Linux系统移植
在众多嵌入式操作系统中,Linux目前发展最快、应用最为广泛。性能优良、源码开放的Linux具有体积小、内核可裁减、网络功能完善、可移植性强等诸多优点,非常适合作为嵌入式操作系统。一个最基本的Linux操作系统应该包括:引导程序、内核与根文件系统三部分。
因此,需要移植一个Linux系统的话,那么需要以下4个步骤:
- 搭建交叉开发环境
- bootloader的选择和移植
- kernel的配置、编译、和移植
- 根文件系统的制作
搭建交叉开发环境
交叉开发环境
在嵌入式开发中,交叉开发是很重要的一个概念,开发的第一个环节就是搭建环境,这里所说的交叉开发环境主要指的是:在开发主机上(通常是对应的pc机)开发出能够在目标机(通常是对应的开发板)上运行的程序。嵌入式比较特殊的是不能在目标机上开发程序(狭义上来说),因为对于一个原始的开发板,在没有任何程序的情况下它根本都跑不起来,为了让它能够跑起来,我们还必须要借助pc机进行烧录程序等相关工作,开发板才能跑起来,这里的pc机就是我们说的开发主机,想想如果没有开发主机,我们的目标机基本上就是无法开发。
需要交叉开发环境的原因:
- 嵌入式系统的硬件资源有很多限制,比如cpu主频相对较低,内存容量较小等,想想让几百MHZ主频的MCU去编译一个Linux kernel会让我们等的不耐烦,相对来说,pc机的速度更快,硬件资源更加丰富,因此利用pc机进行开发会提高开发效率。
- 嵌入式系统MCU体系结构和指令集不同,因此需要安装交叉编译工具进行编译,这样编译的目标程序才能够在相应的平台上比如:ARM、MIPS、POWEPC上正常运行。
交叉开发环境的硬件组成
- 开发主机(比如电脑)
- 目标机(开发板)
- 二者的链接介质,常用的主要有3种方式:
① 串口线
② Usb线
③ 网线
有了对应的硬件介质,还需要软件“介质”:
对于串口:通常用的有串口调试助手,putty工具等,工具很多,功能都差不多,会用一两款就可以;
对于USB线:当然必须要有USB的驱动才可以,一般芯片公司会提供,比如对于三星的芯片,USB下载主要由DNW软件来完成;
对于网线:必须要有网络协议支持才可以,常用的服务主要两个:
① tftp服务
主要用于实现文件的下载,比如开发调试的过程中,主要用tftp把要测试的bootloader、kernel和文件系统直接下载到内存中运行,而不需要预先烧录到Flash芯片中
一方面,在测试的过程中,往往需要频繁的下载,如果每次把这些要测试的文件都烧录到Flash中然后再运行也可以,但是缺点是:过程比较麻烦,而且Flash的擦写次数是由限的;
另外一方面:测试的目的就是把这些目标文件加载到内存中直接运行就可以了,而tftp就刚好能够实现这样的功能,因此,更没有必要把这些文件都烧录到Flash中去
② nfs服务
主要用于实现网络文件的挂载,实际上是实现网络文件的共享,在开发的过程中,通常在系统移植的最后一步会制作文件系统,那么这是可以把制作好的文件系统放置在我们开发主机PC的相应位置,开发板通过nfs服务进行挂载,从而测试我们制作的文件系统是否正确,在整个过程中并不需要把文件系统烧录到Flash中去,而且挂载是自动进行挂载的,bootload启动后,kernel运行起来后会根据我们设置的启动参数进行自动挂载,因此,对于开发测试来讲,这种方式非常的方便,能够提高开发效率。
拓展:另外,还有一个名字叫samba的服务也比较重要,主要用于文件的共享,这里说的共享和nfs的文件共享不是同一个概念,nfs的共享是实现网络文件的共享,而samba实现的是开发主机上Windows主机和Linux虚拟机之间的文件共享,是一种跨平台的文件共享,方便的实现文件的传输。
这几种开发的工具在嵌入式开发中是必备的工具,对于嵌入式开发的效率提高做出了伟大的贡献,因此,要对这几个工具熟练使用,这样开发效率会提高很多。等测试完成以后,就会把相应的目标文件烧录到Flash中去,也就是等发布产品的时候才做的事情,因此对于开发人员来说,所有的工作永远是测试。
交叉编译工具链
前面已经准备好了交叉开发环境的硬件部分和一部分软件,最后还缺少交叉编译器。
交叉编译和本地编译:
- 本地编译,就是在当前平台编译,编译得到的程序也是在当前平台执行。
- 交叉编译,就是在当前平台编译,但是编译得到的程序要放到目标平台(非当前平台)上执行。
用来编译这种跨平台程序的编译器就叫交叉编译器,相对来说,用来做本地编译的工具就叫本地编译器。所以要生成在目标机上运行的程序,必须要用交叉编译工具链来完成。
交叉编译工具是一个由编译器、连接器和解释器组成的综合开发环境,交叉编译工具链主要由binutils(主要包括汇编程序as和链接程序ld)、gcc(为GNU系统提供C编译器)和glibc(一些基本的C函数和其他函数的定义) 3个部分组成。有时为了减小libc库的大小,也可以用别的 c 库来代替 glibc,例如 uClibc、dietlibc 和 newlib。
构建交叉编译工具链的三种方法
-
方法一 :分步编译和安装交叉编译工具链所需要的库和源代码,最终生成交叉编译工具链。该方法相对比较困难,适合想深入学习构建交叉工具链的人。如果只是想使用交叉工具链,建议使用下列的方法二构建交叉工具链。
-
方法二: 通过Crosstool-ng脚本工具来实现一次编译,生成交叉编译工具链,该方法相对于方法一要简单许多,并且出错的机会也非常少,建议大多数情况下使用该方法构建交叉编译工具链。
crosstool-ng是一个脚本工具,可以制作出适合不同平台的交叉编译工具链,在进行制作之前要安装一下软件:
$ sudo apt-get install g++ libncurses5-dev bison flex texinfo automake libtool patch gcj cvs cvsd gawk
crosstool脚本工具可以在http://ymorin.is-a-geek.org/projects/crosstool下载到本地,然后解压,接下来就是进行安装配置了,这个配置优点类似内核的配置。主要的过程有以下几点:
① 设定源码包路径和交叉编译器的安装路径
② 修改交叉编译器针对的构架
③ 增加编译时的并行进程数,以增加运行效率,加快编译,因为这个编译会比较慢。
④ 关闭JAVA编译器 ,减少编译时间
⑤ 编译
⑥ 添加环境变量
⑦ 刷新环境变量。
⑧ 测试交叉工具链 -
方法三 :直接通过网上下载已经制作好的交叉编译工具链。该方法的优点是简单省事,但与此同时该方法有一定的弊端就是局限性太大,因为毕竟是别人构建好的,也就是固定的,没有灵活性,所以构建所用的库以及编译器的版本也许并不适合你要编译的程序,同时也许会在使用时出现许多莫名其妙的错误,建议慎用此方法。
bootloader的选择和移植
bootloader介绍
引导加载程序(Boot Loader)就是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核准备好正确的环境。

Flash存储中存放文件的分布图
为什么系统移植之前要先移植BootLoader?
BootLoader的任务是引导操作系统,所谓引导操作系统,就是启动内核,让内核运行就是把内核加载到内存RAM中去运行,那先问两个问题:第一个问题,是谁把内核搬到内存中去运行?第二个问题:我们说的内存是SDRAM,大家都知道,这种内存和SRAM不同,最大的不同就是SRAM只要系统上电就可以运行,而SDRAM需要软件进行初始化才能运行,那么在把内核搬运到内存运行之前必须要先初始化内存吧,那么内存是由谁来初始化的呢?其实这两件事情都是由bootloader来干的,目的是为内核的运行准备好软硬件环境,没有bootloadr系统当然不能跑起来。
bootloader的分类
首先更正一个错误的说法,很多人说bootloader就是u-boot,这种说法是错误的,确切来说是u-boot是bootloader的一种。也就是说bootloader具有很多种类,大概的分类如下图所示:
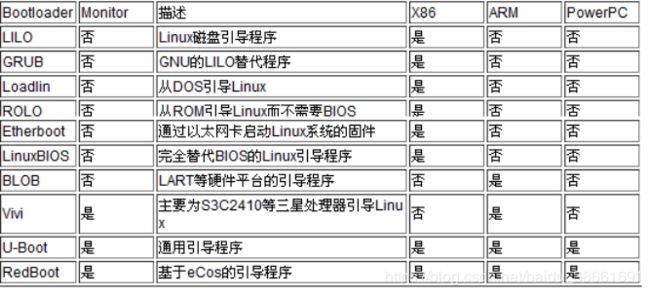
bootloader分类图
由上图可以看出,不同的bootloader具有不同的使用范围,其中最令人瞩目的就是有一个叫U-Boot的bootloader,是一个通用的引导程序,而且同时支持X86、ARM和PowerPC等多种处理器架构。U-Boot,全称 Universal Boot Loader,是遵循GPL条款的开放源码项目,是由德国DENX小组开发的用于多种嵌入式CPU的bootloader程序,对于Linux的开发,德国的u-boot做出了巨大的贡献,而且是开源的。
uboot介绍
Uboot的特点
- 开放源码;
- 支持多种嵌入式操作系统内核,如Linux、NetBSD, VxWorks, QNX, RTEMS, ARTOS, LynxOS;
- 支持多个处理器系列,如PowerPC、ARM、x86、MIPS、XScale;
- 较高的可靠性和稳定性;
- 高度灵活的功能设置,适合U-Boot调试、操作系统不同引导要求、产品发布等;
- 丰富的设备驱动源码,如串口、以太网、SDRAM、FLASH、LCD、NVRAM、EEPROM、RTC、键盘等;
- 较为丰富的开发调试文档与强大的网络技术支持;
其实,把u-boot可以理解为是一个小型的操作系统。
Uboot的目录结构
| 目录名 | 功能介绍 |
|---|---|
| board | 目标板相关文件,主要包含SDRAM、FLASH驱动; |
| common | 独立于处理器体系结构的通用代码,如内存大小探测与故障检测; |
| cpu | 与处理器相关的文件。如mpc8xx子目录下含串口、网口、LCD驱动及中断初始化等文件; |
| driver | 通用设备驱动,如CFI FLASH驱动(目前对INTEL FLASH支持较好) |
| doc | U-Boot的说明文档; |
| Examples | 可在U-Boot下运行的示例程序;如hello_world.c,timer.c; |
| include | U-Boot头文件;尤其configs子目录下与目标板相关的配置头文件是移植过程中经常要修改的文件; |
| lib_xxx | 处理器体系相关的文件,如lib_ppc, lib_arm目录分别包含与PowerPC、ARM体系结构相关的文件; |
| net | 与网络功能相关的文件目录,如bootp,nfs,tftp; |
| post | 上电自检文件目录。尚有待于进一步完善; |
| rtc | RTC驱动程序; |
| tools | 用于创建U-Boot S-RECORD和BIN镜像文件的工具; |
Uboot的工作模式
U-Boot的工作模式有启动加载模式和下载模式。
- 启动加载模式是Bootloader的正常工作模式,嵌入式产品发布时,Bootloader必须工作在这种模式下,Bootloader将嵌入式操作系统从FLASH中加载到SDRAM中运行,整个过程是自动的。
- 下载模式就是Bootloader通过某些通信手段将内核映像或根文件系统映像等从PC机中下载到目标板的SDRAM中运行,用户可以利用Bootloader提供的一些令接口来完成自己想要的操作,这种模式主要用于测试和开发。
Uboot的启动过程
大多数BootLoader都分为stage1和stage2两大部分,U-boot也不例外。依赖于cpu体系结构的代码(如设备初始化代码等)通常都放在stage1且可以用汇编语言来实现,而stage2则通常用C语言来实现,这样可以实现复杂的功能,而且有更好的可读性和移植性。
-
stage1(start.s代码结构)
U-boot的stage1代码通常放在start.s文件中,它用汇编语言写成,其主要代码部分如下:
(1) 定义入口。由于一个可执行的image必须有一个入口点,并且只能有一个全局入口,通常这个入口放在rom(Flash)的0x0地址,因此,必须通知编译器以使其知道这个入口,该工作可通过修改连接器脚本来完成。
(2)设置异常向量(exception vector)。
(3)设置CPU的速度、时钟频率及中断控制寄存器。
(4)初始化内存控制器 。
(5)将rom中的程序复制到ram中。
(6)初始化堆栈 。
(7)转到ram中执行,该工作可使用指令ldrpc来完成。 -
stage2(C语言代码部分)
lib_arm/board.c中的start armboot是C语言开始的函数,也是整个启动代码中C语言的主函数,同时还是整个u-boot(armboot)的主函数,该函数主要完成如下操作:
(1)调用一系列的初始化函数。
(2)初始化flash设备。
(3)初始化系统内存分配函数。
(4)如果目标系统拥有nand设备,则初始化nand设备。
(5)如果目标系统有显示设备,则初始化该类设备。
(6)初始化相关网络设备,填写ip,c地址等。
(7)进入命令循环(即整个boot的工作循环),接受用户从串口输入的命令,然后进行相应的工作。
Uboot的移植
-
下载稳定的源码包
-
解压源码包后添加我们自己的开发板的平台信息。
-
修改相应目录的文件名,和相应目录的Makefile,指定交叉工具链。
-
编译
-
针对我们的平台进行相应的移植,主要包括修改SDRAM的运行地址。
-
“开关”相应的宏定义
-
添加Nand和网卡的驱动代码
-
优化go命令
-
重新编译 make distclean(彻底删除中间文件和配置文件) make 板子型号_config(配置我们的开发板) make(编译出我们的u-boot.bin镜像文件)
-
设置环境变量,即启动参数,把编译好的u-boot下载到内存中运行,过程如下:
1)、配置开发板网络
ip地址配置:$setenv ipaddr 192.168.0.6 //配置ip地址到内存的环境变量 $saveenv //保存环境变量的值到nandflash的参数区网络测试:
在开发板上ping开发主机的ip:
$ ping 192.168.0.157(开发主机的ip地址)如果网络测试失败,从下面几个方面检查网络:
网线连接是否正常
开发板和开发主机的ip地址是否配置在同一个网段
如果开发主机是虚拟机,那么虚拟机网络一定要采用桥接(VM–Setting–>option),连接开发板时,虚拟机需要设置成静态ip地址2)、在开发板上,配置tftp服务器(开发主机)的ip地址
$setenv serverip 192.168.0.157(开发主机的ip地址) $saveenv
3)、拷贝u-boot.bin到/tftpboot(虚拟机上的目录)
4)、通过tftp下载u-boot.bin到开发板内存
$ tftp 20008000(内存地址即可) u-boot.bin(要下载的文件名)如果上面的命令无法正常下载:
serverip配置是否正确
tftp服务启动失败,重启tftp服务
#sudo service tftpd-hpa restart5) 、烧写u-boot.bin到nandflash的0地址
$nand erase 0(起始地址) 40000(大小) //擦出nandflash 0 - 256k的区域 $nand write 20008000((缓存u-boot.bin的内存地址) 0(nandflash上u-boot的位置) 40000(烧写大小)
kernel的配置、编译、和移植
主要步骤:
-
下载好需要的内核版本,并在主目录解压。
-
修改顶层目录下的Makefile,主要修改平台的体系架构和交叉编译器,比如arm架构和arm-cortex_a8平台交叉编译链,代码如下:
ARCH ?= $(SUBARCH) CROSS_COMPILE ?= $(CONFIG_CROSS_COMPILE:"%"=%) 修改以上代码为: ARCH ?= arm ---->体系架构是arm架构 CROSS_COMPILE ?= arm-cortex_a8-linux-gnueabi----->交叉编译器是arm-cortex_a8平台的
注意:这两个变量值会直接影响顶层Makefile的编译行为,即选择编译哪些代码,用什么编译器进行编译。 -
拷贝标准版配置文件,目的是得到跟我们开发板相关的配置信息。
$ cp arch/arm/configs/开发板芯片型号_defconfig .config
这里拷贝arch/arm/configs/开发板芯片型号_defconfig到 .config文件是选取跟我们开发板相关的代码。因为Linux支持的平台非常非常多,不仅仅是ARM处理器,当然我们编译的时候只需要编译跟我们平台相关的代码就可以了,平台相关的不需要编译,把相应平台的_deconfig直接拷贝到顶层目录的.config文件中,这样.config文件中就记录了我们要移植平台的平台信息,因为在配置内核时,系统会把所有的配置信息都保存在顶层目录的.config文件中。
注意: 在第一次进行make menuconfig时,系统会根据我们选取的平台信息自动选取相关的代码和模块,因此我们只需要进入然后再退出,选择保存配置信息就行了,系统会把这些跟我们移植平台相关的所有配置信息全部保存在顶层目录的.config文件中。 -
配置内核
$make menuconfig
注意:第一次进去,不做任何操作,直接退出,在退出时提示是否保存配置信息,一定要保存配置信息,点击“YES”。这样我们的.config中就已经保存了我们开发平台的信息。
在这个环节,我们需要关心一个问题,make menuconfig时,系统到低都做了哪些事情?
图形化的界面中的相关内容是从哪里来的?
图形化的界面当然是由一个特殊的图形库来实现的,还记得第一次make menuconfig时,系统并没有出现图形化的界面,而是报错了,并且提示我们缺少 ncurses-devel ,此时只需要按照要求安装一个libncurses5-dev就行了,sudo apt-get install libncurses5-dev,有了这个图形化库的支持,我们才能够正常显示图形化界面。
好了,图形化界面的问题解决了,那还有另外一个问题就是图形化界面里面的内容是从哪里来的?要回答这个问题,我们就要提一下Linux内核的设计思想了,Linux 内核是以模块的方式来组织这个操作系统的,那么,为什么要用模块的方式来组织呢?模块的概念又是什么呢?下面一一回答这个问题。
Linux2.6内核的源码树目录下一般都会有两个文件:Kconfig和Makefile。分布在各目录下的Kconfig构成了一个分布式的内核配置数据库,每个Kconfig分别描述了所属目录源文件相关的内核配置菜单。每个目录都会存放功能相对独立的信息,在每个目录中会存放各个不同的模块信息,比如在/dev/char/目录下就存放了所有字符设备的驱动程序,而这些程序代码在内核中是以模块的形式存在的,也就是说当系统需要这个驱动的时候,会把这个驱动以模块的方式编译到系统的内核中,编译分为静态编译和动态编译,静态编译内核体积比动态编译的体积要大,前面已经说了每个目录下面都会有一个Kconfig的文件,我们还会问,这个文件中都存放了什么信息?前面说了,每个目录的Kconfig文件描述了所属目录源文件相关的内核配置菜单,有其特殊的语法格式,图形化界面的文字正是从这个文件中读取出来的,如果把这个文件中的相应目录文件的信息全部删除,那么在图形化界面中将看不到该模块的信息,因此也不能进行模块的配置。
在内核配置make menuconfig(或xconfig等)时,系统会自动从Kconfig中读出配置菜单,用户配置完后保存到.config(在顶层目录下生成)中。在内核编译时,主Makefile调用这个.config,(.config的重要性就体现在,它保存了我们的所有的配置信息,是我们选取源代码并且进行编译源代码的最终依据!!!)就知道了用户对内核的配置情况。上面的内容说明:Kconfig就是对应着内核的配置菜单。假如要想添加新的驱动到内核的源码中,可以通过修改Kconfig来增加对我们驱动的配置菜单,这样就有途径选择我们的驱动,假如想使这个驱动被编译,还要修改该驱动所在目录下的Makefile。
因此,一般添加新的驱动时需要修改的文件有两种,即:Kconfig 和相应目录的Makefile(注意不只是两个),系统移植的重要内容就是给内核添加和删除相应的模块,因此主要修改的内核文件就是Kconfig 和相应目录的Makefile这两个文件。 -
编译内核
$make zImage
通过上述操作我们能够在 arch/arm/boot 目录下生成一个 zImage 文件,这就是经过压缩的内核镜像。
内核的编译过程是非常复杂的,注意这里的编译是静态编译,此时会执行顶层目录下的Makefile中的zImage命令,在执行的过程中,会根据当前目录的.config文件去选择编译源代码。 -
测试内核
根文件系统的制作
文件系统的制作和移植是系统移植的最后一道工序。
文件系统简介
文件系统我们在日常生活中则很少听说,但是它确实存在,只是名字不叫文件系统罢了,一般叫资料库,进行了分类索引的资料库叫文件系统。
对于计算机而言,文件其实就是资料数据,只能存储在物理介质上面,比如:硬盘,但是我们人不可能自己读取物理介质上的文件,或者自己把文件写入物理介质,物理介质上文件的读写只能采用程序来完成,为了方便实现,程序又被分成了物理介质驱动程序、内容存储程序和文件内容存储程序:
- 物理介质驱动程序专门用于从物理介质上存取数据;
- 内容存储程序用于把文件内容和文件属性信息打包;
- 文件内容存储程序用于把用户输入形成文件内容,或者取得文件内容显示出来。
可以把一个文件系统(倒树)分解成多个文件系统(倒树)分别存放到存储介质上,比如:一个存储到光盘里,一个存储到硬盘中,在使用时,我们把光盘里的文件系统的根目录挂到硬盘文件系统的一个目录下面,这样访问这个目录就相当于是访问光盘的根目录了,找到了根目录,我们也就可以访问整个光盘上的文件系统了。
“在Linux系统中一切皆是文件”这句话是学习Linux系统的时候常常听到的一句话。虽然有些夸张,但是它揭示了文件系统对于Linux系统的重要性;实际上文件系统对于所有的操作系统都很重要,因为它们把大部分的硬件设备和软件数据以文件的形式进行管理。Linux系统对设备和数据的管理框架图如下:

文件系统管理框架图
- VFS(virtual file system)是虚拟文件系统,它管理特殊文件(虚拟文件)、磁盘文件和设备文件
- fs_operations结构是由一系列文件操作接口函数组成,由文件系统层来完成,为VFS提供文件操作;
- 在文件系统层,磁盘文件要实现各种文件系统(如:ext2),设备文件要实现各种抽象的设备驱动。
- 在设备驱动层,磁盘驱动要实现各种磁盘的驱动程序,其他设备驱动要实现具体的设备驱动。
- 物理层就是设备自身。
常用文件系统
由于存储介质有很多种,所以没有办法用一种统一的格式存放文件系统到各种不同的存储介质上,而是需要多种不同的存储格式来适应各种存储介质的特性,以求达到存取效率和空间利用率的最优化,这样就需要对每种存储格式制定一个规范,这些规范就叫文件系统类型。常见的文件系统类型有:
- Dos平台
FAT16 - windows平台
FAT16、FAT32、NTFS - Linux平台
Minix、ext、ext2 、ext3 、ISO9660 、jffs2, yaffs, yaffs2、cramfs, romfs, ramdisk, rootfs、proc、sysfs、usbfs、devpts、 tmpfs & ramfs、NFS
Linux支持的文件系统最多。如果以不同的介质来分类:
- 磁盘
FAT16、 FAT16、FAT32、NTFS、ext、ext2 、ext3、Minix - 光盘
ISO9660 - Flash
jffs2, yaffs, yaffs2、cramfs, romfs - 内存
Ramdisk、tmpfs & ramfs - 虚拟
rootfs、proc、sysfs、usbfs、devpts、NFS
常用的存储介质理论上都可以用于存储Linux支持的文件系统;因为我们这里只研究嵌入式系统,而嵌入式系统由于体积和移动特性的限制,不能采用磁盘和光盘,所以只能采用flash类的存储设备、内存和虚拟存储设备作为文件系统的存储介质;
flash芯片的驱动程序是由系统来提供,所以它的存取特点完全是flash自身的特点,这时最好有更加适合flash的文件系统——Jffs、Yaffs、Cramfs和Romfs。这些文件系统都是嵌入式Linux系统中常用的文件系统,可以根据特点来选择使用它们,特点如下:
共同点:基于MTD驱动
- Jffs
A.针对NOR Flash的实现
B.基于哈希表的日志型文件系统
C.采取损耗平衡技术,每次写入时都会尽量使写入的位置均匀分布
D.可读写,支持数据压缩
E.崩溃/掉电安全保护
F.当文件系统已满或接近满时,因为垃圾收集的关系,运行速度大大放慢 - Yaffs
A.针对Nand Flash的实现
B.日志型文件系统
C.采取损耗平衡技术,每次写入时都会尽量使写入的位置均匀分布
D.可读写,不支持数据压缩
E.挂载时间短,占用内存小
F.自带Nandflash驱动,可以不使用VFS和MTD - Cramfs
A.单页压缩,支持随机访问,压缩比高达2:1
B.速度快,效率高
C.只读,有利于保护文件系统免受破坏,提高了系统的可靠性,但是无法对其内容进行扩充 - Romfs
A.简单的、紧凑的、只读的文件系统
B.顺序存放数据,因而支持应用程序以XIP(execute In Place,片内运行)方式运行,在系统运行时,节省RAM空间
特有的文件系统类型:Ramdisk文件系统
在Linux系统中,内存经常用于存储文件系统,这种叫做Ramdisk。Ramdisk有两种,一种是完全把内存看成物理存储介质,利用内存模拟磁盘,运用磁盘的文件系统类型;另一种只是在内存中存储了文件系统逻辑结构,运用tmpfs & ramfs文件系统类型:
tmpfs & ramfs
- 概述
用物理内存模拟磁盘分区,挂载这种分区后,就可以跟读写磁盘文件一样读写这里面的文件,但是操作速度要比磁盘文件快得多;所以一般应用在下面几个方面:
1)、读写速度要求快的文件应该放在这种文件系统中
2)、磁盘分区为flash的情况下,把需要经常读写的文件放在这种文件系统中,然后定期写回flash
3)、系统中的临时文件,如/tmp、/var目录下的文件应该放在这种文件系统中
4)、/dev设备文件(因为设备文件随驱动和设备的加载和卸载而变化),应该放在这种文件系统中 - 特点
1)、由于数据都存放在物理内存中,所以系统重启后,这个文件系统中的数据会全部丢失
2)、ramfs在没有指定最大的大小值情况下,会自动增长,直到用掉系统中所有的物理内存为止,这时会导致系统的崩溃,建议挂载时最好限定其最大的大小值
3)、tmpfs如果指定了大小值,自动增长至大小值后,系统会限定它的大小;这个文件系统占用的物理内存页可以被置换到swap分区,但是ramfs不行
根文件系统制作步骤

根文件系统制作流程