的字段并不是分区片键,比如user_name,会怎样?
tddl就会进行全库的扫描,把请求转发到所有的表上进行执行。因此合理的定义分区片键是提高查询效率的关键。
8. SQL的优化器
SQL的优化的主要作用是缩小SQL需要查找的范围,减少SQL需要执行的步骤,减少跨库的操作。
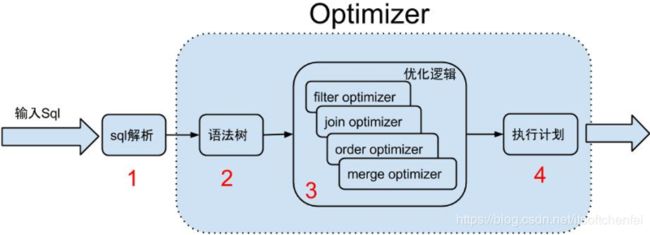
这里重点讲Join优化:
核心的思路就是把数据过滤的部分提前,使得最后join所需要操作的数据尽量少,因为join是代价最高的操作之一。如果是跨库的join,则两边会先根据join的字段进行排序,再根据排好序的列表进行以按序进行匹配,避免了两边都是很大数据量的表进行笛卡儿积再进行过滤的操作。这个技巧在常见的开源的数据集成工具Pentaho Data Integration(or Kettle)里,对于跨库两个数据流需要merge join的情况,就指定了两个数据流必须先按照Join的关键词排序才可以join。
A join B on A.id = B.id where A.name = 1 and B.title = 2
优化后:A.query(name = 1) join B.query(title = 2) on A.id
A join B on A.id = B.id where A.id = 1
优化后: A.query(id = 1) join B.query(id = 1)。如果前面name=1和title=2发现hash后再同一个库中,这样还避免的跨库join,只要在该group本地执行join即可。
A join B on A.id = B.id时,id两个字段在两张表的hash方式相同,发现hash(A.id)和hash(B.id)的库在同一个库中,可以下推至数据库本地节点解决问题。
引用资料
TDDL的使用介绍