创建DataFrame的几种方式
第一种方式:使用case class样本类
(1)定义表的schema
7698,BLAKE,MANAGER,7839,1981/5/1,2850,0,30
case class Emp(empno:Int,ename:String,job:String,mgr:Int,hiredate:String,sal:Int,comm:Int,deptno:Int)
(2)读入数据
var lines = sc.textFile("/usr/local/tmp_files/emp.csv").map(_.split(","))
(3)把每行数据映射到Emp中。把表结构和数据,关联。
val allEmp = lines.map(x => Emp(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))
(4)生成DataFrame
val df1 = allEmp.toDF
本质还是RDD
df1.show

第二种方式 使用Spark Session
(1)什么是Spark Session
在2.0以后引入的一种统一的访问方式,使用Spark Session可以访问Spark所有组件。
(2)使用 StructType 来创建schema
import org.apache.spark.sql.types._
val myschema = StructType(
List(
StructField("empno", DataTypes.IntegerType),
StructField("ename", DataTypes.StringType),
StructField("job", DataTypes.StringType),
StructField("mgr", DataTypes.IntegerType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm", DataTypes.IntegerType),
StructField("deptno", DataTypes.IntegerType)))
val myschema = StructType(List(StructField("empno", DataTypes.IntegerType), StructField("ename", DataTypes.StringType),StructField("job", DataTypes.StringType),StructField("mgr", DataTypes.IntegerType),StructField("hiredate", DataTypes.StringType),StructField("sal", DataTypes.IntegerType),StructField("comm", DataTypes.IntegerType),StructField("deptno", DataTypes.IntegerType)))
(3)读取文件
var lines = sc.textFile("/usr/local/tmp_files/emp.csv").map(_.split(","))
(4)数据与表结构匹配
import org.apache.spark.sql.Row
val allEmp = lines.map(x => Row(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))
(5)创建DataFrame
Spark session available as 'spark'.
val df2 = spark.createDataFrame(allEmp,myschema)
第三种方式 -直接读取一个带格式的文件:json(分两种方式读)
val df=spark.read.json("/opt/module/spark-2.1.0/examples/src/main/resources/people.json")
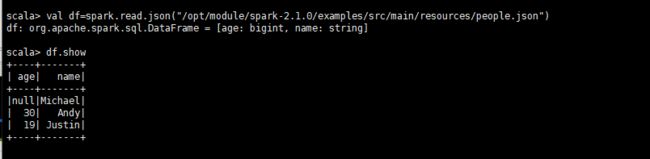
val df4=spark.read.format("json").load("/opt/module/spark-2.1.0/examples/src/main/resources/people.json")
