Apache Hive进阶实战
Udf 单行函数:一行输入一行输出
Udaf 多行函数:多行输入一行输出
Udtf 用户表函数:一行输入多行输出,主要用在侧视图
Hive视图概述:
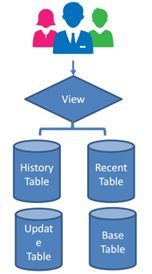
视图是一个元数据,只能在MySQL DataStore中找到
视图是一种逻辑结构,通过在虚拟表中隐藏子查询、连接和函数来简化查询,数据查询的快捷方式,把复杂的查询放在view里
Hive视图不存储数据或获得物化
一旦创建了视图,它的模式就会立即冻结,元数据就会被存起来,查询才能显示出来
如果删除或更改了基础表,则查询视图将失败
视图是只读的,不能用作加载/插入/修改的目标,只能进行查询
Hive视图常用操作:
建立视图:CREATE VIEW view_name AS SELECT statement;
建立视图支持:CTE,ORDER BY,LIMIT,JOIN等等
查找视图用:SHOW TABLES; (hive v2.2.0之后才支持SHOW VIEWS)
显示View定义用:SHOW CREATE TABLE view_name;
删除视图:DROP view_name;
更改视图属性:ALTER VIEW view_name SET TBLPROPERTIES ('comment' = 'This is a view');
更改视图定义:ALTER VIEW view_name AS SELECT statement;
显示表的格式属性:SHOW TABLE FORMATE;
使用show views查看是否支持该命令,不支持的话就使用SHOW CREATE TABLE ,desc formatted tablename; 可以查看表的格式和详细信息,这里可以得到Table Type ,也可以得到表的location。 根据Table Type值可以知道表是内部表还是外部表。是表还是视图。
Hive侧视图:
应用表生成函数,将函数的输入和输出连接在一起
即使输出为空,LATERAL VIEW OUTER也会生成结果
支持多个水平
SELECT * FROM table_name
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(myCol1) myTable2 AS myCol2;
通常用于规范化行或JSON解析器
select * from work lateral view outer explode(split(null, ',')) a as loc;
explode会把这个数组拆成多个行
使用outer关键字可以把null也输出出来
Complier 编译器 compile(编译)
Optimizer 优化器
Executor 执行器
Hive SELECT(数据映射):
SELECT语句用于项目符合WHERE/JOIN指定的查询条件的行
Hive SELECT语句是数据库标准SQL的子集
SELECT 1; //直接返回这个常量,可以测试自定义函数
SELECT [DISTINCT] column_nam_list FROM table_name;
//仅从 "table_name" 表的 "column_name, column_name" 列中选取唯一不同的值,也就是去掉 "column_name, column_name" 列中的重复值。
//在表中,一个列可能会包含多个重复值,但有时希望仅仅列出不同(distinct)的值。
SELECT * FROM table_name;
SELECT * FROM employee LIMIT 5;
//限制返回的行数
CTE:WITH t1 AS (SELECT …) SELECT * FROM t1
CTE就是CTAS加上WITH,子查询嵌套使用Common Table Expression,把查询写的更清楚
CREATE TABLE cte_employee AS WITH
r1 AS (SELECT name FROM r2 WHERE name = 'Michael'),
r2 AS (SELECT name FROM employee WHERE sex_age.sex= 'Male'),
r3 AS (SELECT name FROM employee WHERE sex_age.sex= 'Female')
SELECT * FROM r1 UNION ALL SELECT * FROM r3;
嵌套查询:SELECT * FROM (SELECT * FROM employee) a;(后面一定要加别名,否则会报错)
Hive SELECT in Advance(进阶语句)
正则表达式列规范
SET hive.support.quoted.identifiers = none;(设置好就能使用了)
SELECT `^o.*` FROM offers;
虚拟列(两个连续下划线,对数据验证有用)
INPUT__FILE__NAME,这是映射器任务的输入文件的名称(文件地址)
BLOCK__OFFSET__INSIDE__FILE,它是当前的全局文件(块大小)
Hive中JOIN概述:
JOIN语句用于将两个或多个表中的行组合在一起,join要有关联条件
Hive JOIN语句类似于数据库连接,Hive不支持不平等连接,join的表的column要相等
INNER JOIN,OUTER JOIN(RIGHT JOIN,LEFT JOIN, FULL OUTER JOIN)其中的OUTER可以省略掉,CROSS JOIN(完全连接,在两个表没有相同元素时使用,或者使用:笛卡儿积/JOIN ON 1=1),隐藏JOIN(INNER JOIN不使用JOIN关键字但是使用where和逗号,来分割表),但是如果两个表都有100行,同时查询就会一口气查10000行数据。
JOIN用在WHERE子句之前
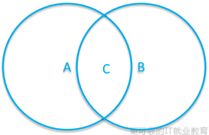
Area C = Circle1 JOIN Circle2
Area A = Circle1 LEFT OUTER JOIN Circle2
Area B = Circle1 RIGHT OUTER JOIN Circle2
AUBUC = Circle1 FULL OUTER JOIN Circle2
求A和B异差集的方法
求A和B右连接A为null的部分,UNION上A和B左连接B为null的部分
Inner JOIN, select * from a join b on a.k = b.k
Implicit JOIN, select * from a, b where a.k = b.k
Outer JOIN, select * from a left join b where a.k = b.k
Cross JOIN, select * from a join b where 1 = 1
Inequality JOIN (2.2.0之后的版本支持) 【异差集】
Hive中MAPJOIN:
必须是一个大表JOIN一个小表,把小表的数据进行一个复制,把小表复制多份放到大表所在的节点上,把小表数据在大表上过滤一遍
MAPJOIN语句意味着只通过map执行连接,而不执行reduce作业
MAPJOIN语句将所有数据从小表读入内存并广播到所有映射
一旦设置hive.auto.convert.join = true,Hive自动转换JOIN成为MAPJOIN如果可能的话,在运行时检查MAPJOIN hint,这是默认的
SELECT /*+ MAPJOIN(employee) */ emp.name, emph.sin_number
FROM employee emp JOIN employee_hr emph ON emp.name = emph.name;
MAPJOIN操作符不支持以下操作:
在UNION ALL, LATERAL VIEW, GROUP BY/JOIN/SORT BY/CLUSTER BY/DISTRIBUTE BY后面使用MAPJOIN
不能在UNION, JOIN和其他MAPJOIN后面使用MAPJOIN
Hive集合操作Union:
UNION ALL,合并后保留副本
UNION,删除重复,自v1.2.0以来的支持
可以在顶层查询中使用
所有子集数据必须具有相同的名称和类型。否则,将执行隐式转换,并且可能存在运行时异常。
ORDER BY、SORT BY、CLUSTER BY、distribution BY或LIMIT用于union后的整个结果
select key from (select key from src1 order by key limit 10) sub union all
select key from src2 order by key limit 10
如果在union之前排序要用子查询的形式加上()进行order by
Hive中集合的其他操作:
其他set操作符可以使用JOIN/OUTER JOIN来实现
MINUS(集合和集合之间求子集):
SELECT a.name
FROM employee a
LEFT JOIN employee_hr b
ON a.name = b.name
WHERE b.name IS NULL;
INTERCEPT(集合和集合之间求交集):
SELECT a.name
FROM employee a
JOIN employee_hr b
ON a.name = b.name;
Hive中使用LOAD进行移动数据:
要在Hive中移动数据,它使用LOAD关键字。当不适用LOCAL字段时,移动到这里意味着原始数据被移动到目标表/分区,并且不再存在于原始位置。
不太推荐使用,不是标准的hive语句,load不能重复运行,只是进行文件转移,并没有进行块操作
load data local inpath '/tmp/hivedemo/data/employee2.txt' overwrite into table employee_external;
load data inpath '/tmp/hivedemo/data/employee2.txt' overwrite into table employee_external;
LOCAL指定文件位于主机中,当使用LOCAL时而且本地文件不会被删除
不当不适用LOCAL在HDFS中进行操作时,本质就是把路径改变,并不是把文件的储存位置改变
OVERWRITE覆盖用于决定是否追加或替换现有数据,加就是清空,不加就是不清空
Hive中表插入要点:
要将数据插入表/分区,Hive使用insert语句
INSERT比DBMS中的INSERT弱
INSERT支持OVERWRITE和INTO语法(但是使用OVERWRITE不能指定具体列了)
Hive支持从同一个表中插入多个数据
TABLE关键字在INSERT INTO中是可选的,但是建议写出来
INSERT INTO、可以像INSERT INTO T (z, x, c1)插入到T (z, x, c1)
INSERT INTO table_name VALUES,支持插入值列表
所有数据插入必须具有相同数量的指定列,或在未指定时具有相同数量的所有列
示例:

Hive中文件插入要点
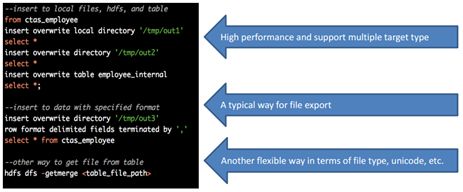
要将数据插入/导出文件,Hive还使用insert语句
文件插入只支持OVERWRITE
Hive支持从同一个数据源/表进行多次插入
LOCAL关键字支持写入本地文件系统。
默认情况下,写入的数据为文本,列之间以^A和行换行隔开。如果任何列不是基元类型,则将这些列序列化为JSON。
支持行格式导出文件到不同的格式CSV,JSON等。
示例:
Hive中的数据交换[EX|IM]PORT
IMPORT和EXPORT语句用于数据迁移(是Hive和Hadoop之间的导入和导出)
所有数据和元数据在没有数据库的情况下导出/导入
EXPORT语句在名为_metadata的文件中导出名为data和metadata的子目录中的数据
EXPORT TABLE employee TO '/tmp/output3';
EXPORT TABLE employee_partitioned partition (year=2014, month=11) TO '/tmp/output5';
EXPORT之后,我们可以手动将导出的文件复制到其他HDFS。然后,使用import语句导入它们
IMPORT TABLE empolyee_imported FROM '/tmp/output3';
IMPORT TABLE employee_partitioned_imported FROM '/tmp/output5’;
Hive分类数据ORDER BY:
ORDER BY (ASC|DESC)类似于标准SQL
ORDER BY仅使用一个reducer执行全局数据排序。
虽然ORDER BY很慢,我们应该尽早放置过滤器
ORDER BY支持使用CASE WHEN或表达式
ORDER BY支持设置这个位置参数:
set hive.groupby.ordervy.position.alias = true;
排序时使用select * from b order by case when num is null then 101 else num end;或者select * from b order by nvl(num,101);来把数据库里null排到最后
Hive排序数据—SORT BY:
SORT BY(ASC|DESC)决定如何排序每个reducer中的数据,是每一个reduce内部的排序
当reducer的数量设置为1时,它等于ORDER BY
SORT BY通常不单独使用
by列后面的字段必须出现在SELECT列的列表中(*字标签是可以的)
有1个以上的reducer时,数据排序不正确,因为每一个reduce都进行SORT BY合起来可能就不正确了
例如:SET mapred.reduce.tasks = 2;【这个在select中可以用,但是insert中就不能用了】
Hive排序数据—DISTRIBUTE BY:
DISTRIBUTE BY类似于标准SQL中的GROUP BY语句
它确保具有匹配列值的行将被分区到相同的简化程序中
它不对每个reduce的输出进行排序
它通常使用在SORT BY语句之前(partition => reducer)
by列必须出现在SELECT列列表中(*字标签是可以的)
示例:(绩效评估 典型应用)
SELECT department_id , name, employee_id, evaluation_score
FROM employee_hr DISTRIBUTE BY department_id SORT BY evaluation_score DESC;
因为使用DISTRIBUTE BY + SORT BY会快一些
DISTRIBUTE BY决定了数据按什么划分,SORT BY在同一个地方进行局部排序,因为在这个例子里不同部门进行排序是没有意义的
Hive排序数据—CLUSTER BY:
CLUSTER BY = DISTRIBUTE BY + SORT BY在同一列
CLUSTER BY不支持ASC | DESC
by列必须出现在SELECT列列表中(*字标签是可以的)
为了充分利用所有的reducer方法进行全局排序,我们可以先使用CLUSTER BY,然后再使用ORDER BY。
示例:
SELECT name, employee_id FROM employee_hr CLUSTER BY name;
SELECT后应用所有排序语句。
如果在select中使用别名,应该在order之后使用别名

最常用的是order by,应用范围比较广,它是全局排序,只用到一个reduce,但是有的时候需求是不需要统一进行排序的,比如比赛的排名只要求单项比赛的排名就可以;因为剩下两个都需要对数据非常了解,如果要用其他的记得先用DISTRIBUTE BY,查看数据之后再使用ORDER BY
而CLUSTER BY理论上讲速度可以比ORDER BY快,但是ORDER BY适用场合比较多
Hive分组GROUP BY
Hive的基本内置聚合函数通常和GROUP BY子句一起使用
如果没有指定GROUP BY子句,默认情况下,它将聚合整个表。
除了聚合函数外,所选的所有其他列也必须包含在GROUP BY中
select afferId, max(offervalue) from offers group by category;
offerId也必须放到group by里面
GROUP BY支持使用CASE WHEN或表达
GROUP BY 支持位置number:hive.groupby.orderby.position.alias = true
Hive的聚合条件HAVING:
自从Hive 0.7.0,所以添加了have来支持GROUP BY的聚合结果的条件过滤
通过使用HAVING,我们可以避免在GROUP By之后使用子查询
HAVING之后,我们也可以使用表达式,但不建议这样使用
并且HAVING可以替代WHERE但是也不建议这么做,因为这不是一种高效的写法
HAVING更擅长在使用function的时候使用,也就是聚合条件的时候,但是普通条件用WHERE就可以,而且WHERE不能用在聚合函数上
Hive基本聚合:
我们经常使用内置的聚合函数来进行数据聚合
聚合总是与GROUP BY一起使用
聚合函数可以应用于列或表达式
没有GROUP BY,聚合GROUP BY所有列
GROUP BY之后的列必须在SELECT列列表中(因为select选出的数据可能会有重复如果不加Group就不能正常计算出)
在NULL上的聚合为0,选择count(NULL) = 0
没有两个聚合可以具有不同的列
SELECT count(DISTINCT col1), count(DISTINCT col2) FROM test GROUP BY col3;(不允许)
SELECT count(DISTINCT col1), sum(DISTINCT col1) FROM test GROUP BY col3; (允许)
注意一些函数
Max,min,count,sum,avg
max(distinct col),avg(distinct col)等等
collect_set,collect_list(返回每个组列中的对象集/列表)
Hive高级聚合—GROUPING SETS:
GROUP BY中的groups SETS子句允许我们指定多余一个的记录集中的GROUP BY选项 = GROUP BY UNION GROUP BY…
| 使用GROUPING SETS分组集聚合查询 |
具有GROUP BY的等效聚合查询 |
| SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS ((a, b), a, b, ( )) |
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b UNION SELECT a, null, SUM( c ) FROM tab1 GROUP BY a, null UNION SELECT null, b, SUM( c ) FROM tab1 GROUP BY null, b UNION SELECT null, null, SUM( c ) FROM tab1 |
| SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b), a) |
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b UNION SELECT a, null, SUM( c ) FROM tab1 GROUP BY a |
| SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b) ) |
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b |
| SELECT a,b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS (a,b) |
SELECT a, null, SUM( c ) FROM tab1 GROUP BY a UNION SELECT null, b, SUM( c ) FROM tab1 GROUP BY b |
Hive高级聚合—CUBE|ROLLUP
一般的语法是GROUP BY WITH CUBE/ROLLUP
CUBE创造了多维数据集在其参数中创建列集的所有可能组合的求部分和。一旦我们在一组维度上计算了一个CUBE,我们就可以得到这些维度上所有可能的聚合问题的答案,所有组合都表达出来
ROLLUP子句用于在维度的层次结构级别上计算聚合
| 使用ROLLUP/CUBE聚合查询 |
具有GROUP BY的等效聚合查询 |
| SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b, c WITH CUBE |
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( )) |
| SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b, c WITH ROLLUP |
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( )) |
Hive窗口功能概述:
SYNTAX (语法解析)
排序:ROW_NUMBER,RANK,DENSE_RANK,NLITE,ERCENT_RANK
聚合:COUNT,SUM, AVG,MAX,MIN
分析:CUME_DIST,LEAD,LAG,FIRST_VALUE,LAST_VALUE
WINDOW clause(窗口的定义)
Case Study(案例分析)
Hive窗口功能语法:
自Hive 0.11.0添加之后,Hive window函数是一组特殊的函数,它扫描多个输入行来计算每个输出值。
解析函数功能强大,不受GROUP BY的限制
语法解析
Function (arg1,..., arg n) OVER ([PARTITION BY <...>] [ORDER BY <....>] [
PARTITION BY类似于GROUP。如果没有分区,就全部分区
如果没有ORDER BY,则无法定义window_clause
windows_clause不常用, 但功能很强
过滤其结果必须在外面一层
可同时用多个函数
窗口排序功能—排序类:
ROW_NUMBER:一个惟一的编号在结果集中每一行基于PARTITION内的ORDER BY子句(1234)
RANK:相等的行用相同的数字排序 (11144)
DENSE_RANK:在普通的RANK函数中,我们可以看到行数之间的差距。DENSE_RANK是一个没有间隙的函数。(11122)
NLITE:它将有序数据集划分为桶数,并为每一行分配适当的桶数。它可以用于将行分割成相等的集合,并为每一行分配一个数字。
PERCENT_RANK:(目前排名- 1)/(总行数- 1)。因此,它返回一个值相对于一组值的百分比等级(%)。
示例:
SELECT name, dept_num, salary,
ROW_NUMBER() OVER () AS row_num,
//写出这是第几列
RANK() OVER (PARTITION BY dept_num ORDER BY salary) AS rank,
//按照工资大小排列返回具体第几
DENSE_RANK() OVER (PARTITION BY dept_num ORDER BY salary) AS dense_rank,
//和单独的rank有区别,没有相同排名之后造成的差
PERCENT_RANK() OVER(PARTITION BY dept_num ORDER BY salary) AS percent_rank,
//相对排序(目前排名- 1)/(总行数- 1)显示的是百分比
NTILE(2) OVER(PARTITION BY dept_num ORDER BY salary) AS ntile
//分成两个桶,按照部门分区,salary进行排序
FROM employee_contract
ORDER BY dept_num, salary;

窗口聚合函数—聚合类:
COUNT:计数,可以和DISTINCT一起用,从v2.1.0开始没有ORDER BY和window_cause。完全支持v2.2.0。
SELECT COUNT(DISTINCT a)
OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM T
SUM:聚合,
AVG : 均值
MAX/MIN:最大/小值
从Hive 2.1.0开始在OVER子句支持中聚合函数
SELECT rank() OVER (ORDER BY sum(b)) FROM T GROUP BY a;
示例:
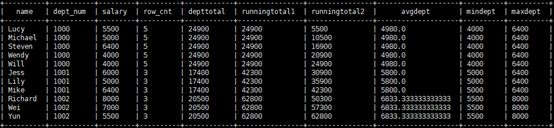
SELECT name, dept_num, salary,
COUNT(*) OVER (PARTITION BY dept_num) AS row_cnt,
//不支持GROUP BY
//COUNT(DISTINCT *) OVER (PARTITION BY dept_num) AS row_cnt_dis,
SUM(salary) OVER(PARTITION BY dept_num ORDER BY dept_num) AS deptTotal,
//各个部门的工资和
SUM(salary) OVER(ORDER BY dept_num) AS runningTotal1,
//进行但是在部门层次上进行工资相加
SUM(salary) OVER(ORDER BY dept_num, name rows unbounded preceding) AS runningTotal2,
// 用name作为一个边界成为一个窗口函数
AVG(salary) OVER(PARTITION BY dept_num) AS avgDept,
//部门间的均值
MIN(salary) OVER(PARTITION BY dept_num) AS minDept,
//部门间的最小值
MAX(salary) OVER(PARTITION BY dept_num) AS maxDept
//部门间的最大值
FROM employee_contract
ORDER BY dept_num, name;
//其实总体的这个ORDER BY并不起什么作用,主要还是窗口函数里面的ORDER BY起作用
窗口分析函数—分析类:
CUME_DIST:(行数<=当前行)/(总行数)
LEAD/LAG:lead/lag(value_expr [,offset[,default]]),用于返回下一行/上一行数据。可以选择指定行数(value_expr)。如果未指定行数(偏移量),则默认为一行。如果未指定默认值,则返回[,default]或null。
FIRST_VALUE:它从有序集返回第一个结果。
LAST_VALUE:它返回有序集的最后一个结果。
示例:
SELECT name, dept_num, salary,
LEAD(salary, 2) OVER(PARTITION BY dept_num ORDER BY salary) AS lead,
//把salary的行数向前移动两行,以部门分组,就是把每组的数据各自向前移动两行
LAG(salary, 2, 0) OVER(PARTITION BY dept_num ORDER BY salary) AS lag,
//把salary的行数向后移动两行,以部门分组,就是把每组的数据各自向前移动两行
FIRST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary) AS first_value,
//工资的第一个值
LAST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary) AS last_value_default,
LAST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_value
//工资的最后第一个值,但是默认的求最后一个值是有问题的所以要采用RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING才能正常使用LAST
FROM employee_contract
ORDER BY dept_num, salary;

对于LAST_VALUE,使用默认的窗口子句,结果可能有点出乎意料。这是因为默认窗口子句的范围是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,在本例中这意味着当前行始终是最后一个值。将窗口子句更改为RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING给出了我们可能期望的结果
窗口定义详解:
子句[
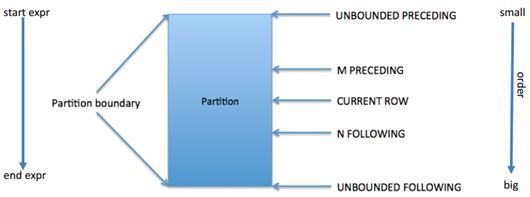
有两种类型的窗口:行类型窗口和范围类型窗口。
RANK,NTILE,DENSE_RANK,CUME_DIST,PERCENT_RANK,LEAD,LAG和ROW_NUMBER函数还不支持与window clause一起使用(window clause有一定的局限性)
行类窗口:
对于行类型窗口,定义是根据当前行之前或之后的行号。row window clause的一般语法如下:
ROWS BETWEEN
UNBOUNDED PRECEDING:窗口从分区的第一行开始
CURRENT ROW:当前行数
N PRECEDING or FOLLOWING:在当前行之前或之后的N行
UNBOUNDED FOLLOWING:窗口在分区的最后一行结束
CURRENT ROW:当前行数
N PRECEDING or FOLLOWING:在当前行之前或之后的N行
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING代表所有的行
排序时如果ORDER BY 列不充分区分序列, ROW顺序可能随机(尽量用上主键列) , 会影响结果
行类窗口图解:
示例:
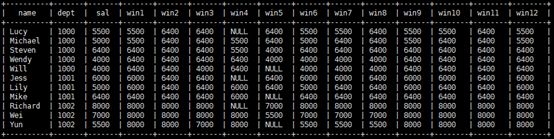
SELECT name, dept_num AS dept, salary AS sal,
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) win1,
//当前行和当前行前两行的最大值,都用各个部门分组
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 2 PRECEDING AND UNBOUNDED FOLLOWING) win2,
//当前行前两行和最后一行的最大值,都用各个部门分组
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING) win3,
//当前行前一行和当前行后两行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 2 PRECEDING AND 1 PRECEDING) win4,
//当前行前两行和当前行前一行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 1 FOLLOWING AND 2 FOLLOWING) win5,
//当前行后一行和当前行后两行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN CURRENT ROW AND CURRENT ROW) win6,
//当前行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) win7,
//当前行和当前行后一行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) win8,
//当前行和最后一行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) win9,
//第一行和当前行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) win10,
//第一行和当前行后一行的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) win11,
//第一行和最后一的最大值
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name ROWS 2 PRECEDING) win12
//当前行前两行和当前行的最大值
FROM employee_contract
ORDER BY dept, name;
范围类窗口:
与行类型窗口(以行为单位)相比,范围类型窗口(以分区中当前行之前或之后的值/距离为单位)必须是数字或日期类型。目前,范围类型窗口只支持一个ORDER BY列。
SUM(close) RANGE BETWEEN 500 PRECEDING AND 1000 FOLLOWING
根据与当前行值的距离选择行。假设当前值为3000,这个框架将包括分区中工资范围在2500到4000之间的行。
示例:
SELECT name, dept_num AS dept, salary AS sal,
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) win1,
//当前行前两行和当前行的最大值
salary - 1000 as sal_r_start,
salary as sal_r_end,
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name
RANGE BETWEEN 1000 PRECEDING AND CURRENT ROW) win13
//当前行减1000和当前行的最大值
FROM employee_contract
ORDER BY dept, name;