自动驾驶平台Apollo 2.5阅读手记:perception模块之camera detector
原文地址:https://blog.csdn.net/jinzhuojun/article/details/80875264
我们知道,无人驾驶系统中,感知(perception)模块是重中之重,而且一般都会是个大部头,子模块众多。为了保证准确率和鲁棒性,系统多会采用多传感器(如camera,LIDAR, RADAR等)融合。因为它们各有优劣,相互融合可以优势互补。其中,camera以其数据处理方便,算法相对丰富成熟,价格便宜,能提供纹理信息等诸多优点,成为了最基本的硬件配置。
在百度的Apollo无人驾驶平台(源码地址https://github.com/ApolloAuto/apollo)中,camera会用来检测车道线及场景中物体(车辆,自行车,行人等)。这是通过一个多任务网络来完成的。其中的encoder部分是Yolo的darknet,decoder分两部分:一部分是语义分割,用于车道线区域检测;另一部分为物体检测,用于物体检测。物体检测部分基于Yolo,同时还会输出物体的方向等3D信息,因此网络称为yolo3d。这些信息被输出后,就可以送到后续模块(如cc_lane_post_processor)中进一步处理。另外,比较巧妙的是,CNN网络中的某一层被拿来用作生成特征供后续模块(如tracker)使用。网络结构如下图:

其中框1部分为物体检测输出;框2部分为车道线的语义分割输出;框3部分为用作特征提取的其中一个卷积层输出。为了更好地理解如何使用这个模型进行道路的场景感知,我们通过官方自带的例子大体走一下流程(如何搭建环境和运行例子在之前的文章自动驾驶平台Apollo 2.5环境搭建已有描述)。yolo_camera_detector_test这个测试程序中有三个test。第一个是测试初始化;第二个测试物体检测和特征提取;第三个会检测车道线和场景中物体。第三个测试几乎综合了所有功能,所以我们主要看multi_task_test这个测试。首先看下涉及到的几个文件:在/apollo/models/perception/model/yolo_camera_detector目录下有两个配置文件config.pt和feature.pt,分别是camera detector模块和特征提取的配置。模型文件位于/apollo/modules/perception/model/yolo_camera_detector/yolo3d_1128目录下。其中的deploy.pt和deploy.md分别为网络的结构描述文件和权重文件。它们分别对应典型Caffe模型的prototxt和caffemodel文件。
例子中首先通过BaseCameraDetectorRegisterer::GetInstanceByName()函数创建YoloCameraDetector对象,它是BaseCameraDetector的实现类。Apollo中的模块实现类的工厂函数组织在类型为BaseClassMap的静态变量factory_map中。它是string到FactoryMap的映射;FactoryMap又是string到ObjectFactory指针的映射。以camera detector模块为例,首先在基类声明文件base_camera_detector.h中有:
REGISTER_REGISTERER(BaseCameraDetector);
#define REGISTER_CAMERA_DETECTOR(name) REGISTER_CLASS(BaseCameraDetector, name)宏REGISTER_REGISTERER(BaseCameraDetector)定义了BaseCameraDetectorRegisterer类。该宏定义于registerer.h文件中。之后实现类就可以通过REGISTER_CAMERA_DETECTOR进行注册,比如yolo_camera_detector.h中:
REGISTER_CAMERA_DETECTOR(YoloCameraDetector); 该宏会定义ObjectFactoryYoloCameraDetector,它是ObjectFactory的继承类。同时定义RegisterFactoryYoloCameraDetector()函数用于注册相关工厂函数,这个函数会在camera_process_subnode.cc文件的模块初始化函数InitModules()中被调用。对于其它模块也是类似的。上面这几个结构关系如图:

创建好YoloCameraDetector对象然后调用其初始化函数Init()。首先通过GetProtoFromFile()函数将detector的config文件(yolo_camera_detector_config.pb.txt)读入到成员变量config_中。从中读出yolo_root(/apollo/modules/perception/model/yolo_camera_detector)保存到yolo_root变量中。yolo_config为yolo_root目录下的配置文件config.pt。config.pt中的信息被读入并写到成员变量 yolo_param_中。之后依次调用以下函数初始化:
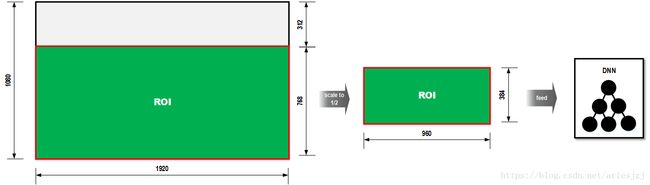
- load_intrinsic()函数根据配置文件计算ROI区域宽高。原始输入尺寸为1920x1080。默认配置下会截掉上面的312像素。留下下面的1920 x 768的区域作为ROI。而实际处理时会按比例resize成960 x 384分辨率。变量min_2d_height_为960 x 384分辨率下的检测物体高度阀值,也就是如果在960 x 384分辨率下高度小于17像素的物体会被忽略。min_3d_height也是类似的,3D边界框物体高度小于0.5米的也会被忽略。
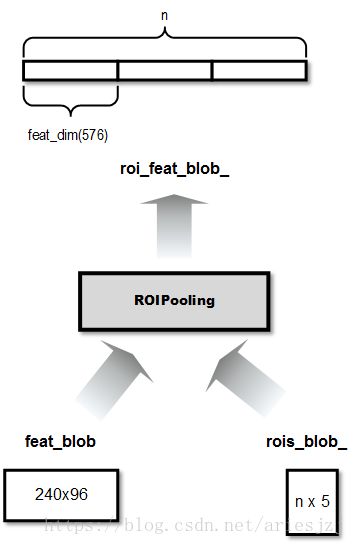
- init_cnn()函数用于初始化CNN执行环境。这里用的深度学习推理框架是CUDA加速的Caffe。如之前所说,网络结构描述位于deploy.pt,权重信息位于deploy.md。feature.pt是特征描述文件,它配置特征抽取方式,这些特征可以被后面处理任务所用。总得来说,网络输入结点只有一个,名为data。输出分三部分:seg_prob为语义分割结果;loc_pred, obj_pred, cls_pred, ori_pred, dim_pred, lof_pred, lor_pred为物体检测结果。conv3_3为图像的中间特征层,用于ROIPooling处理生成物体特征。obj_pred的输出的宽高是output_width_和output_height_(60 x 24)。seg_prob输出的宽高和输入的一样,为lane_output_width_和lane_output_height_(960 x 384)。用于特征提取的conv3_3层输出结点的宽高为240 x 96。本函数主要会创建CNNCaffe,它是CNNAdapter的实现类,主要封装Caffe相关操作。之后分别调用它的init()方法进行初始化。然后通过get_blob_by_name()函数根据配置文件中指定的输出blob名得到相应的blob对象,并得到相应的宽高信息。然后通过reshape_input()函数指定网络输入维度,也就是960 x 384。接着构造特征提取层,首先根据特征配置文件feature.pt中指定的将conv3_3这个blob拿出来,然后创建ROIPoolingFeatureExtractor对象并调用其init()函数初始化。这个初始化函数中会构建ROIPooling特征提取层。输入有两个:一个是conv3_3结点输出;另一个是检测到的物体坐标信息。输出为ROIPooling操作后的结果。变量feat_dim为生成的单个物体的特征维度,这里是576。
- 我们知道当前流行的物体检测网络通常会产生很多物体框的candidate,按国际惯例最后一般都要经过非极大值抑制(Non-Maximum Suppression)将多余的检测框去除。而该算法的一些参数就是在load_nms_params()函数基于配置文件config.pt中的值进行设置。
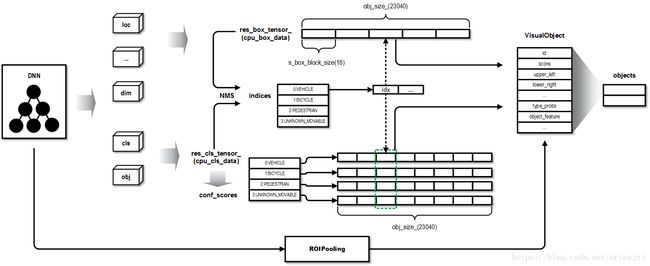
- 自从Faster R-CNN之后,流行的物体检测网络通常使用anchor box(如SSD, Yolo之类),即一些预定的框,作为检测物体的heuristic。这里的init_anchor()函数就是初始化anchor box信息。它从anchors.txt文件中读入相关信息。预定义的anchor box总共有16个,读入后写到anchor_这个Caffe数据块中。整个image分成60 x 24的格子,每个格式会根据16个anchor box给出相应的预测,则总共产生物体预测框的个数为obj_size_(60 x 24 x 16 = 23040)个。然后读入检测类型文件types.txt,信息记入types_变量。默认就检测车辆,自行车,行人,和未知固定障碍物。然后定义了几个Caffe数据块,如res_box_tensor_, res_cls_tensor_, overlapped_, idx_sm_。它们会在NMS中用到,而NMS也是用GPU加速的。res_box_tensor_用来存放物体检测位置信息。其中元素0-3为2d图像中bbox坐标。元素4为朝向。元素5-7为3d大小。元素8-11和12-15分别为3d bbox的前和后面的坐标。res_cls_tensor_用来存放检测类别。overlapped_用来存放top k检测框(按confidence排序)间是否重叠。idx_sm_为top k检测框的index。
到此,初始化过程基本结束,大体流程图如下:

接下来回到测试程序,下一步通过OpenCV的imread()函数读入图片,然后就调用YoloCameraDetector的Multitask()函数进行检测。它输出两个结构。变量lane_map为语义分割结果,为车道线信息。变量objects为VisualObject的vector,每个检测到的物体用一个VisualObject结构表示。接下来我们看看核心函数Multitask()。其中主要调用Detect()函数进行检测。这个函数进去后首先通过CNNCaffe的get_blob_by_name()函数将input blob取出,然后通过resize()函数将原始输入图片取ROI(下面的1920 x 768区域),再resize成神经网络input blob指定大小。resize()函数实现在cuda_util/util.cu文件中。
然后就是通过CNNCaffe的forward()函数做一把inference。这一步最为耗时,在笔者的穷人GPU上耗时~40ms。之后就是拿结果了。先拿检测物体信息。定义临时变量temp_objects为VisualObject的vector,然后通过get_objects_gpu()函数将网络inference的结果放到里面。这个函数稍稍有些复杂:
- 一些准备工作,如将相应的输出blob通过CNNCaffe的get_blob_by_name()函数取出来。然后判断网络是否输出了ori, dim, lof, lor等信息。其中的obj_batch,obj_height和 obj_width分别为1, 24, 60。
- 调用GetObjectsGPU()函数将网络各输出结点信息放到之前定义的用于存放结果的Caffe数据块res_box_tensor_和res_cls_tensor_中。该函数实现位于network.cu文件。主要实现在get_object_kernel()函数中。网络中物体检测部分沿用自Yolo,而Yolo的输出并不是物体框的顶点坐标,因此需要做一些转化。转化公式可参见论文《YOLO9000:
Better, Faster, Stronger》的Figure 3。其它的输出也按需做转化。 - 对于每一种物体类别,调用apply_nms_gpu()函数去除多余的检测框。该函数实现在region_output.cu文件。这个函数首先先用阀值过滤下,把confidence小于0.8的干掉,剩下的框的index和confidence放在idx和confidence两个vector中。然后把剩下的元素按confidence排个序。接着调用compute_overlapped_by_idx_gpu()函数计算这些框间的重叠关系。当两个框间的IoU(即Jaccard overlap)大于0.4时,算两者重叠。基于这个结果,就可以调用apply_nms()执行NMS算法。结果放在indeces这个成员中。indices是类别到物体框index数组的映射。
- 将上面处理后的输出填到要返回的变量temp_objects中。对于之前NMS算法中幸存下来的每个物体框,创建VisualObject对象。该结构中几个关键成员:type代表该物体类别,如是车辆还是行人等;type_probs是一个数组,代表该物体框为每种类别的confidence;score为type_probs中的最大值,它是objectnesss的confidence。像upper_left/lower_right/alpha/height/width/length等这一坨都是代表该物体在2d和3d中的位位置信息,来自之前填的cpu_box_data结构;object_feature为之前提到的ROIPooling后输出的特征,这个现在置空,一会会在Extract()函数中填。id为这一帧中物体框的编号。
到此为止,检测出来的物体信息都放在temp_objects这个VisualObject数组中。但是,筛选还木有结束,这些物体检测框还要经过最后一道考验,就是前面提到的2d和3d的最小高度检测。如果小于之前指定的阀值,那也被干掉。这一部后幸存下来的物体框放在objects变量中。
接下来调用Extract()函数提取这些物体框的特征。它对于extractors_变量中的每个特征提取器(也就是之前创建的ROIPoolingFeatureExtractor),调用其extract()函数。这个函数就是执行一下之前在ROIPoolingFeatureExtractor的init()函数中创建的ROIPooling层。因为是要提取检测物体的特征,所以该函数需要传入检测框信息objects。ROIPooling层输出的特征经过L2 normalization后存于对应VisualObject结构中的object_feature成员。
Extract()函数后调用yolo::recover_bbox()函数进行坐标的转换。因为之前VisualObject中upper_left/uppper_right中填的是相对于ROI(图片下面1920 x 768)中并且归一化到[0,1]范围内的。比如xmin/ymin/xmax/ymax为(0.552336, 0.27967, 0.583794, 0.344488)。这个坐标会转换到ROI中的像素坐标。转换后x/y/w/h为(1060, 526, 60, 49)。之后还会和图像的大小做一个并,把那些超出图像的部分切掉。最后如果框的边界是在图像的边上的,会设置VisualObject的trunc_width/trunc_height成员。
Detect()函数返回后,接下来处理用于车道线的语义分割结果。通过get_blob_by_name()函数得到seg_prob这个blob。然后把它里边的数据拷贝到类型为cv::Mat的mask变量中。这个变量也是Multitask()函数的输出变量。最后,返回到测试程序中,将语义分割结果以图片形式保存。
检测部分的流程大体如下图:

为了看起来更加直观,用官方自带的测试图片检测的结果数据可以图形化如下:
