bigtable设计浅析和疑问
bigtable 为google开发的大型分布式表格系统,为最早期的模型设计。作为一种了解大数据存储和访问的指引了解大数据处理的逻辑。
简述其基本构架图示如下:
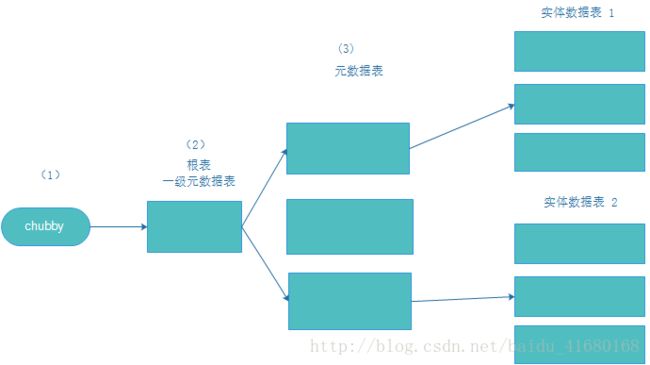
chubby :可以理解为控制中心。及所有访问机械如客户端接入
根表 :bigtable数据检索区。第一级缓冲索引区
元数据表:二级缓冲索引区
实体数据表:为实际存储数值的表区域
可以这么假设理解:bigtable部署在100台机器上的分布式缓存数据库。
寻找 com.cnn.www域页面信息。通过chubby访问根表确定域信息所在机器集群(假设100台机器划分10台为一个存储集群)。进入存取机器集群,以元数据表索引区确定数据存储机器或者实体表。
这里采用了二层缓冲协议细分数据存储区域(为什么不是一层呢?数据量级的问题)
对实体表数据存储的逻辑:
拿一个网上图表示例如下

这里有几点疑问:1.表是以行为唯一关键字索引,访问及修改以行为原子单位。
2.一行包含多个列,并且列标志相同的列将压缩为一个列族。列族为访问数据的最小控制单元
以上图解释anchor:cnnsi.com和anchor:my.look.ca具有相同的列标志anchor,压缩为同一个列族
问题是:bigtable以行关键字com.cnn.www作为全局排序索引。搜索索引访问行,并为确定最终访问单元访问列族。
1)列族信息是怎么存储?
2)行为原子单位访问。即对行访问存在锁操作,这个所在哪设置?怎么设置?不可能存在每一个行数据对应一个所设置。共享锁,如何确定不同访问访问行信息拿到相同的锁?
数据访问假设:
行信息中包含多个列族。列族以连续存储区间绑定在行关键字结构单元中。
并且列族单元亦以连续空间保存期列信息
那么数据访问可以理解为。在全局有序排序中搜索行信息,在确定行单元信息地址可直接访问列族信息直接访问最终目标数据。
另:行信息或者列族中对最终数据的访问应该是地址访问(因为存储副本及空间损耗的原因),那么数据块应该有多个不同行或者列族指向的信息,也就是计数器。计数器的怎么设计,数据怎么维持有效?
锁的假设: