生成对抗网络(GAN)的理论与应用完整入门介绍
本文包含以下内容:
1.为什么生成模型值得研究
2.生成模型的分类
3.GAN相对于其他生成模型相比有什么优势
4.GAN基本模型
5.改进的GANs
6.GAN有哪些应用
7.GAN的前沿研究
一、为什么生成模型值得研究
主要基于以下几个原因:
1. 从生成模型中训练和采样数据能很好的测试我们表示和操作高维概率分布的能力。而这种能力在数学和工程方面都有广泛的应用。
2. 生成模型可以通过很多方式应用到强化学习中。强化学习算法一般分为两类:基于模型的(包含生成模型)和与模型无关的。时间序列生成模型可以模拟将来的很多种可能。比如,可以学习一个条件概率分布模型,把当前时刻的状态和假设的动作作为输入,用生成模型来产生未来的状态。通过输入可能的动作,生成并预测。另一种结合强化学习的方式是生成假想的环境进行测试,这样可以不用在真实环境下测试,从而造成损失。
3. 生成模型还可以填补缺失信息。特别是在半监督学习中的应用,由于真实环境下,很少有带标注的信息,而且标注信息往往依靠高成本的人工标注。生成模型,特别是GANs,能够在很少标注样本的情况下,提高半监督学习算法的泛化能力。同时,给定一张二维图片,可以通过生成模型来填补更多的图像信息,生成可能的三维图像。
4. 生成模型,可以使机器学习利用混合多模型进行输出。对于很多任务而言,对一个输入而言,可映射到多个正确输出。很多传统的机器学算法,如最小化均方误差算法,无法训练模型来产生多个正确的输出。比如预测视频的下一帧。
5. 最后,很多任务本质上是需要从多种分布中产生真实的样本。如单张图片的超分辨率任务,需要给低分辨率的图像填补缺失信息合成高分辨率图像。相对于GAN,其他生成模型往往对多种可能的生成图像进行平均,从在造成图像模糊。而GAN,则会生成多个可能的清晰图像,从而增加了其多样性——虽然GAN也存在模式塌陷(modecollapse)问题,即多个输入映射到一个输出上。最新的一些研究可以利用GANs,通过用户想象的粗略描述来生成相关的真实图片。图像到图像的“翻译”,可以把框架图或素描来转换成真实的图片——虽然这个任务的难度比较大,还是很有前景的,值得去探索的。
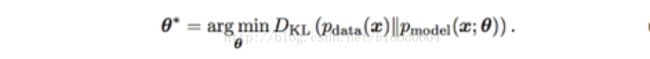
二、生成模型
1. 最大似然估计。通过一个带有参数的模型来估计概率分布,并在训练数据上选择使似然函数(一般的使用log函数)最大化的参数。GAN基本模型中,最大化似然函数等价于最小化KL散度——用来度量两个概率之间的“距离”。
2. 深度生成模型的分类:参数的概率分布、非参数的概率分布

FVBN、GAN、VAE这三种是目前最流行的生成模型方法。
1) 参数的概率密度函数模型(即预先假设服从某种分布)
i. 全可视化置信网络:
采用概率的链式规则分解概率分布,将n维向量的输入分解为一维的概率分布。缺点是,必须依顺序生成样本(先x1,然后x2...),不能并行化计算,也没法进行交互,计算耗时(如,需要两分钟的计算才能生成一秒的语音数据)。
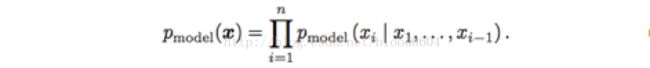
ii. 非线性独立成分分析:
假设存在一个连续、可导、可逆的函数g,将隐变量z映射到样本空间x,那么x的概率分布与z的概率分布就建立了如下联系

该方法的主要缺点是,函数g需要精确地设计,以满足连续、可导、可逆的要求。同时,可逆也要求隐变量z与x有相同的维数。而GAN对函数g的限制很少,也不要求x与z有相同的维数。FVBN、VAE等模型簇的优点是,由于概率密度是清晰表述的,从而利用最大似然估计进行计算也很高效。也有一些模型利用清晰表述的概率密度函数,但是需要近似(采用变分方法的判别式近似,采用马尔科夫链-蒙特卡洛方法的随机近似)。变分方法近似用一个函数L逼近log似然函数的下确界,由于两个函数之间总是存在间隙或无法完美逼近,同时,也没有一个好的方法来评估图像的质量,因此,变分方法(如VAE)产生的图片比较模糊。马尔科夫链通过不断重复x’~q(x’|x)这个过程来生成样本,最终收敛到模型中样本。但收敛过程比较慢,也不确定何时收敛。玻尔兹曼机往往采用这种方法进行生成样本,由于其基于马尔科夫链技术,且没法扩展到像ImageNet图片生成这种问题中,现在来说,玻尔兹曼机的应用相对较少。
2)非参数的概率密度函数模型
i. 生成随机网络:
基于真实数据模型的采样,由于也采用马尔科夫链转换操作,因此,很难扩展到高维数据,并且计算成本比较高。
ii. 生成对抗网络
基于极小极大博弈而设计的对抗网络框架,包括生成器和判别器。生成器(如采用MLP网络表示生成函数)可以生成伪造的样本,与真实样本同时输入判别器(如采用MLP网络),判别器根据伪造样本(g(z),0)和真实样本(x,1)最大化判别真假的概率。生成器最大化判别器无法判别的概率,即最小化伪造样本的概率分布与真实数据的概率分布之间的“距离”。
生成器G可以用深度神经网络来表示生成函数,而且限制仅限于可微。输入数据z可以从任意的分布中采样,G的输入也无需与深度网络的第一层输入一致(例如,可以将输入z分为两部分:z1和z2,分别作为第一层和最后一层的输入,如果z2服从高斯分布,那么(x | z1)服从条件高斯分布)。但z的维数要至少与x的维数一致,才能保证z撑满整个x样本空间。G的网络模型也不受任何限制,可以采用多层感知机、卷积网络、自编码器等。因此,GAN对生成器的限制很少。
判别器D的输入为G的输出(G(z),0)和真实样本(x,1)——其中,0表示fake,1表示real。判别器网络可以采用任意的二元分类器,训练过程为典型的监督式学习。输出为一个标量值,表示伪造的输入G(z)为真实样本的概率,当达到0.5时,说明判别器无法区分真实样本和伪造样本,即极小极大博弈达到了纳什均衡,或者训练过程已收敛。那么生成器就是我们需要的生成模型,给定先验分布,输出“真实”的样本。
三、GAN相对于其他生成模型相比有什么优势
1. 相对于FVBN生成时间与x的维度成正比,GAN可以一次性生成样本
2. 相对于BNs只有很少的概率分布可以使用马尔科夫链计算,非线性独立成分分析要求隐变量与x有相同的维数,GAN对生成函数只有很少的限制
3. GAN框架中不需要变分约束,可用的具体模型族已经被称为通用近似,所以GAN已经被认为是渐近一致的。一些VAE被推测为渐近一致,但这还没有被证明。两者最大的不同是,如果采用标准BP算法,VAE不能采用离散变量作为生成器的输入,而GAN的生成器不能产生离散变量的输出。
4. 实际应用中,GAN相对于其他模型生成了质量更高的图像
四、GAN基本模型(引用GoodFellow 2014-06)
生成对抗网络是一种框架,通过对抗过程,通过训练生成器G和判别器D。两者进行一个极小极大(minmax)的博弈,最终达到纳什均衡,即判别器无法区分样本是来自生成器伪造的样本还是真实样本。以往的深度生成模型需要马尔科夫链或近似极大似然估计,产生很多难以计算的概率问题。为避免这些问题而提出了GAN框架,训练过程采用成熟的BP算法即可。
基本模型:
1) 生成器G:输入“噪声”z(z服从一个人为选取的先验概率分布,如均匀分布、高斯分布等)。采用多层感知机的网络结构,用MLP的参数来表示可导映射G(z:),将输入空间映射到样本空间。G为可微函数。
2) 判别器D:输入为真实样本x和伪造样本D(z),并分别带有标签real和fake。判别器网络可以用带有参数多层感知机表示D(x;)。输出为D(x),表示来自真实样本数据的概率。
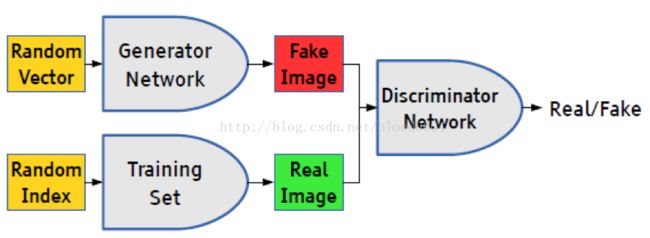
优化目标:
生成器G和判别器D在极小极大博弈(非凸优化)中扮演了两个竞争对手的角色,用下列值函数V(G,D)来表示:
![]()
优化过程:
1) 训练初期,当G的生成效果很差时,D会以高置信度来拒绝生成样本,因为它们与训练数据明显不同。因此,log(1−D(G(z)))饱和(即为常数,梯度为0)。因此我们选择最大化logD(G(z))而不是最小化log(1−D(G(z)))来训练G。
2) 在训练的内部循环中完成优化D是计算上不可行的,并且有限的数据集将导致过拟合。作为替代方法,我们在优化D的k个步骤和优化G的一个步骤之间交替更新。只要G变化足够慢,可以保证D保持在其最佳解附近。
3) 当pg=pdata时,到达全局最优(鞍点)
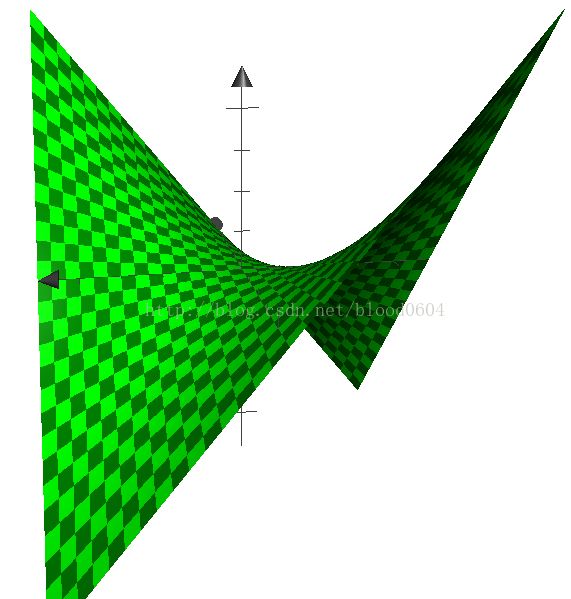
4) 当D达到局部最优时,优化G近似的等价于最小化JS散度
5) pg最终收敛到pdata

一维情况举例:

z为从均匀分布中采样的噪声,x为生成的样本,z-x为生成器G的映射G(z)。圆点虚线为真实样本所服从的正态分布,实线为生成器所学习到的分布,点画线为分类边界(即判别器对真实和伪造样本分类的概率)。从(a)到(d)噪声服从的均匀分布逐渐映射为正态分布,并随着两个分布之间的“距离”——JS散度的不断减小,最终学习到真实样本的分布,从而判别器无法区分真实样本和伪造样本。当训练完成后,生成器会学习到将均匀分布映射为正态的的映射函数。整个过程没有用到标签信息,因而是无监督的学习。
五、改进的GANs(以时间为顺序)
1. CGAN(Conditional GenerativeAdversarial Net 2014-11)
在无条件生成模型中,对生成数据的模型是没有任何限制的。CGAN可以通过添加额外的信息y来指导数据生成的过程。将y作为一个额外的输入层,输入生成器D和判别器G。比如,y可以是one-hot编码的类标签。
![]()
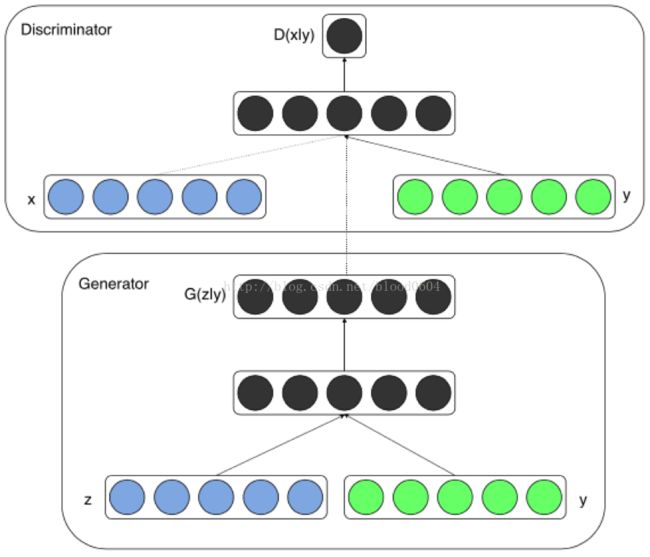
2. LAPGAN(Deep Generative Image Modelsusing a Laplacian Pyramid of Adversarial Networks 2015-06)
LAPGAN利用了CGAN,将图像作为条件同时作为判别器和生成器的输入部分,同时采用拉普拉斯金字塔模型,不再一次性生成整个图片,而是逐层生成整张图片的每一部分。金字塔的每一层都采用GAN模型,并输出一个样本为真的概率值。实际上每一层都学习图像的L2损失,将图像先经过下采样(即将图片缩小为原来的1/2的尺寸,例如直接去掉偶数的行和列的像素点),再经过上采样(即将图片扩大为原来的2倍,例如用奇数的行和列的像素点填充偶数行列),作为条件分别输入生成器、与真实图像相减输入判别器、直接输入判别器,从而每一层学习的是残差损失。
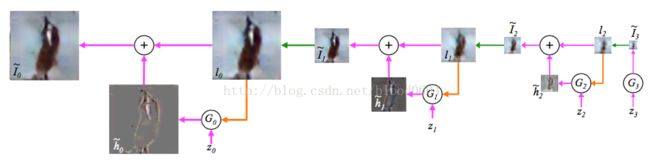
采样过程
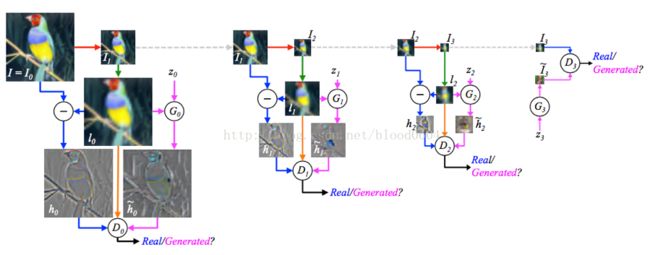
训练过程
3. CatGAN(Unsupervised and Semi-supervised Learning withCategorical Generative Adversarial Networks 2015-11)
CatGAN的主要目的是采用GAN进行半监督或无监督聚类问题。通常聚类问题分为两类:1)生成式聚类方法,明确的对样本分布p(x)进行建模,如高斯混合模型、k-means、密度估计算法;2)判别式的聚类方法,没有明确对样本分布p(x)进行建模,直接通过一些分类机制,将无标签的样本划分到某个类别下,如最大边界聚类(MMC)、正则信息最大化等。
CatGAN试图将以上两种方法混合,判别器用户最大化输入样本与标签的互信息,而生成器试图用虚假的输入样本骗过判别器。
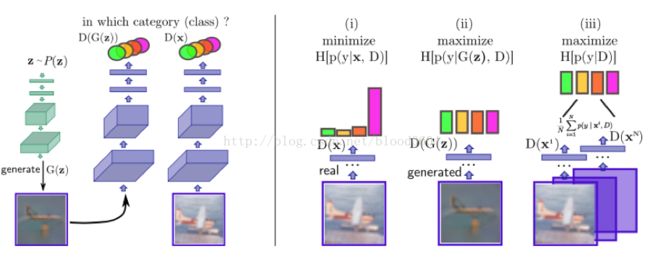
判别器:1)应该确定来自真实样本的类别;2)不确定来自生成器的样本分类;3)均等的使用所有的类别(假设噪声是采样与均匀分布)
生成器:1)生成高度确定类别的样本;2)在所有K个类别中平均分配样本
目标函数:
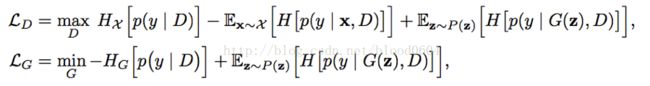
4. DCGAN(Deep Convolutional GenerativeAdversarial Net 2015-11)
DCGAN采用的卷积或类逆卷积架构,实际上已经成为GAN的标准架构,在之后的几乎所有改进中,都采用的是这种卷积架构。
1) 论文贡献:
· 为CNN的网络拓扑结构设置了一系列的限制来使得它可以稳定的训练。
· 使用得到的特征表示来进行图像分类,得到比较好的效果来验证生成的图像特征表示的表达能力
· 对GAN学习到的filter进行了定性的分析。
· 展示了生成的特征表示的向量计算特性。
2) 模型结构
· 将池化层用卷积层替代,其中,在判别器上用带步长的卷积替代,在生成器上用小步幅卷积替代。
· 在生成器和判别器上都使用批量归一化
o 解决初始化差的问题
o 帮助梯度传播到每一层
o 防止生成器把所有的样本都收敛到同一个点。
o 直接将批量归一化应用到所有层会导致样本震荡和模型不稳定,通过在生成器输出层和判别器输入层不采用BN可以防止这种现象。
· 移除全连接层
o 全局池化增加了模型的稳定性,但降低了收敛速度。
· 在生成器的除了输出层外的所有层使用ReLU,输出层采用tanh。
· 在判别器的所有层上使用LeakyReLU。
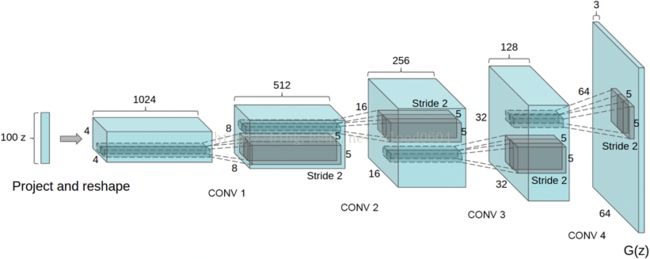
生成器网络
5. VAE-GAN(Autoencoding beyond pixels using a learned similaritymetric 2015-12)

VAE-GAN仍然是以生成高质量图片为目的。将生成器用VAE(变分自编码器)的解码器代替,判别器用来度量样本的相似性。利用判别器学好的表征作为VAE重建目标的基础,以更好度量数据空间的相似性。并用特征级别的损失来代替元素级别的损失(如像素的L2损失)以更好的学习数据分布。p(z)为从标准正态分布采样的输入噪声,当训练结束,VAE的解码部分将噪声映射为真实图片。VAE-GAN充分利用了深度神经网络可以学习到高级表征的特点,可以视为学习到的图像内容,可以视为学习到的图像风格。
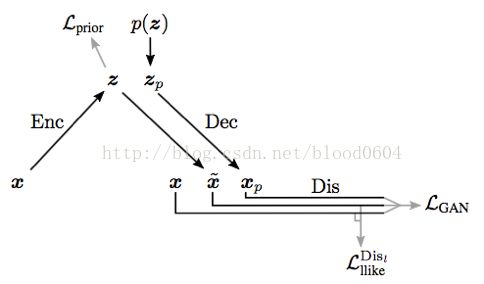

6. BiGAN(Adversarialfeature learning 2016-05)
BiGAN采用双向GAN学习逆映射——将数据投影到潜在空间中,所得到的学习特征表示对于辅助监督的辨别任务是有用的。生成器G将噪声映射为伪造的样本,而编码器E将真实样本映射到隐变量空间。编码器E和生成器G必须学会相互反转以骗过判别器D。BiGAN能够在给定样本x的情况下学习特征z,那么训练好的编码器E就能作为一个有用的特征表示用于相关语义特征的任务。同样,当给定图像时,用于预测语义“标签”的完全无监督学习的视觉模型,可以作为强大特征表征用于相关的视觉任务。隐藏特征空间中的z就可以作为样本在隐藏空间中的“标签”。

7. CoGAN(CoupledGenerative Adversarial Networks
CoGAN是为了学习多域图像的联合概率分布,例如图像的颜色和深度的联合分布。
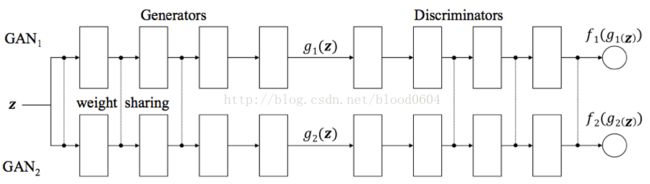
该网络包括一对GAN:GAN1、GAN2。每个GAN都有一个生成器用来在一个域中合成图像,判别器用来分辨图像真假。通过对网络增加权值共享的限制——两个生成器的前几层共享权值(负责解码高级语义特征),两个判别器的最后几层(负责编码高级语义特征)。训练好的CoGAN可以用来合成一对相似的图像——共享相同高级抽象但具有不同低级实现的图像对。
8. InfoGAN(InterpretableRepresentation Learning by Information Maximizing Generative Adversarial Nets2016-06)
通过互信息(I(x;y) = H(x) - H(x | y))最大化的GAN解释表征学习。原始的GAN模型生成器以一种高度纠缠的方式使用噪声输入,噪声的每个单独的维度与生成的数据没有语义关系。比如z中的哪些维度对应于光照变化或哪些维度对应于pose变化是不明确的。而infoGAN不仅能对这些对应关系建模,同时可以通过控制相应维度的变量来达到相应的变化,比如光照的变化或pose的变化。
噪声输入分为两部分:1)不可压缩的噪声源z;2)针对数据语义特征的隐变量噪声c。那么生成器的输入就变为了G(z,c)。带有互信息正则化的目标函数变为:
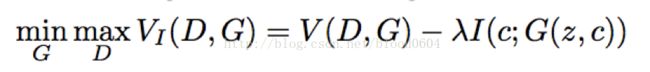
9. EBGAN(Energy-based GenerativeAdversarial Network 2016-09)
基于能量的生成对抗网络,将判别器视为一个能量函数,在真实数据的流形附近具有较低的能量值,其它区域则有较高的能量值。基于能量的模型本质上,是构建一个函数,将输入空间中的每一个点映射为一个标量值——即“能量”。生成器作为一个参数函数,生成的样本尽量被分配给低的能量值。判别器采用自编码器,并将重构误差作为能量值。
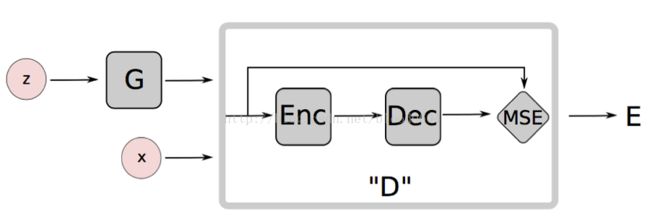
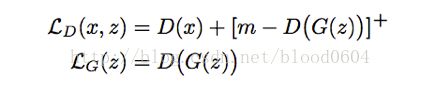 [·]+为max(0,·)函数
[·]+为max(0,·)函数
判别器:

生成器:
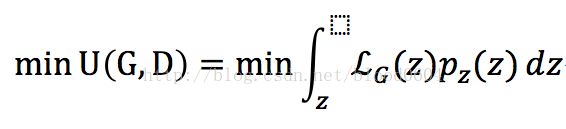
10. WGAN(WassersteinGAN 2017-01)
WGAN引入了一种新的度量分布之间的“距离”——Wasserstein 距离,又叫地动距离或EM距离,从理论上基本解决了GAN训练不稳定的问题。同时也指出梯度消失问题是由于原损失函数中log函数导致的。由于之前的GAN没有衡量图像质量的方法,WGAN的损失同时可以评价图像的质量。该论文对GAN的理论改进具有极其重要的意义。
WGAN的提出分为两篇论文,在该论文之前的一篇论文——《TOWARDS PRINCIPLED METHODS FOR TRAINING GENERATIVEADVERSARIAL NETWORKS》——从理论上彻底分析了GAN训练存在的不稳定问题,并提出了一种临时方案,即在真假样本进入判别器前,对伪造样本添加少量的噪声。
在此之前的GAN模型都采用JS散度来衡量两个分布——真实样本的分布、伪造样本的分布——之间的“距离”,但JS散度或KL散度在两个分布没有交集的情况下是没有定义的,也就是无穷值。然而,样本的分布都处于高维空间的低维流形上,大多数情况下,两个流形以1的概率具有零测度的交集——如两个二维空间的一维流形,即平面中的两条曲线,平面中的两条任意曲线,仅有有限个交点,相对于无限长的曲线其长度可忽略,即测度为零。也就是原文中所描述的——模型的流形和真实分布的流形不太可能有不可忽略的支撑集,也就意味着KL散度是没有定义的,因此,用JS/KL散度来衡量两个分布之间的“距离”是不合适的。那么,增加噪声可以使两个分布之间具有交集,这也是机器学习中生成模型都具有噪声项的原因。最典型的做法是添加较大宽度的高斯噪声,但却使生成的图像变得模糊。同时,一般情况下,图像的像素值要被归一化的(0,1)范围内,在这种情况中,增加N(0,1)高斯噪声产生的影响会远远大于图像本身的影响。
基于对不同的距离度量之间的比较,该论文提出采用EM距离来衡量不同分布之间的“距离”。
W距离或EM距离:
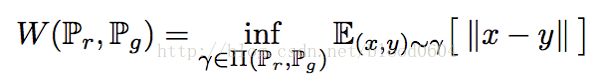
是联合分布集合中的一个元素,其中的边缘分布为。
由于EM距离无法直接计算下确界(inf),因此需要根据Kantorovich-Rubinstein对偶问题求解。
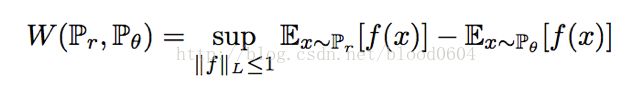
为1阶Lipschitz连续的条件,即函数f在整个定义域上,一阶导数的绝对值小于等于1。而f函数可以用带有参数的神经网络来表示,由于BP算法要求一阶偏导不为无穷,可以将限制条件放宽为:f函数满足K阶Lipschitz条件。在实际操作中,可以对神经网络的参数w进行裁剪,即限制在[-c,c]范围内。因此判别器的优化问题转化为最大化两个分布之间的EM距离,即:
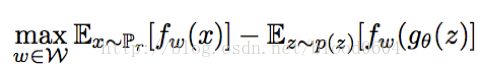
其中,为带有参数w的判别器网络,为带有参数的生成器网络。判别器要最大化参数w以最大化EM距离。对参数w的裁剪是为满足Lipschitz条件而强加的限制,而如果裁剪的范围过大,判别器很难训练达到最优;如果裁剪的范围过小,那么很容易导致梯度消失。

11. BEGAN(Boundary EquilibriumGenerative Adversarial Networks)
结合WGAN,提出了一种新的均衡方法,用于训练自编码器。这种方法用户平衡生成器和判别器,并且提供了一种新的近似度量收敛的方法,训练更加快速、稳定,图像质量更高。同时,还可以平衡生成图像的多样性和图像质量。
本文的贡献:
1) 简单鲁棒性很好的架构,标准的训练方法,快速稳定的收敛
2) 一种平衡的概念——用于平衡生成器和判别器的能力
3) 一种新的方式——平衡图像的多样性和图像质量
4) 近似的度量收敛,全局损失在一定程度上能够衡量图像质量
DCGAN利用卷积神经网络首先提高了图像质量。EBGAN将判别器视为一种能量函数。这个变体收敛稳定、容易训练,并且对超参数具有很好的鲁棒性。EBGAN同样将其鉴别器实现为具有每像素误差的自动编码器。WGAN提出了Wasserstein距离作为损失函数,同时也可以衡量收敛性,虽然收敛性很好、训练稳定,但是训练缓慢。
BEGAN用自编码器作为判别器。典型的GAN直接匹配数据分布,而BEGAN用W距离导出的损失来匹配自编码器的损失分布。
首先,图像经过自编码器的L1损失近似于正态分布。基于这个假设,BEGAN模型用W距离衡量两个正态分布之间的距离。判别器D最大化两个分布的距离,而生成器G最小化两个分布之间的距离。
其次,判别器采用卷积网络构成的自编码器,并移除池化层。生成器G采用与自编码器中的解码器相同的结构。图像经过自编码器的损失采用L1范数作为损失:
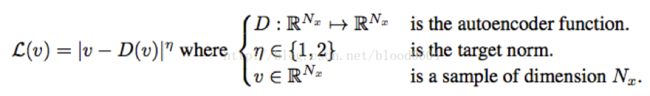
该损失为一个标量值,经过自编码器的多次迭代的损失值,服从正态分布。
两个一维正态分布之间的W距离的平方为:
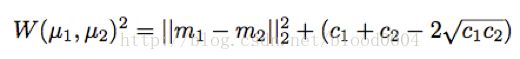
m1、m2为两个分布的均值,c1、c2为两个分布的方差。
上述方程的解为:
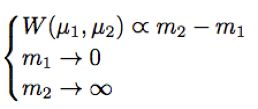
即将真实图片重构的损失均值为零,而将生成器重构图片的损失尽量大。而生成器尽量减小两个损失之间的距离,从而使判别器无法区分。
损失函数分别为:
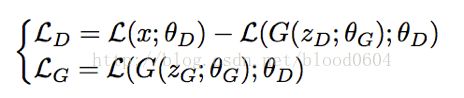
LD即为两个损失之间的负W距离。判别器最大化两个分布之间的距离,即为最小化两个分布之间的负距离。生成器最小化损失,让生成的图像尽量的重构为真实的图像。
最后,又引入一个超参数γ=L(G(z))/L(x),作为平衡多样性和图像清晰度的比例系数。同时,加入一个可调节的系数kt,用负反馈系统调节生成器和判别器之间的能力。由于,开始训练时,真实图像经过自编码器的损失较大,判别器很容易区分真实图像和生成的图像。初始时,kt=0,最小化LD相当于让判别器专注于自编码任务。同时,由于刚开始训练时,真实图像经过自编码器的值较大,,kt的值逐渐增大,LD中的比例逐渐增大。当真实图像重构的比较好时,判别器更多的关注拉近两个分布之间的距离,同时,kt逐渐减小,直到γL(x)-L(G(z))=0。
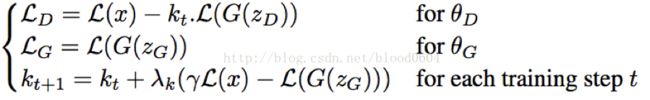
实验中发现,BEGAN收敛比较缓慢。
六、GAN有哪些应用
1. 图像生成
图像生成是生成模型的基本问题,GAN相对先前的生成模型能够生成更高图像质量的图像。

2. 高分辨率图像生成(PPGN、BEGAN、BEGAN等)

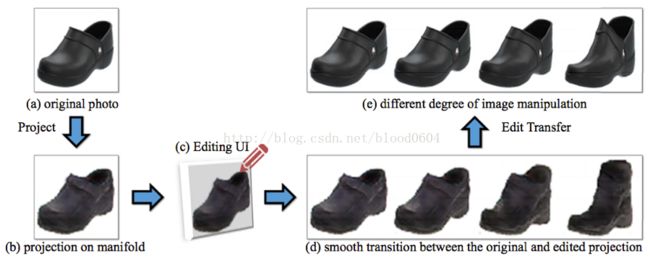
3. 交互式图像生成(iGANhttps://research.adobe.com/project/igan/)
4. 超分辨率(SRGAN)——如将32*32的图像扩展为64*64的真实图像

5. 合成场景渲染(S2GAN)

6. 图像修复(ContextEncoders: Feature Learning by Inpainting)

7. 视频生成(http://carlvondrick.com/tinyvideo/)
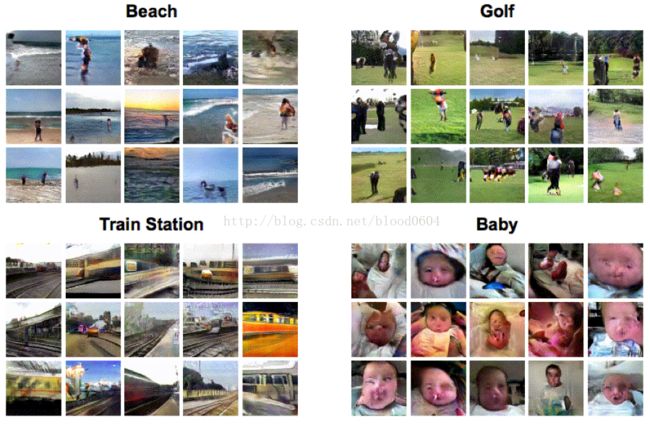
8. 根据文本生成图像(StackGAN)

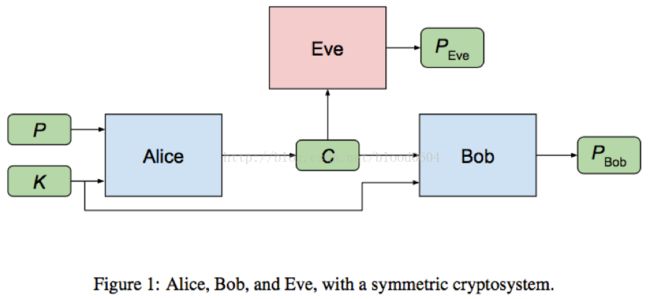
9. 通信加密(Learningto protect communications with adversarial neural cryptography)
10. 2D-3D模型重建(3D-GAN)

11.信息检索(IRGAN——SIGIR2017的满分论文——2017.5.30)
七、GAN的前沿研究
1. 不收敛问题
由于GAN是采用极小极大博弈,在进行梯度下降时,有可能会出现D的梯度使得在损失流形上下降,而G使其上升,造成两者的梯度相互抵消,最终在最优点附近徘徊。因此,不收敛问题也是GAN所面临的最大的问题。目前采用的优化方法都是采用的启发式的方法。WGAN也在一定程度上解决了收敛不稳定的问题。
2. Mode Collapse
模式崩溃问题也可以理解为多样性问题,即G将所有噪声输入都映射到一个输出。例如,当G生成了一张比较真实的图像后,就不再学习其他分布情况,而仅靠这一张图像欺骗D。
第一行是要学习的混合高斯分布,第二行是不同步数时G学习到的分布情况。随着步数的不断增加,G学到的并不是包括所有分布的情况,而是仅收敛到一种模式。该问题也是GAN所面临的一个重要问题。目前仍没有得到很好的解决。
3. 离散输出
GAN对生成器的唯一要求就是——生成器表示的函数必须可导,因此,GAN似乎无法用于离散输出。目前,仍未有将GAN应用于NLP领域。目前可能解决该问题三个可能的方向:
a) 采用强化学习算法
b) 采用具体的分布(ConcreteDistribution)
c) 训练生成器产生连续的输出值,并将其编码为离散值
4. 半监督学习
目前将GAN扩展到半监督领域的尝试——CatGAN,是比较好的开始。还有一种基本思想是:将n个类别扩展到n+1个类别,附加类为图像为假的类。判别器作为一个分类器,所有的n个类为真实的图像的类别,并总体输出一个图像为真的概率。分类器(即判别器)可以被完全无监督的进行训练,也可以用有限的带标签样本进行训练(In Advances in Neural Information Processing Systems、Semi-supervised learning with generative adversarial net-works)。
5. 强化学习
目前已经有研究确认了GAN与强化学习中的actor-critic方法(Connectinggenerative adversarial networks and actor-critic methods)、逆向强化学习(A connection between generative adversarial networks,inverse reinforcement learning, and energy-based models)建立了联系,并且将GAN用于了模仿学习(Generativeadversarial imitation learning)。进一步将GAN与RL的工作有待进一步研究。
https://github.com/hindupuravinash/the-gan-zoo
这是GitHub上整理好的论文列表,相对于其他的论文整理,个人认为其好的一点是——按照时间顺序来整理的,能够更清楚的看到GAN的发展过程。