Spark-ml模型保存为PMML格式,PMML version不兼容问题。
前言
最近使用spark-ml做数据模型训练,考虑到怎么把模型部署到线上环境。
本尝试spring-boot启动spark-local模式预测,发现线上预测需要200ms~300ms,耗时太多。
所以考虑把spark模型转换为pmml格式。
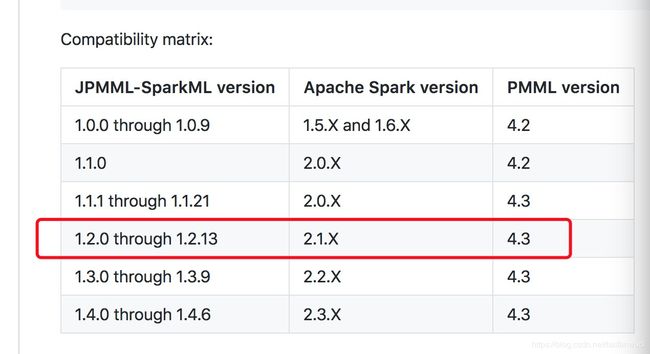
我的spark集群版本为2.1.3
本机local模式
采用了JPMML-SparkML,本地环境配置如下:
org.apache.spark
spark-mllib_2.11
${spark.version}
provided
org.jpmml
pmml-model
org.jpmml
jpmml-sparkml
1.2.13
local模式保存为pmml代码:
import org.dmg.pmml.PMML;
import org.jpmml.model.JAXBUtil;
import org.jpmml.sparkml.PMMLBuilder;
...
//trainData是模型训练输入dataset
StructType schema = trainData.schema();
PMML pmml = new PMMLBuilder(schema, pipelineModel).build();
String targetFile = "D://model/pmml/pipemodel";
FileOutputStream fis = new FileOutputStream(targetFile);
try {
JAXBUtil.marshalPMML(pmml, new StreamResult(fis));
} catch (JAXBException e) {
e.printStackTrace();
}
...
但是放在集群上无法使用。
集群上spark-mllib_2.11是包含pmml-model的,没权限动整个公司的spark,无法exclude,默认为4.2版本。不会主动加载jpmml-sparkml的4.3版本 pmml-model
集群方式
所以采用shaded方式重新打包,重启起一个项目。
4.0.0
com.tc.ml
pmml-model
1.0
org.jpmml
jpmml-sparkml
1.2.13
org.apache.maven.plugins
maven-shade-plugin
3.1.0
package
shade
org.dmg.pmml
org.shaded.dmg.pmml
org.jpmml.model
org.shaded.jpmml.model
注意下github上jpmml-sparkml shade打包方式为:
org.dmg.pmml
org.shaded.dmg.pmml
org.jpmml
org.shaded.jpmml
但无法使用VectorAssembler,
所以第二个relocation改为
org.jpmml.model
org.shaded.jpmml.model
建依赖改为打包后的pmml-model-1.0.jar包
org.jpmml
jpmml-sparkml
1.2.13-shaded
system
${project.basedir}/lib/pmml-model-1.0.jar
保存为hdfs
import org.jpmml.sparkml.PMMLBuilder;
import org.shaded.dmg.pmml.PMML;
import org.shaded.jpmml.model.JAXBUtil;
....
代码省略
....
StructType schema = trainData.schema();
PMML pmml = new PMMLBuilder(schema, pipelineModel).build();
String targetFile = "/data/twms/traffichuixing/model/pmml/pipepmml";
Path path=new Path(targetFile);
FSDataOutputStream fos = fileSystem.create(path);
try {
JAXBUtil.marshalPMML(pmml, new StreamResult(fos));
} catch (JAXBException e) {
e.printStackTrace();
}finally {
fos.close();
}
.....
代码省略
....
附件:
完整demo
package com.tc.ml.model.pipeline;
import com.tc.common.HDFSFileSystem;
import com.tc.ml.base.AbstractSparkSql;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.classification.RandomForestClassificationModel;
import org.apache.spark.ml.classification.RandomForestClassifier;
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.evaluation.RegressionEvaluator;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.ml.feature.VectorIndexer;
import org.apache.spark.ml.linalg.SparseVector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.StructType;
//// 没有shade原来带入依赖
//import org.dmg.pmml.PMML;
//import org.jpmml.model.JAXBUtil;
//import org.jpmml.sparkml.PMMLBuilder;
////shade后依赖导入
import org.jpmml.sparkml.PMMLBuilder;
import org.shaded.dmg.pmml.PMML;
import org.shaded.jpmml.model.JAXBUtil;
import javax.xml.bind.JAXBException;
import javax.xml.transform.stream.StreamResult;
import java.io.*;
public class RTPipelineTrain extends AbstractSparkSql {
FileSystem fileSystem = HDFSFileSystem.fileSystem;
@Override
public void executeProgram(String[] args, SparkSession spark) throws IOException {
Dataset trainData = onlineTrainTable(spark).cache();
String[] features=new String[]{
"category", "future_day",
"banner_min_time","banner_min_price",
"page_train", "page_flight", "page_bus", "page_ship", "page_transfer",
"start_end_distance", "total_transport", "high_railway_percent", "avg_time", "min_time",
"avg_price", "min_price",
"label_05060801", "label_05060701", "label_05060601", "label_02050601", "label_02050501", "label_02050401",
"is_match_category", "train_consumer_prefer", "flight_consumer_prefer", "bus_consumer_prefer"
};
VectorAssembler assembler = new VectorAssembler().setInputCols(features).setOutputCol("features");
RandomForestClassifier rf = new RandomForestClassifier()
.setLabelCol("isclick")
.setFeaturesCol("features")
.setMaxDepth(7)
.setNumTrees(60)
.setSeed(2018)
// .setMinInfoGain(0)
.setMinInstancesPerNode(1);
;
Pipeline pipeline = new Pipeline().setStages(new PipelineStage[]{assembler,
rf
});
PipelineModel pipelineModel = pipeline.fit(trainData);
// pipelineModel.write().overwrite().save("/data/twms/traffichuixing/model/stage/random-forest");
Dataset testData = onlineTestTable(spark);
Dataset predictionResult = pipelineModel.transform(testData);
predictionResult.show(false);
BinaryClassificationEvaluator binaryClassificationEvaluator = new BinaryClassificationEvaluator().setLabelCol("isclick");
Double aucArea = binaryClassificationEvaluator.evaluate(predictionResult);
System.out.println("------------------------------------------------");
System.out.println("auc:is " + aucArea);
RandomForestClassificationModel randomForestClassificationModel = (RandomForestClassificationModel) (pipelineModel.stages()[1]);
System.out.println("feature_importance:" + randomForestClassificationModel.featureImportances());
SparseVector vector=(SparseVector) randomForestClassificationModel.featureImportances();
int[] indices=vector.indices();
double[] values=vector.values();
for(int i=0;i onlineTrainTable(SparkSession spark) {
Dataset trainData = spark.sql("select * from tmp_trafficwisdom.ml_train_data where start_end_distance>=0 and future_day>=0 ")
.drop("userid,city,from_place,to_place,start_city_name,end_city_name,start_city_id,end_city_id".split(","));
return trainData;
}
private Dataset onlineTestTable(SparkSession spark) {
Dataset testData = spark.sql("select * from tmp_trafficwisdom.ml_test_data where start_end_distance>=0 and future_day>=0")
.drop("userid,city,from_place,to_place,start_city_name,end_city_name,start_city_id,end_city_id".split(","));
return testData;
}
private Dataset offlineTable(SparkSession spark) {
Dataset trainData = spark.read()
.option("inferschema", "true")
.option("header", "true")
.option("encoding", "gbk")
.csv("D:\\data\\csv\\ml_train_data.csv")
.drop("userid,city,operators,from_place,to_place,start_city_name,end_city_name,memberid,start_city_id,end_city_id".split(","))
.na().drop();
trainData.printSchema();
return trainData;
}
public static void main(String[] args) throws IOException {
RTPipelineTrain rtPipelineTrain = new RTPipelineTrain();
rtPipelineTrain.runAll(args, true);
}
}