我们都知道 HTTP 是无状态的,用户每次打开 web 页面时,服务器都打开新的会话,而且服务器也不会自动维护客户的上下文信息,那么服务器是怎么识别用户的呢?

这就是本文今天要讲解的内容。当服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是 session 和 cookie。
Session 和 Cookie
session 是保存在服务器端的,用于标识用户,并且跟踪用户的一种上下文保持机制。当服务器创建了一个 Session 时,给客户端发送的响应报文包含了 Set-Cookie 字段,其中有一个名为 sid 的键值对,这个键值对就是 Session ID。客户端收到后就把 Cookie 保存在浏览器中,并且之后发送的请求报文都包含 Session ID
Cookie 由服务器生成,发送给浏览器,浏览器把 Cookie 以 kv 形式保存到某个目录下的文本文件内。是客户端保存用户信息的一种机制,用来记录用户的一些信息,它是实现 Session 的一种方式。

浏览器会根据响应报文里的一个叫做 Set-Cookie 的首部字段信息,将其保存在本地。
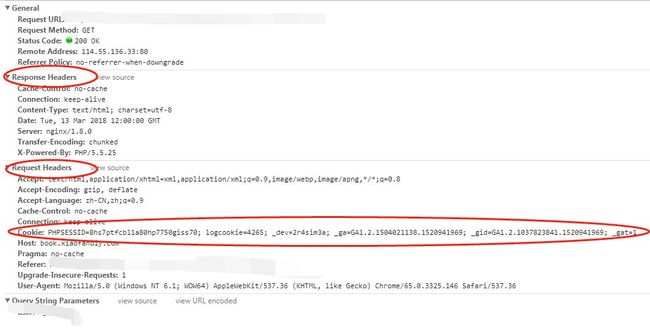
当下一次请求时会把该 Cookie 发送给服务器,之后服务端发现客户端发送过来的 Cookie 后,会检查是那个客户端发送过来的请求,然后根据服务器上的记录,最后得到了之前的状态信息。

我们经常看到登录的时候,有个下次自动登录的选项,就是根据这个原理来实现的。既然浏览器能实现免密登录的功能,那么我们用代码如何来实现呢?
这里有两个登录案例,看完之后你就知道如何实现了。
案例一:豆瓣登录
在这里我们使用 Python 中的 LWPCookieJar ,它是管理 cookie 的工具,可以将 cookie 保存到文件,在文件中读取本地 cookie 数据到程序中,一般用到以下两种方法:

源码
1. 将登录成功的 cookie 写入到本地文件
# 实例化一个 LWPCookieJar 对象,并设置保存 cookie 的文件
session = requests.session()
session.cookies = LWPCookieJar(filename='DouBanCookies.txt')
在使用代码登录成功之后,使用 session.save() 将自动将 cookie 写入到设置的 cookie 文件中
deflogin():
name = input("输入账户:")
password = input("输入密码:")
url ="https://accounts.douban.com/j/mobile/login/basic"
data = {
"ck":"",
"name": name,
"password": password,
"remember":"True",
"ticket":"",
}
response = session.post(url, data=data)
print(response.text)
session.cookies.save()# 保存 cookie
写入之后,会在当前目录生成 DouBanCookies.txt 的文件,如下图所示:

2. 直接使用该文件中的 cookie 实现免密登录
直接使用 load 方法,从文件中获取 cookie 到代码中。其中 load 方法有两个可选值,ignore_discard 主要是忽略关闭浏览器丢失, ignore_expires 是忽略 cookie 失效。可根据自己的实际场景自由选择。
session.cookies.load(ignore_discard=True)
使用 cookie 登录之后,可以自主验证一下是否登录成功。一般选择访问个人主页,查看响应内容,判读是否登录成功。完整代码如下:
# coding: utf-8
importrequests
fromscrapyimportSelector
fromhttp.cookiejarimportLWPCookieJar
session = requests.session()
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
session.headers = headers
session.cookies = LWPCookieJar(filename='DouBanCookies.txt')# 实例化一个LWPCookieJar对象
deflogin():
name = input("输入账户:")
password = input("输入密码:")
url ="https://accounts.douban.com/j/mobile/login/basic"
data = {
"ck":"",
"name": name,
"password": password,
"remember":"True",
"ticket":"",
}
response = session.post(url, data=data)
print(response.text)
session.cookies.save()
verify_login()
defverify_login():
mine_url ="https://www.douban.com/mine/"
mine_response = session.get(mine_url)
selector = Selector(text=mine_response.text)
user_name = selector.css(".info h1 ::text").extract_first("")
print(f"豆瓣用户名:{user_name.strip()}")
defcookie_login():
try:
# 从文件中加载cookies(LWP格式)
session.cookies.load(ignore_discard=True)
print(session.cookies)
exceptException:
print("Cookies未能加载,使用密码登录")
login()
else:
verify_login()
if__name__ =="__main__":
cookie_login()
案例二:新榜登录
除了使用 Python 中自带的 cookie 管理工具之外,我们还可以自己创建 cookie 文件,写入到本地文件或者 Redis 中。
例如,新榜的登录,通过我的测试发现,主要是校验 token 和用户名这两个参数。而 token 在登录成功后,可以在响应内容中找到。那么我们就可以自己创建 cookie 文件,一般是 .txt 或者.json 文件。
cookies = {
"name": self.account,
"token": token,
"useLoginAccount":"true"
}
withopen("XinBangCookies.txt",'w')asf:# 将cookies保存到本地
f.write(str(cookies))
然后读取 cookie 加载到代码中
withopen("XinBangCookies.txt","r")asf:
cookies = f.read()
cookies = eval(cookies)
cookie ="; ".join((key +"="+ value)forkey, valueincookies.items())
self.session.headers.update({"Cookie": cookie})
使用本地 cookie 登录后,可以选择访问登录之后才能访问的地址进行验证,具体代码就不贴了,逻辑和上面的案例差不多,只是处理方法不一样。
总结
本文主要是介绍 session 和 cookie 的一些基本概念,以及两者之间的区别。同时给大伙介绍了两种用代码处理 cookie 的案例,这里要注意一下 cookie 存在时效性,如果失效了需要重新用密码登录。感兴趣的朋友可以根据以上两个案例去练练手噢。如果觉得本文不错,帮忙点下右下方的好看吧~~