给Linux增加系统调用,并编写对应的linux应用程序
前言
这是研一上学期的Linux内核分析作业。这个课程还是很有用的。
题目要求:
(1)能够返回指定进程(通过指定PID)的任务描述符;
(2)能够返回指定进程(通过指定PID)的进程地址空间的布局和统计信息(代码段、数据段、BSS段、堆、栈等区域的位置和大小、包含多少个虚拟内存区VMA、每个VMA的属性、该进程页表的地址、已映射的物理内存大小等。)(该题目需要研究Linux 进程描述符和内存描述符mm_struct。)
相关知识
系统调用是内核为用户进程提供服务的一种方式。通过系统调用,内核能够提供给用户模式下的进程和硬件设备的接口,保护对内核所管理的资源的访问,提高系统安全,提高程序的可移植性。

根据题目,本质就是要求在内核中设计实现一个新的函数,通过指定的进程ID可以返回该进程有关信息。
一个进程ID号,其实没有那么简单。因为Linux系统中有命名空间这种设定,目前实现的有六种不同的命名空间,分别为mount命名空间、UTS命名空间、IPC命名空间、用户命名空间、PID命名空间、网络命名空间。对于PID命名空间,有不同的层次,像图2这样。
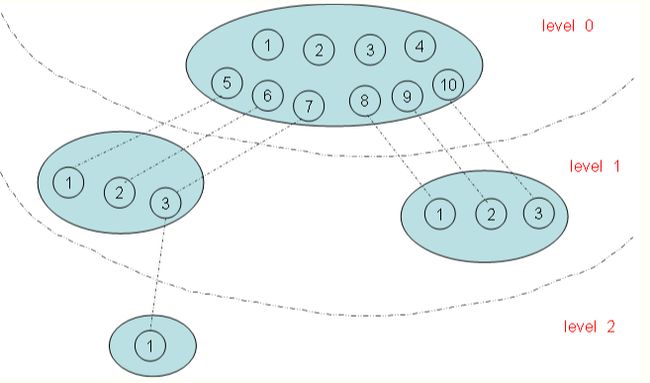
在上图有四个命名空间,一个父命名空间衍生了两个子命名空间,其中的一个子命名空间又衍生了一个子命名空间。以PID命名空间为例,由于各个命名空间彼此隔离,所以每个命名空间都可以有 PID 号为 1 的进程;但又由于命名空间的层次性,父命名空间是知道子命名空间的存在,因此子命名空间要映射到父命名空间中去,因此上图中 level 1 中两个子命名空间的六个进程分别映射到其父命名空间的PID 号5~10。
命名空间增大了 PID 管理的复杂性,对于某些进程可能有多个PID——在其自身命名空间的PID以及其父命名空间的PID,凡能看到该进程的命名空间都会为其分配一个PID。因此就有:
全局ID:在内核本身和初始命名空间中唯一的ID,在系统启动期间开始的 init 进程即属于该初始命名空间。系统中每个进程都对应了该命名空间的一个PID,叫全局ID,保证在整个系统中唯一。
局部ID:对于属于某个特定的命名空间,它在其命名空间内分配的ID为局部ID,该ID也可以出现在其他的命名空间中。
所以根据题目,可以假设我们需要提供的是全局PID。
那么如何根据PID的数值找到task_struct结构体呢:
1.通过 PID 计算 pid 挂接到哈希表 pid_hash[] 的表项;
2. 遍历该表项,找到 pid 结构体中 nr 值与 PID 值相同的那个 pid
3.通过该 pid 结构体的 tasks 指针找到 node
4. 最后根据内核的 container_of 机制就能找到 task_struct 结构体
task_struct结构体包含了一个进程所需的所有信息。它定义在include/linux/sched.h文件中。
struct task_struct{
… …
struct mm_struct *mm;
pid_t pid;
};
其实在题目中要求返回的数据里面,绝大部分是跟内存管理有关的的所以在task_struct结构体里用到的成员变量不多 mm_struct mm 负责进程内存管理的结构体,pid是Linux为进程分配的pid结构体,可以通过pid找到task_struct这个结构体。
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
pgd_t * pgd; /* 指向页表的页目录*/
int map_count; /* number of VMAs */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED &~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE &~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
unsigned long start_code, end_code,start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned longarg_start, arg_end, env_start, env_end;
可以看到mm_struct结构体中有我们感兴趣的信息。代码段、数据段、BSS段、堆、栈等区域的位置和大小,mmap是vma链表的头部,可以遍历该链表找到所有vma信息。
structvm_area_struct {
/* The first cache line has the infofor VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task,sorted by address */
struct vm_area_struct *vm_next,*vm_prev;
struct rb_node vm_rb;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* A file's MAP_PRIVATE vma can be inboth i_mmap tree and anon_vma
* list, after a COW of one of the filepages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can onlybe in an anon_vma list.
*/
struct list_head anon_vma_chain; /*Serialized by mmap_sem &
*page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with thisstruct. */
const struct vm_operations_struct*vm_ops;
/* Information about our backing store:*/
unsigned long vm_pgoff; /* Offset (within vm_file) inPAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
atomic_long_t swap_readahead_info;
}__randomize_layout;
vma中的信息主要有vma起始与结束地址,读写和执行权限以及共享还是私有的属性,VMA对应的segment在映像文件中的偏移,主设备号和次设备号,映像文件的节点号,和映像文件的路径。
主要设计思路和实现方式
给Linux内核添加系统有两种方式。
一是通过修改内核源码。我们在内核源码中,找到对应文件,增加新的系统调用编号,系统调用跳转表项和相应的例程。然后重新编译内核。利用编译好的内核重启系统,则该系统就支持我们新加 的这项系统调用。
的这项系统调用。
第二种方式是通过加载内核模块。内核模块是一种没有经过链接,不能独立运行的目标文件,运行在内核空间中。经过链接装载到内核里面,成为内核的一部分,可以访问内核的公用符号,其概念如图3所示。我们可以设计一个内核模块,在其中实现程序逻辑,然后将其加载到内核中,这样也可实现在内核中增加新的系统调用。
在本次实验中,我先尝试直接修改内核源码的方式添加系统调用,其优点是在程序编写方面更简单,但是每次修改代码需要进行调试而对内核重新编译所耗费大量时间。弊大于利,于是采取增加内核模块的方式。
编写自己的系统调用函数通过pid获得进程描述符,得到内存管理结构体,一一获得各个数据,再遍历vma链表,将虚拟内存区域的信息取出,计算页表地址,计算实际占用的内存大小。
先将上述信息使用printk函数打印到内核态,用命令dmesg查看,最后考虑将上述信息保存到一个结构体,用copy_to_user函数返回给用户态。
模块划分
内核模块代码有自己的程序框架,包括需要的若干头文件,模块入口函数和模块退出函数,GPL许可下引入识别代码宏。
根据题目要求,首先通过指定的pid 找到对应的pid结构体。在根据pid结构体找到对应的task_struct结构体。再修改原系统调用地址,来执行我们自定义的函数,从而实现该功能。
编译好内核模块后,加载到系统中。我们需要知道该项系统调用是否成功。编写测试程序,调用该系统调用,打印返回结果查看。涉及问题是内核态数据和用户态数据的交换
一共有四个文件,mymodule.c 是模块实现代码,result_struct.h中定义了一个结构体,用于将内核态数据传给用户态,testmodule.c是测试代码。Makefile文件用于编译链接文件。
1. mymodule.c
其中包括头文件引入部分,
程序分成几个部分:
- 修改cr0的写保护位,以及恢复其写保护位
- 实现模块构造函数,以及模块析构函数
- 实现自己的系统调用,又分为根据pid获取task_struct
- 获取代码段、数据段、BSS段、堆、栈等区域的位置和大小
- 包含多少个虚拟内存区VMA、每个VMA的属性
- 该进程页表的地址
- 已映射的物理内存大小
2. result_struct.h
成员变量包括代码段、数据段、BSS段、堆、栈等区域的位置和大小、包含多少个虚拟内存区VMA、每个VMA的属性、该进程页表的地址、已映射的物理内存大小。
3. test_module.c
测试程序,主要调用自己实现的系统调用,打印结果检验正确性。
4. Makefile文件,简化程序编译链接的操作。
所遇到的问题及解决的方法
1. 使用直接在内核源码上增加系统调用而付出编译内核的时间代价。
解决:采用增加内核模块的方式
2. 通过find_task_by_pid函数获取task_struct发生错误
解决:使用pid_task(find_vpid(arg1),PIDTYPE_PID)
3. 在修改cr0保护位的时候,movl 出错
解决:movl 改成movq,eax 改成 rax
4. sys_call_table地址不对,导致了如下错误

解决:cat /proc/kallsyms 查看sys_call_table地址
5. 因为上一个错误引发了装载的内核不能被卸载
解决:因为引用计数不为0,重启可破。
6. 格式化打印,十六进制格式的地址,%lx。%lu 针对unsigned long
7. mm结构体中只有栈区的起始地址,没有结束地址
解决:

8. 不知道如何打印出vma的信息
解决:参考内核源码/fs/proc/task_mmu.c 中show_map_vma函数,打印结果跟/proc/#pid/maps文件中差不多
9. ![]()
![]()
解决:因为这个arch_vma_name 是非导出函数,一般来说应该找到这个函数的地址,有一定难度,但是我在grep找了一下这个函数的定义 grep –rn “arch_vma_name”*
看到了在include/linux/arch/x86/mm/mmaps.h 文件中的定义,直接复制粘贴到自己的mymodule.c文件中,可以用。
就能够输出vma的属性了。
程序运行结果及使用说明
(一)使用说明:
修改mymodule.c中sys_call_table的地址。这个地址可以通过
cat /proc/kallsyms 查看。
然后 输入make 命令进行编译链接。
通过命令:sudo insmod mymodule.ko加载模块
在测试程序中,首先定义result_struct 结构体,
structresult_struct *result = (struct result_struct *)malloc(sizeof(structresult_struct));
通过调用366号系统调用:syscall(366, pid, result);
各种信息都保存在result结构体中了。
最后可以通过命令 sudormmod mymodule 卸载
(二)程序运行结果

参考文献
https://www.cnblogs.com/xiaotengyi/p/6907190.html
有关实际占用物理内存方面(rss)
http://bbs.csdn.net/topics/390831818
分页机制的理解,很值得读
http://blog.csdn.net/zhoukangli/article/details/53363275
/proc/N/maps信息是如何生成的?由于内核版本不同,实现源码也不一样,所以应该照着自己的源码看
http://blog.csdn.net/niaolianjiulin/article/details/50742532
加载内核模块,实现新的系统调用:遍历系统当前所有进程的任务描述符,并将pid组织成树状结构显示
https://www.cnblogs.com/hazir/p/linux_kernel_pid.html
讲解Linux命名空间,讲的很详细,很好
代码github地址:点击打开链接