技术如何秒懂你?阿里百万级QPS资源调度系统揭秘
阿里妹导读:TPP(Taobao Personalization Platform, 也称阿里推荐平台 ) 平台承接了阿里集团300+重要个性化推荐场景,包括手淘首页猜你喜欢、首图个性化、购物链路等。除了提供应用层面的支持和封装,还肩负着机器分配和维护各场景运行稳定的重任。

理想情况下,TPP平台上的场景owner不需要关注底层的资源分配情况,平台尽可能的提高CPU利用率,同时保证平台上场景的稳定。QPS(每秒查询率)增加的时候扩容,QPS减少的时候缩容,未来这些在夜间被拿掉的机器可以用来混部离线任务等;另外,在2016年双11的时候,总的机器数目不足以维持所有的场景以最高性能运行,需要有经验的算法同学判断场景的优先级,从低优先级的场景上拿出来机器,补充到高优先级的场景中保证成交额。这些平台稳定性工作都是需要繁琐的人工调度,会有如下的缺点:
人力成本巨大:人肉无法监控和处理所有的场景;
反应时间较长:从发现场景出问题,找出可以匀出机器的不重要场景,到加到重要场景所需要的时间相对过长,而程序天然的有反应时间短的优势;
人力无法全局高效的调度资源, 而程序可以更敏感的发现场景的问题,更全面的搜索可以拿出来机器的场景,并可以准确计算拿出机器的数目,有更好的全局观。
基于如上的两点:日常的时候提高资源利用率,大促的时候解放人力,TPP智能调度系统就产生了。TPP智能调度系统以每个集群(一组机器,承载一个或多个场景)的CPU利用率,LOAD,降级QPS,当前场景QPS,压测所得的单机QPS为输入,综合判断每个集群是否需要增加或者减少机器,并计算每个场景需要增减机器的确切数目,输出到执行模块自动增减容器。 TPP智能调度系统有如下的贡献点:
日常运行期间,保证服务质量的情况下最大化资源利用率;
大促运行期间,能够更快速、更准确的完成集群之间的错峰资源调度;
支持定时活动事件的录入,如红包雨、手淘首页定时的Push,程序自动提前扩容,活动结束自动收回;
对重要场景提前预热,完成秒级扩容。
该系统由TPP工程团队和猜你喜欢算同学联合搭建而成,从2017年9月开始规划,到10月1日小批量场景上线,到10月13日三机房全量上线;经过一个月的磨合,参加了2017年双11当天从 00:15 %到 23:59的调度,峰值QPS达到百万级别。在日常运行中,集群平均CPU利用率提高3.37 倍, 从原来平均8%到27%;在大促期间,完成造势场景,导购场景和购后场景的错峰资源调度,重要服务资源利用率保持在 30% ,非重要服务资源利用率保持在50%, 99%的重要场景降级率低于2%。同时TPP智能调度系统的"时间录入"功能支持定时活动,如首页红包的提前录入,提前扩容,活动结束收回机器,改变了以前每天需要定时手动分机器的情况。
问题定义与挑战
TPP智能调度系统要解决的问题为: 如何在机器总数有限的前提下,根据每一个场景上核心服务指标KPI(异常QPS等)和场景所在集群物理层指标KPI(CPU,IO等),最优化每一个场景机器数目,从而使得总体资源利用率最高。
更加直白一点,就是回答如下的问题:
怎么判断一个集群需要扩容?扩多少的机器
简单的CPU超过一定的水位并不能解决问题。不同的场景的瓶颈并不完全一致,有IO密集型的(如大量访问igraph),有CPU密集型的,一个场景可能在cpu不超过30%的情况下,就已经出现了大量的异常QPS,Load很高,需要增加机器。
如何给不同的场景自适应的判断水位?
有的场景30% CPU运行的很好,但是有的场景10%可能就出问题了。
如何防止某些实现有问题的场景,不停的出现异常,不断触发扩容,从而掏空整个集群,而实现效率较高的场景反而得不到机器,引发不公平。
如何用一套算法同时解决日常运行和大促运行的需求
当总的机器数目有限的情况下,如何分配不同场景之间的机器,最大化收益(有效pv)。如何用程序实现从某些场景拿机器去补充重要场景的运行。
对于运行JVM的容器,当一个新加容器在到达100%服务能力之前需要充分预热,预热过程会有异常QPS的产生。算法一方面要尽可能少的减少扩缩容的次数,另外一个方面,要尽可能快的发现扩容的需求,实现较高的扩容recall。如何在这两者之间做tradeoff?
系统架构
TPP智能调度涉及TPP的各方各面,其架构图如下所示,包括数据输入、算法决策和决策执行三个方面,但是为了更灵敏的、更及时的发现超载的场景并进行扩容,需要自动降级、秒级扩容、单机压测qps预估功能的保证。另外还有一些功能性的开发,如业务算法配置参数分离、调度大盘监控、烽火台规则运行平台等的支持。最底层的更加离不开容器化的全量部署 ,使得加减机器,快速部署环境成为了可能。

算法介绍
智能调度的算法是在其他模块都具备的情况下,才能够稳定有效的运行。因此在介绍智能调度算法之前,先对算法依赖的每个部分进行简要的介绍如下。
算法依赖模块简要介绍
KMonitor数据接入
KMonitor是基于optsdb on druid架构的监控系统。支持从Hippo,amon和Log文件收集监控数据,并可以在grafana上展示或是通过api接口获取。 TPP调度系统对Kmonitor的使用包括两部分:通过tpp的log文件注册tpp服务的状态信息和调度系统从Kmonitor获取状态信息。 目前注册的状态信息包括容器内的cpu/load等系统状态和每个场景的pv/latency等业务信息. 通过使用kmonitor提供的多租户功能, tpp独立部署了一套租户系统, 可以支持信息汇报延迟不超过5s。调度系统获取这部分信息后作为计算的数据输入。
Fiber秒级扩容
2017年TPP全部集群运行在Fiber之上,Fiber是在Hippo机器调度系统的一种封装,其优势在于能够将容器的加载、预热、上线维持在秒级别,而之前直接从Hippo调度机器,加载方案到正常上线需要10分钟级别。Fiber本身可以配置buffer,每个一定时间将重要的P1场景加载到buffer中的机器上并定时预热,通过实践验证,在提前有buffer预热的情况下,从智能扩缩容发出扩容指令开始到机器完全挂上去,能够在10s内完成。
自动降级
自动降级是2017年TPP双11的另外一个创新,其主要的思想是判断当天集群总的超时QPS的比例,如果从全局上统计超过用户设置的阈值(如3秒钟区间统计值超过1%),则将出现超时的容器集体降级。 所谓降级是指方案的一个新的配置,高级别的运行配置保证更好的展示效果,但是单容器能够服务的QPS较少;低级别的运行配置会使得展示效果打折扣,但是单容器能够服务的QPS会更多。举个例子:首页猜你喜欢L0的配置是访问RTP,利用深度模型进行item的打分,L1则会关闭RTP访问的开关,从而节省CPU,服务更多的QPS,但是可能从业务上来看,展示的item的相关度会打折扣。
自动降级主要用在如下两个方面:1. 双11在0点峰值附近的时候,整个集群机器严重不足,可以通过集体配置降级,保证全部用户能够正常访问,即使服务质量稍有下滑,但是和超时相比,是可以忍受的; 2. 是和智能扩缩容相关的。智能扩缩容的出现,使得一天中集群的机器数目会发生更频繁的变化,而JVM容器本身存在预热的问题,当一个新的容器挂载到线上知道100%预热完成之前,就会出现严重的超时。有了自动降级之后,可以通过砍掉一部分二方服务的rt,使得即使预热的QPS也不会严重超时,从而消减了扩容瞬间对线上QPS的影响。当然不同的场景其预热过程要详细的优化,有CPU密集的、IO密集的、以及缓存型的,其预热过程得有所不同。
自动压测
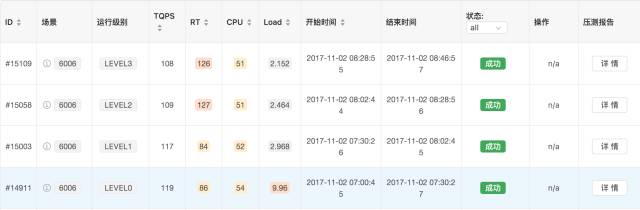
场景压测在每天夜里定时执行,获取场景的单机性能。对于具备降级配置的场景,会压测每一套降级配置的性能。针对每个场景,当场景owner将场景加入日常压测列表,自动压测程序将会于每晚凌晨0:00调用API,获得压测列表,创建待压测场景的影子场景,申请压测发生容器,调用压测接口逐渐增加qps,直至容器超出负载(系统load,cpu,业务异常率等)。目前CPU上限为100%,异常率的上限为5%。 该运行结果就可以作为TPP智能调度的输入,作为每个场景在某个特定的级别(L0、L1、L2或者L3)的单机服务能力。压测结果如下所示:
调度算法
在上述模块稳定保障下,智能调度算法形式化为资源调度优化问题:
利用每个集群当前的运行状态计算每个场景需要的机器数目 $N_i$, 需要加机器为正值,需要缩容为负值。

确定每个机器的扩缩容的数目,寻找最优解,优化目标为,即使得CPU尽可能的均衡并接近集群目标负载,如OptimalCPU=40%为集群最佳状态:

约束条件为:
所有的Ci+Ni总和小于集群总的机器数
有多个不同的场景,每个场景的优先级为P1到P3之一,每个场景都可能工作在L0到L3,所有工作在非L0的都可以被降级。
先满足高优先级场景,再满足低优先级场景。
所有P1场景的扩容需求必须要被满足。
智能调度算法核心要解的问题是:尽可能的通过给不同的场景加减机器,改变所有场景的CPU的值,将所有集群的CPU调节到目标CPU(人工设定优化目标)的周围, 并且尽可能的均衡。如两个场景,目标CPU为40%。将其调节为38%、42%,肯定要比10%、70%要好。这个均衡的程度是由优化目标来决定的。
在最开始算法考察的过程中,还考虑过别的一些算法,比如分层的背包方法,包的容量是“总的机器池子的quota”,每个集群是要放在书包里面的物品,放到里面会消耗一定的机器,消耗了背包的“空间”, 但是同时加了机器,CPU降低会带来一定的增益:优化目标变小。暴力搜索也是可以在有限时间解这个问题的。
但是我们最后还是采用了一种朴素的做法,尽可能的模拟人进行调度的方法,对需要机器的场景排个序,用不重要场景的机器拿出机器去补充重要P1场景。可以根据人为的经验去灵活调整扩缩容次序,因为在实际运行过程中,可解释性永远比最优化更重要,你给一个场景加了机器,减了机器,需要给人家解释清楚。而不是说,给某个集群拿掉10台机器是因为集群总的负载均衡度上升了0.01。
更加详细的介绍智能调度的算法如下。我们直接计算每一个集群CPU到达最优解需要的机器数Ni, 如果Ni>0,表示需要扩充机器降低CPU到目标CPU,如果Ni < 0, 表示可以拿掉机器提高场景CPU到目标CPU。有如下的几种情形:
1. 如果所有Ni的和 < 空闲机器, 即集群空闲的机器数目加上可以缩出来机器大于所有要机器的数目,那所有的需要扩容的都可以到达目标CPU,所有缩容的直接拿掉机器CPU升高到目标CPU,也就是优化目标达到最小值0。
2. 如果所有Ni的和 > 空闲机器, 即扩容需求不能得到完全满足。这时调度算法会选择满足限制条件,并且使得优化目标函数变化最小的梯度方向进行变动。 具体方法是:将所有的非P1场景通过降级或者提高目标CPU水位,使其需要的机器变少,甚至可以拿出机器。然后进行如下迭代:每次选择能够拿出机器最多的场景,将其机器加到需要机器最少、优先级最高的场景上,使其CPU达到目标CPU。然后将扩容被满足的场景从list中移除。重复如上步骤,直到所有能够拿出的机器被用完。“优化目标函数变化最小的梯度”是这样体现的:尽可能少的降级非P1或者提高非P1场景的水位,尽可能多的满足P1场景。
3. 第2步可能有两种结果,所有P1的扩容需求被满足,算法有解。否则算法无解,优化目标也没有指导意义了,只能尽可能的满足部分P1, 不能满足的P1只能被降级。这种无解的情况只有在大促次峰值附近出现过极少数时间。
上述算法的复杂度为O(m) , m 为被调度的集群的个数,量级为1000,因此每次都能很快得出近似最优解,计算开销很小。
除了上述的寻找最优值的算法,智能调度算法还有两个关键模块需要介绍:收敛逻辑和Ni的计算。
收敛逻辑
智能调度算法运行的控制逻辑是,设置迭代间隔,如每隔5秒进行一次迭代。每一轮迭代中,拿到场景实时的状态信息,场景“过载”了给扩容,场景“空载”了给缩容,不论是扩容还是缩容,在扩的过程中,要时刻监控关键指标是否到了目标区域,从而结束本轮迭代。这类控制逻辑,最重要的是要保证是收敛的,即不论怎么调整,最终会较快达到稳态; 同时,不论系统何时、何种程度偏离稳态,都是可以自己重新恢复到稳态。
线上实验表明,目前最可靠的收敛方式是为集群设置稳态区间。如设置的区间为[20%,40%], 如果cpu超出稳态区间,大于40%,则加机器,等到下一轮迭代,判断cpu是否在稳定区间,如果是则停止调节;如果加机器加过头了,cpu跌出了20%, 则减机器,让cpu回升,经过多轮迭代,最终达到稳态。理论上,稳态区间设置越大,收敛的速度会越快,基本不会出现扩容扩过头的情况,在比较好的计算所需机器的算法支持下,一次就可以收敛。但是过宽的稳态区间会使得资源利用率较低,有可能集群是在下线水位运行。
另一个极端就是稳态区间设置成为一个值,指哪打哪,比如目标cpu设置成为30%,如果CPU大于30%,就会扩容,如果CPU小于30%,缩容。这样的好处是,集群CPU肯定在30%附近波动,平均下来,集群CPU达到目标值30%,但是这样的缺点就是频繁的增减机器,增加机器并不是没有开销,运行JVM的容器存在预热问题,冷机器上线会增加异常QPS的比例,是得不偿失的。经过实际运行,我们选定optimalCPUDrift=2, 也就是在目标CPU的+2和-2的区间都是稳态,既能使得集群CPU达到目标值,同时又能避免频繁扩缩容。
Ni计算公式
Ni表示一个场景机器数目的变动,Ni>0表示需要机器,Ni<0表示可以被缩容。Ni有两种计算方式:

第一种计算方法是根据单机压测的QPS来计算,非常直观,因为单机QPS是通过线下不停的增加流量,一直到该单机CPU到达100%或者异常QPS超过5%,但在真实使用的过程中发现,线下的压测数据通常和线上真实能够服务的qps不太一样,主要原因有两个:一个是线上有可能是多个场景公用一个物理机,互相影响;另外一个是线下压测只能是天级别的数据,但是有可能当一个场景发生了方案更改,其服务能力也会发生变化,而压测数据还是历史值。
第二种计算方法采用的是当前实时的结果,较为准确。唯一的缺点的是会受到噪音CPU的影响,如刚扩上去的机器,由于预热的原因,CPU会瞬间飙高,等完全预热了之后CPU才会降下来,这种问题的解决方法刚加上去的机器在预热期间不输出CPU的数据,免得影响Ni的计算。
扩容的触发条件
有了计算Ni的方法了之后,下一步需要关注的就是何时触发扩容,然后计算Ni。 目前智能调度算法的触发条件有两个:
1、当目前1分钟的平均CPU不在稳态区间中。 此时:
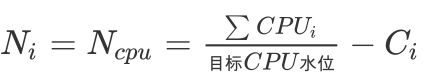
2. 当一个场景降级的QPS比例大于一定阈值,目前线上取5%。由于降级触发的扩容,其:
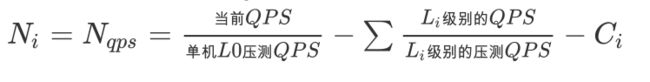
最终的:

其他功能
负载均衡: 保证一个场景中多个容器之间的负载均衡,使得调度算法能够工作在场景粒度,而不是容器粒度,减少需要调度的规模。
监控大盘:监控网页、方面及时掌握智能调度的进展
规则运行保障:通过crontab功能定时调度智能扩缩容的运行。
扩容原因透出:每次扩容都有相应的原因,供场景owner查看。
红包雨:对于QPS增长特别快,几乎直线拉升的增长受限于扩容的速度。如果预先能够知道活动发生的时间区间,可以通过提前录入预估QPS,智能调度算法提前给其扩容。
除了大盘,还进行了机器的热点和调度可视化,能够在双11当天更方面的监控集群的运行状态。下图中一个格子表示一个集群,颜色表示CPU水位,大小表示拥有机器数目。当有场景被扩容或者缩容时也会可视化出来。

线上性能实验
日常模式
下图取了10月1日(智能调度上线前)和11月6日(智能调度上线后)24小时内首页猜你喜欢的机器数、CPU利用情况对比(其中机器数和QPS做了归一化处理):
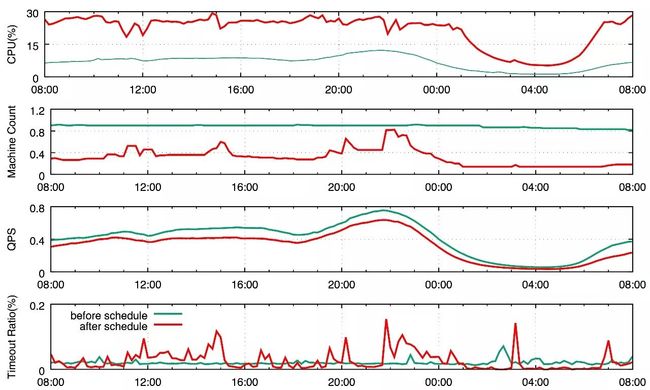
从上图中可以看出,在运行了智能调度(红色线)之后,CPU利用率从原来持续低于15%,平均CPU利用率8%提高到平均27%。值得指出的是,为了保护场景,智能调度设置了最小机器数的保证,数目为max {3台机器,过去24小时机器平均值},所以在凌晨1点到凌晨7点,即使QPS变为个位数, 场景机器没有被完全拿空。如果有离线在线混部的需求,可以把凌晨的机器保护去掉,让这些机器回归机器池子,部署机器学习训练模型。
同时我们可以看出来,运行了智能调度之后,日常的机器数是原来固定分配机器的1/3,极大的节省了机器资源。
智能调度和固定机器相比,缺点就是会在一天中,比较频繁的发生机器数目的变动,但是通过图(d)的统计,可以看出超时qps能够持续小于千分之2,处在可以接受的范围内。
大促模式
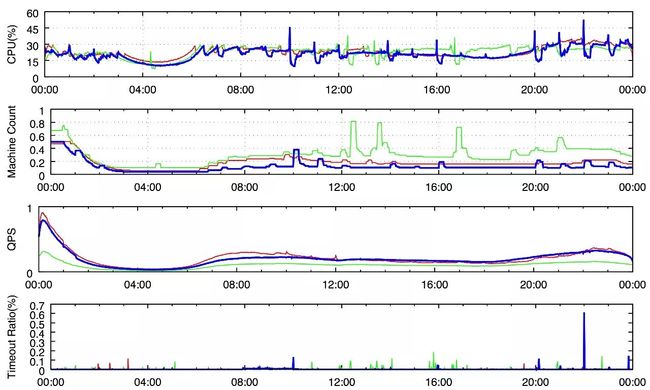
在上图中,我们选择了四个场景,记录了它们在双11当天24小时的CPU、集群机器数、QPS(对数刻度)、超时QPS比例的变化图。从上面第二个子图可以看出来四个场景明显的错峰资源调度,蓝色线在10点需要机器,但是后面机器贡献出来提供给绿色的场景来使用。此外,从第二张子图可以看出来,在双11当天有明显的脉冲流量,自动扩缩容保证了这些脉冲流量,同时保证了超时qps低于千分之6(如子图4)。值得指出的是,2017年为自动扩缩容运行的第一年,为了保证11日当天的成交额,没有将CPU水位调到很高,后来微调了集群的CPU水位,在所有P1水位在35%时,还能保证所有P1场景降级率均低于2%。
总结
智能调度系统作为集团双11推荐场景的重要基础设施保障,在2个月的时间中工程、测试团队联合算法同学完成了从架构设计、算法调试、功能上线测试到双11当天百万级的QPS的资源调度。从双11凌晨00:15分接手机器调度开始,智能调度系统在24小时中做到了对上层应用开发同学的透明化,保证他们能够投入最大精力冲成交,完全不用担忧资源不够的问题。
智能调度系统全程无需人工干预和拆借机器,完成造势场景,导购场景和购后场景的错峰资源调度,P1场景资源利用率保持在 30% ,非P1资源利用率保持在50%, 所有P1场景降级率低于2%。即使大促当天各种突发和变动的流量,超时率仍能够控制在千分之六以内,实现了让工程和算法同学"零点高峰瞪大眼睛认真看,双11当天买买买" 的愿望。
未来改进
现在智能扩缩容在定时脉冲QPS增加(如双11当天0点的QPS,定时的红包雨),以及日常的QPS连续光滑变化的情况下有解 (定时脉冲QPS通过场景owner提前录入活动预估QPS和持续时间,算法提前扩容),但是在不定时的脉冲QPS增加的情况下不能很好的解决,主要受限于机器的加载速度和预热速度,当瞬间需要大量机器时候,提前预热在buffer池子中的机器会被掏空,相当于发生cache miss,得从hippo拿hippo机器,扩容速度跟不上。如何能够在有限buffer池子的情况下,尽可能的减少cache miss是未来的一个优化点。
智能扩缩容在扩较多机器的瞬间,虽然通过自动降级的解决方案,能够消除超时QPS,但是会有一定程度的降级QPS,如何能够将智能扩缩容和RR层的流量调度结合起来,更稳妥的进行预热,保证更加平滑的扩容,同时保证预热速度是未来的一个优化的方向。
写在最后
感谢桂南、天民、野蔓、永叔对项目的大力支持;
感谢TPP各场景的算法同学在智能调度运行过程中提出的宝贵的改进和指导意见;
感谢项目所有参与人员: 剑豪,玉景,巫宸,麒翔,七炎,千鹍,唯勤,林谦,剑持,成都,振之,曲竹,聿剑,画帆,荐轩
这是一个有心人才能看到的福利预告
恭喜所有看到最后的小伙伴,你真是太棒了!
明天,阿里妹有一份神秘的圣诞礼物,要提前送给所有热爱技术的小伙伴。
究竟是什么?嘿嘿,先让我卖个关子。
明天早上,记得叫上你的好战友,一起来收礼物哦~
![]()
你可能还喜欢
点击下方图片即可阅读

《阿里巴巴Java开发手册》实体书开启预售!

你写的代码,是别人的噩梦吗?

如何解决大规模机器学习的三大痛点?

关注「阿里技术」
把握前沿技术脉搏