1. MySQL集群企业级架构方案
在实际生产环境中,一主多从的数据库环境是最常采用的数据库架构,那么应该怎么分配不同的主从以向用户提供更高效的访问呢?
1.1 根据对数据库的访问请求实现读写分离
在实际生产环境中,99%的业务场景都是读多写少,而一主多从的环境恰恰是主不容易扩展,而从更容易增加多台的环境,因此,把更少请求的写访问业务调度到主库上,而把读请求较多的业务调度到多个从库上,就是一个很好的策略。
1.2 根据不同的业务拆分多个从库以提供访问
从大的方向来分,用户的请求主要有两种,一个是外部用户的访问请求,一个是内部用户的访问请求。而大多数情况下,都是外部用户访问请求更重要,需要更好的用户体验效果,而对内部用户访问请求的体验要求相对外部来说就要低得多,甚至宕机一段时间也不会有太大的影响。
因此,首先要对外部用户和内部用户读数据库的访问请求进行分离,拿一主五从的数据库环境来说,可以让前三个从库(利用读写分离软件或LVS等工具实现负载均衡)提供外部用户读请求访问,让第四个从库用于内部用户读访问(业务后台、数据分析、搜索业务、财务统计、定时任务、开发查询等),让第五个数据库用于数据库定时全备份以及增量备份(开启binlog功能)。整个逻辑图如下图所示:
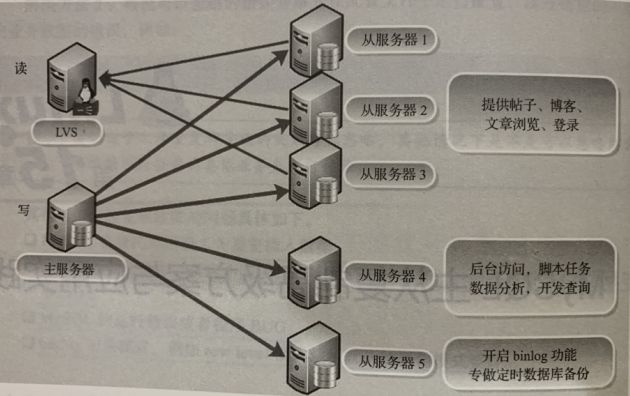
1.3 实现对主库的高可用
一主多从的MySQL数据库环境,最脆弱的就是主库了,不但扩展困难,所承受的压力也很大,而且,还会面临宕机没有机器替补的问题。
MySQL的高可用方案具体如下:
1)heartbeat+dbrd+mysql方案
此方案是通过dbrd工具对主数据库服务器实现基于block的异机物理复制(类似于网络raid1),速度很快,但缺点是与备节点对应的复制的数据分区是不可见状态(即不能被访问),除非主节点宕机,备节点才可提供访问),浪费一台机器,早起受MySQL官方推荐,现如今在企业场景中使用的不是很多了,但仍然不失为一套成熟的MySQL高可用方案。
2)mysql+MMM(Master-Master replication Manager)方案
此方案是通过MySQL的replication实现的主主之间的数据同步,同时还可以实现slaves负载均衡等功能,但业界普遍认为MMM无法完全保持数据的一致性,因此对数据一致性要求较高的数据库场景很少采用,导致该方案也逐步没落了。
3)mysql MHA(Master High Availability)+keepalived方案
MHA是业界公认的MySQL高可用的相对来说比较成熟的方案,此方案也是通过MySQL的replication实现的数据库服务器之间的数据同步,同时还可以实现从库负载均衡、主库宕机后自动选择最优的从库,将其切换为主库,并尽最大的努力对所有的库做数据补全操作一直到最新,并对其他从库和新主库实现复制,再加上keepalived是为了实现VIP漂移,因此该方案是业界采用较多的方案。
2. MySQL企业级备份策略方案
MySQL主从复制的企业应用场景之一就是作为数据库的一个异地相当于实时性的备份,但是,这个实时性备份有一个无法解决的问题,就是如果主库存在语句级误操作(例如“drop database oldboy;”),那么从库也会执行“drop database oldboy;”,这样MySQL主从库就都删除了该数据,因此,除了MySQL主从复制备份之外,还需要定时的数据库备份方案。
2.1 利用MySQL主从复制的从库进行数据备份策略
定时备份比较常用的策略是使用mysqldump(逻辑备份)以及Xtrabackup(物理备份)进行备份。
虽然这二者都支持热备功能,但是由于在备份期间消耗了大量的磁盘IO以及内存、CPU等系统资源,导致为用户提供服务的能力大大减弱,哪怕是在访问低谷时进行的备份,还是会影响一部分用户访问。
高性能高并发业务场景下进行数据库备份时,可以选择MySQL主从复制中的一个不对外服务的从库作为定时数据库备份服务器,备份策略具体如下。
例如上图所示的是一主多从的数据库集群环境,可以选择在一台从库上进行备份(Slave5),而不参与提供外部用户访问,此时需要在该从库(Slave5)中开启binlog功能,其逻辑如上图所示。
2.2 利用MySQL主从复制的从库进行数据备份实战的步骤
1)选择一个不对外提供服务的从库,这样可以确保其与主库更新最接近,专门做数据备份用,从而告别在主库上进行备份但影响主库访问的方案。
2)开启从库的binlog功能,目的是将来数据丢失时可使用binlog进行增量恢复,注意,此处最好开启从库的binlog功能,而不是在数据恢复时拿主库的binlog进行数据恢复。
3)以下提供3种常见的备份方案:
- 当数据量低于30GB时,可采用mysqldump逻辑备份。
- 当数据量大于30GB时,可采用Xtrabackup物理热备工具。
- 采用从库备份也可以使用冷备的方案,即备份时可以选择停止从库的SQL线程,停止应用SQL语句到数据库,I/O线程将继续保持工作状态,执行命令为“stop slave sql_thread;”,备份方式可以采取cp、tar(针对“/data”目录)工具进行备份,最后把全备文件和binlog数据发送到备份服务器上留存即可。
3. MySQL主从复制生产场景的常见延迟原因及防范方案
问题一:一个主库的从库太多,易导致复制延迟
建议从库数量在3~5个为宜,要复制的从节点数量过多,会导致主库系统及网络带宽压力过大,从而最终导致从库复制延迟。
问题二:从库硬件比主库差,易导致复制延迟
master和slave的硬件配置应该保持一致,主从库硬件差异包括磁盘IO、CPU、内存等各方面因素,在高并发大数据量写入的场景下易造成复制的延迟。
问题三:慢SQL语句过多,易导致复制延迟
假如有一条SQL语句,在主库上执行了20秒完毕,此时到从库上可能也得20秒左右才能查到数据,这样就延迟了20秒。
SQL语句的优化应作为常规工作不断地进行监控和优化,如果是单个SQL的写入时间过长,那么可以在修改后分多次写入。通过查看慢查询日志或“show full processlist”命令找出执行时间长的查询语句或者大的事务,建立索引或者分拆多条小的语句执行。
问题四:主从复制的设计问题,易导致复制延迟
例如,主从复制单线程中,如果主库写并发太大,来不及传送到从库则会导致延迟。
MySQL5.6可以支持SQL多线程复制,但其也是针对不同的库级别的,大型门户网站则可能会开发多线程同步功能。
问题五:主从库之间的网络延迟,易导致复制延迟
主从库的网卡、网线、连接的交换机等网络设备都可能会成为复制的瓶颈,导致复制延迟,另外,跨公网主从复制很容易导致主从复制延迟。
问题六:主库读写压力太大,导致复制延迟
主库硬件要搞好一点,架构的前端要加buffer以及cache层,以减轻主库的压力。
4. MySQL主从复制数据一致性企业级方案
4.1 采用半同步复制方案
主从不一致时因为主从复制默认是异步的复制方式,即主库完成后,binlog将数据传输到从库并写到中继日志中,最后在由从库解析执行到从库里。而半同步复制方案实际上就是实时复制方案,即让主库和从库同时写入完毕,再把请求结果返回给客户,这样就可以实现主从是实时一致性的。该方案的优点可以最大限度地保证主从一致,但是增加了主库写入的时间,超过实时同步设置的超时时间都会转化成异步复制。
4.2 当复制发生延迟时让程序改读主库
1)当数据写入后,程序在从库读不到该数据时,自动判断并请求主库。此方案有个小问题,就是对于新数据没有任何问题,但是对于更新的数据,可能会在从库读到旧的数据,从而不会再读取主库,另外还会增加主库的压力。
2)可以部署一个缓存服务器,当数据写入数据库的同时,将更新主库的数据的key、时间戳以及数据超时时间(例如1秒)写入到缓存服务器中,然后在进行读请求访问的时候,先查缓存服务器,如果有对应的key,则表示刚写完不到1秒,从库也有可能还没有,所以主动读主库,如果缓存里没有对应的key,则表示更新的主库对应key的数据已经写完超过1秒了,此时从库也应该有了,如果此时从库中还没有,则可以再请求写库。该方案的缺点是逻辑复杂,开发成本很高,并且还会增加主库的压力,最后不管key的超时时间设置的是大还是小,如果复制发生了故障,那么理论上还可能会导致访问到旧的数据。
3)在产品程序逻辑上,应尽量延缓(例如1秒)用户访问刚更新过的数据,为数据库主从复制争取同步的时间,例如,自动返回设置3、2、1等,或者增加一个点击按钮。很多时候解决问题未必是技术层面的事情,也可以从产品层面解决问题。
4)采用读写分离工具实现路由数据到主库,一般是大型企业自研,常规读写分离工具会将写请求自动路由到主库,将从请求路由到从库。此时,可以让工具路由在写请求的同时记录写(增加或更新)请求对应的key和更新的时间,若有相同的请求访问这个key对应的读数据,则判断一下这个写请求延续的时间是否超过了指定的时间(例如1-2秒,根据业务需要来指定),如果未超过,则让这个读请求读主库。
5. MySQL多线程复制解决复制延迟实践
1)查看当前slave服务器的SQL线程状态,提示为“Waiting for master to send event”,表示等待主库发送事件日志:
mysql> show processlist;
+----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+
| 12 | system user | | NULL | Connect | 42280 | Waiting for master to send event | NULL |
| 13 | system user | | NULL | Connect | 41476 | Slave has read all relay log; waiting for the slave I/O thread to update it | NULL |
| 21 | root | localhost | NULL | Query | 0 | init | show processlist |
+----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+
3 rows in set (0.05 sec)
2)检查多线程的参数配置:
mysql> show variables like '%parallel%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| slave_parallel_workers | 0 | ---默认为0,即单线程复制
+------------------------+-------+
1 row in set (0.07 sec)
3)停止主从复制:
mysql> stop slave;
Query OK, 0 rows affected (0.09 sec)
mysql> set global slave_parallel_workers = 4; ---在线修改为4个线程
Query OK, 0 rows affected (0.02 sec)
mysql> show variables like '%parallel%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| slave_parallel_workers | 4 | ---参数修改成功
+------------------------+-------+
1 row in set (0.01 sec)
4)启动数据库查看修改效果:
mysql> show processlist;
+----+-------------+-----------+------+---------+------+-----------------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+------+-----------------------------------------------------------------------------+------------------+
| 21 | root | localhost | NULL | Query | 0 | init | show processlist |
| 22 | system user | | NULL | Connect | 100 | Waiting for master to send event | NULL |
| 23 | system user | | NULL | Connect | 99 | Slave has read all relay log; waiting for the slave I/O thread to update it | NULL |
| 24 | system user | | NULL | Connect | 99 | Waiting for an event from Coordinator | NULL |
| 25 | system user | | NULL | Connect | 99 | Waiting for an event from Coordinator | NULL |
| 26 | system user | | NULL | Connect | 99 | Waiting for an event from Coordinator | NULL |
| 27 | system user | | NULL | Connect | 99 | Waiting for an event from Coordinator | NULL |
+----+-------------+-----------+------+---------+------+-----------------------------------------------------------------------------+------------------+
7 rows in set (0.00 sec)
从输出中可以看到,已经启动了4个SQL线程,如果希望永久生效,则可同时在my.cnf中配置该参数,无须重启:
[mysqld]
slave_parallel_workers = 4
6. 让MySQL主从复制的从库只读访问
read-only参数选项可以让从数据库服务器只允许具备主从复制权限的线程或具有SUPER权限的数据库用户进行更新,从而确保从服务器不接受来自用户端的其他普通用户的更新。
6.1 read-only参数允许数据库更新的条件
- 具有SUPER权限的用户可以更新,不受read-only参数影响,例如,管理员root
- 来自从服务器具备主从复制权限的线程可以更新,不受read-only参数的影响,例如,前文的rep用户
在生产环境中,可以在从库Slave中使用read-only参数,以确保从库数据不被非法更新。
6.2 如何配置read-only参数
方法一:启动数据库时直接带“--read-only”参数启动。
mysqld_safe --read-only --user=mysql &
方法二:在my.cnf中[mysqld]模块下加read-only参数,然后重启数据库。
[mysqld]
read-only
7. MySQL主从复制读写分离Web用户生产设置方案
7.1 主库和从库使用不同的用户,授权不同的权限
主库上对web_w用户的授权如下:
用户:web_w 密码:oldboy123 端口:3306 主库VIP:192.168.150.130
权限:SELECT,INSERT,UPDATE,DELETE
命令:GRANT SELECT,INSERT,UPDATE,DELETE ON `web`.* TO 'web_w'@'192.168.150.%' identified by 'oldboy123';
从库上对web_r用户单独授权如下:
用户:web_r 密码:oldboy123 端口:3306 从库VIP:192.168.150.131
权限:SELECT
命令:GRANT SELECT ON `web`.* TO 'web_r'@'192.168.150.%' identified by 'oldboy123';
提示:这种方法不是很专业,而且从库上也会存在web_w用户,一旦被开发等人利用,就可以对从库进行写库,这种授权也会对数据库带来潜在风险。
7.2 网站程序访问主库和从库时使用一套用户密码
主库:用户为web,密码为oldboy123,端口为3306,写IP为192.168.150.130
从库:用户为web,密码为oldboy123,端口为3306,读IP为192.168.150.131
从外表上看,只有读写分配的IP不同,其他都是相同的。运维人员应尽量为开发人员提供方便,如果是数据库前端有DAL层,(实现了读写分离),则可以只为开发人员提供一套用户、密码、端口、VIP,这样就更专业了,剩下的都由运维人员来完成即可。
下面是使用同一个Web连接用户授权访问的方案。
方法1:主库和从库使用相同的用户,但授予不同的权限。
主库上对web用户的授权如下:
用户:web 密码:oldboy123 端口:3306 主库VIP:192.168.150.130
权限:SELECT,INSERT,UPDATE,DELETE
命令:GRANT SELECT,INSERT,UPDATE,DELETE ON `web`.* TO 'web'@'192.168.150.%' identified by 'oldboy123';
从库上对web用户的授权如下:
用户:web 密码:oldboy123 端口:3306 从库VIP:192.168.150.131
权限:SELECT
提示:由于主库和从库是同步复制的,所以从库上的web用户会自动与主库的一致,即无法实现只读select的授权。
要实现方法1中的授权方案,并且要求操作严谨,应采用如下两个方法。
一是在主库上创建完web用户和权限之后,在从库上revoke收回对应的更新权限(insert、update、delete):
主库执行:
GRANT SELECT,INSERT,UPDATE,DELETE ON `web`.* TO 'web'@'192.168.150.%' identified by 'oldboy123';
从库执行:
REVOKE INSERT,UPDATE,DELETE ON web.* FROM 'web'@'192.168.150.%';
二是忽略授权库mysql同步,主库的my.cnf配置参数如下:
binlog-ignore-db = mysql ---mysql库不记录Binlog日志
replicate-ignore-db = mysql ---忽略复制MySQL库
提示:上面参数的等号两边必须要有空格。
三是在从库上设置read-only参数,让从库只读。
主库从库:主库和从库使用相同的用户,授予相同的权限(非ALL权限)。
用户:web 密码:oldboy123 端口:3306 主库VIP:192.168.150.130,从库VIP:192.168.150.131
权限:SELECT,INSERT,UPDATE,DELETE
命令:GRANT SELECT,INSERT,UPDATE,DELETE ON `web`.* TO 'web_w'@'192.168.150.%' identified by 'oldboy123';
由于从库设置了read-only,非super权限是无法写入的,因此,通过read-only参数就可以很好地控制用户非法将数据写入从库。
生产工作场景的设置方案具体如下:
1)忽略授权库mysql同步,主库的配置参数如下:
binlog-ignore-db = mysql
replicate-ignore-db = mysql
2)主库和从库使用相同的用户,但授予不同的权限。
主库上对web用户的授权如下:
用户:web 密码:oldboy123 端口:3306 主库VIP:192.168.150.130
权限:SELECT,INSERT,UPDATE,DELETE
命令:GRANT SELECT,INSERT,UPDATE,DELETE ON `web`.* TO 'web'@'192.168.150.%' identified by 'oldboy123';
从库上对web用户的授权如下:
用户:web 密码:oldboy123 端口:3306 从库VIP:192.168.150.131
权限:SELECT
3)在从库上设置read-only,增加第三个保险。
8. MySQL主从延迟复制方案及恢复实践
8.1 MySQL主从延迟复制方案介绍
当主库有逻辑的数据删除或者错误更新时,所有的从库都会进行错误的更新,从而导致数据库的所有数据都异常,即使有定时的备份数据可以用于数据恢复,特别是数据库的数据量很大时,恢复时间也会很长,在恢复期间,数据库数据被删除或者出现错误数据都会影响正常的访问体验。
而延迟复制就可以很好地解决这个问题。例如,可以设定某一个从库和主库的更新延迟1个小时,这样当主库数据出现问题以后,1个小时以内即可发现,可以对这个从库进行无害恢复处理,使之依然是正确的完整的数据,这样就省去了数据恢复占用的时间,用户体验也会有所提高。
8.2 MySQL主从延迟复制配置实践
MySQL 5.6版本的延迟复制配置,是通过在Slave上执行以下命令实现的:
CHANGE MASTER TO MASTER_DELAY = N; ---可在配置延迟从库Change Master时直接加上MASTER_DELAY选项
该语句设置Slave数据库延时N秒后,再与主数据库进行数据复制,具体操作为登录到Slave数据库服务器,然后执行如下命令:
mysql> stop slave;
Query OK, 0 rows affected (0.03 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 20;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> show slave status\G
---省略若干---
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
---省略若干---
SQL_Delay: 20 ---延迟20秒后进行复制
SQL_Remaining_Delay: NULL ---还剩多少秒执行复制
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it ---SQL线程的状态
---省略若干---
1 row in set (0.00 sec)
主库插入数据:
mysql> create database lanlan;
Query OK, 1 row affected (0.07 sec)
主库插入完数据1秒后,从库执行“show databases;”查看数据是否及时同步了:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ales_python |
| alex_python |
| mysql |
| performance_schema |
| test |
+--------------------+
6 rows in set (0.01 sec)
从库上并没有主库上创建的数据库lanlan,此时可间歇性地执行“show slave status\G”查看延迟的参数状态:
mysql> show slave status\G
---省略若干---
SQL_Delay: 20
SQL_Remaining_Delay: 13 ---剩余13秒执行复制
Slave_SQL_Running_State: Waiting until MASTER_DELAY seconds after master executed event
---省略若干---
1 rows in set (0.01 sec)
mysql> show slave status\G
---省略若干---
SQL_Delay: 20
SQL_Remaining_Delay: 9 ---剩余9秒执行复制
Slave_SQL_Running_State: Waiting until MASTER_DELAY seconds after master executed event
---省略若干---
1 rows in set (0.01 sec)
mysql> show slave status\G
---省略若干---
SQL_Delay: 20
SQL_Remaining_Delay: NULL ---复制完成后,没有新数据更新的状态
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
---省略若干---
1 rows in set (0.01 sec)
在从库没有更新数据,并且处于延迟复制还没到时间的期间,查看从库的中继日志:
[root@db02 data]# pwd
/application/mysql/data
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
create database lanlan ---中继日志中的确已经有了创建的语句,说明ro线程还是实在工作的
8.3 MySQL主从延迟复制原理解析及结论
MySQL的延迟复制实际上影响的只是SQL线程将数据应用到从数据库,而I/O线程早已把主库更新的数据写到了从库的中继日志中,因此,在延迟复制期间,即使主库宕机了,从库到了延迟复制的时间,也依然会把数据更新到与主库宕机时一致。
8.4 使用MySQL主从延迟复制进行数据恢复实践
在企业中,我们应根据业务需求为延迟复制指定一个时间段,例如1个小时后进行该从库复制,那么在这一个小时之内,如果主库误更新了数据,其他的从库也都会依样误更新数据,那么如何将这个延迟的从库恢复到正常没有误更新数据前的完整状态呢?
1)模拟环境,将从库延迟调整为3600秒
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 3600;
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> show slave status\G
---省略若干---
SQL_Delay: 3600
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
---省略若干---
1 row in set (0.00 sec)
2)模拟在主库写入数据,每隔5秒写入1个库,就当是模拟用户写入数据:
[root@db01 ~]# for n in {1..5}
> do
> mysql -e "create database oldboy$n"
> sleep 5
> done
3)模拟人为破坏数据,也可以是不带where的update语句:
mysql> drop database oldboy5; ---删除oldboy5数据库,后面要做的就是把这个数据库恢复回来,别的数据还得保留
Query OK, 0 rows affected (0.07 sec)
mysql> show databases like 'oldboy%';
+--------------------+
| Database (oldboy%) |
+--------------------+
| oldboy1 |
| oldboy2 |
| oldboy3 |
| oldboy4 |
+--------------------+
4 rows in set (0.04 sec)
此时,所有的从库都已经是坏数据了,只有延迟从库是好的,但是是一个小时之前的数据
4)当数据库出现误删数据的情况时(特别是update不加条件破坏数据),要想完整恢复数据,最好选择对外停止访问措施,此时需要牺牲用户体验,除非业务可以忍受数据不一致,并且不会被二次破坏。从库可以适当地继续开放给用户读访问,但是也可能会导致用户读到的数据是坏的数据,这里就需要去衡量数据一致性和用户体验的问题。这里是使用iptables封堵用户对主库的所有访问:
[root@db01 ~]# iptables -I INPUT -p tcp --dport 3306 ! -s 192.168.150.132 -j DROP
---非192.168.150.132禁止访问数据库3306端口,130是主库IP,192.168.150.132为远程连接SSH客户端的IP
5)登录主库执行“show processlist;”对binlog是否全部发送到该延迟从库进行确认,也可以登录延迟从库执行“show processlist;”对从库IO线程是否完全接收binlog进行状态查询确认:
mysql> show processlist;
+----+------+-----------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
| 16 | rep | 192.168.150.131:49328 | NULL | Binlog Dump | 2027 | Master has sent all binlog to slave; waiting for binlog to be updated | NULL |
| 23 | root | localhost | NULL | Query | 0 | init | show processlist |
+----+------+-----------------------+------+-------------+------+-----------------------------------------------------------------------+------------------+
2 rows in set (0.02 sec)
---主库已经发送完所有的Binlog日志到从库了
6)在从库上执行“stop slave;”暂停主从复制,并查看数据库是否已同步过来:
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ales_python |
| alex_python |
| lanlan |
| mysql |
| performance_schema |
| test |
+--------------------+
7 rows in set (0.00 sec)
---因为还未到延迟时间,因此数据不会同步到该延迟从库
7)根据relay-log.info记录的SQL线程读取relay-log的位置,解析未应用到从库的relay-bin日志:
[root@db02 data]# pwd ---进入到中继日志所在的目录
/application/mysql/data
[root@db02 data]# ll *relay* ---查看中继日志的相关信息
-rw-rw----. 1 mysql mysql 172 Jun 9 11:04 db02-relay-bin.000001 ---中继日志
-rw-rw----. 1 mysql mysql 888 Jun 9 11:28 db02-relay-bin.000002
-rw-rw----. 1 mysql mysql 48 Jun 9 11:04 db02-relay-bin.index ---中继日志索引
-rw-rw----. 1 mysql mysql 59 Jun 9 11:39 relay-log.info ---SQL线程读取中继日志的位置信息
-rw-rw----. 1 mysql mysql 83 Jun 9 11:04 worker-relay-log.info.1
-rw-rw----. 1 mysql mysql 83 Jun 9 11:04 worker-relay-log.info.2
-rw-rw----. 1 mysql mysql 83 Jun 9 11:04 worker-relay-log.info.3
-rw-rw----. 1 mysql mysql 83 Jun 9 11:04 worker-relay-log.info.4
[root@db02 data]# cat relay-log.info ---查看中继日志应用的位置信息
7
./db02-relay-bin.000002 ---SQL线程读取中继日志的文件名信息
282 ---SQL线程读取中继日志的位置信息
db01-bin.000001
738
3600
4
1
8)解析SQL线程未解析的全部relay-bin中继日志数据,由于本例模拟数据量不够大,因此本例中只有db02-relay-bin.000002一个中继日志,实际工作中可能会有多个,将它们一并解析到一个指定文件或者分成不同的文件存放也可以。
[root@db02 data]# mysqlbinlog --start-position=282 db02-relay-bin.000002 > relay.sql
---根据上述的relay-log.info的中继日志文件和位置信息进行中继日志解析
9)找到破坏数据库数据的SQL语句,并从已解析的SQL语句中将其删除,这里使用的是“drop database oldboy5”:
[root@db02 data]# egrep "drop database oldboy5" relay.sql ---检查是否存在误删的SQL语句
drop database oldboy5
[root@db02 data]# sed -i '/drop database oldboy5/d' relay.sql ---删除误删的SQL语句
[root@db02 data]# egrep "drop database oldboy5" relay.sql ---检查删除结果
10)将解析后并处理好的relay.sql数据文件恢复到延迟从库:
[root@db02 data]# mysql < relay.sql
[root@db02 data]# mysql -e "show databases like 'oldboy%';"
+--------------------+
| Database (oldboy%) |
+--------------------+
| oldboy1 |
| oldboy2 |
| oldboy3 |
| oldboy4 |
| oldboy5 | ---之前删除的oldboy5数据库已经找回
+--------------------+
至此,利用延迟数据库恢复数据完毕,此时还需要将此从库提升为主库,将VIP指向该“延迟从库”,即作为新主库提供用户访问,然后,再对其他遭到破坏的主从数据库进行修复。