MyBatis的延迟加载和缓存
文章目录
- 1. MyBatis 的延迟加载策略
- 1.1 提出问题
- 1.2 延迟加载
- 1.3 立即加载
- 1.4 采用延迟加载和立即加载的情况
- 1.5 一对一实现延迟加载
- 1.5.1 说明
- 1.5.2 需求
- 1.5.3 实现
- 1.5.4 总结
- 1.6 一对多实现延迟加载
- 1.6.1 需求
- 1.6.2 实现
- 1.6.3 总结
- 2. MyBatis 的缓存
- 2.1 缓存的概念
- 2.2 缓存的作用
- 2.3 适用缓存的数据和不适用缓存的数据
- 2.4 MyBatis 的一级缓存
- 2.4.1 一级缓存的概念
- 2.4.2 证明一级缓存的存在
- 2.4.3 触发清空一级缓存的情况
- 2.5 MyBatis 的二级缓存
- 2.5.1 二级缓存的概念
- 2.5.2 二级缓存的结构图
- 2.5.3 二级缓存的使用步骤
- 2.5.4 二级缓存的注意事项
1. MyBatis 的延迟加载策略
1.1 提出问题
假设我们有一个用户,它有 100 个账户(用户和账户的关系是一对多)
-
在查询用户的时候,要不要把关联的账户都查出来?
如果把关联的 100 个账户都查出来,无疑会对内存造成很大的开销。所以在查询用户时,用户下的账户信息应该是什么时候使用,什么时候查询
-
在查询账户的时候,要不要把关联的用户查出来?
如果把关联的用户查出来,也只有一个,并不消耗很大内存。所有在查询账户时,账户所属的用户信息应该是随着账户查询时一起查询出来
1.2 延迟加载
-
延迟加载的概念
在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载。
-
延迟加载的好处
先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度快。
-
延迟加载的坏处
因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,由于查询工作也要消耗时间,所以可能让用户等待时间变长,造成用户体验下降。
1.3 立即加载
不管用不用数据,只要一调用方法,马上发起查询
1.4 采用延迟加载和立即加载的情况
- 一对多,多对多:通常情况下,我们都是采用延迟加载
- 多对一,一对一:通常情况下,我们都是采用立即加载
1.5 一对一实现延迟加载
1.5.1 说明
mybatis 在实现多表操作时,我们使用了 resultMap 来实现一对一,一对多,多对多关系的操作。主要是通过 association、collection 实现一对一及一对多映射,association、collection 具备延迟加载功能。
1.5.2 需求
查询所有账户信息,同时查询所属用户信息
1.5.3 实现
-
账户实体类
public class Account { private Integer id; private Integer uid; private Double money; // 从表实体应该包含一个主表实体的对象引用 private User user; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public Integer getUid() { return uid; } public void setUid(Integer uid) { this.uid = uid; } public Double getMoney() { return money; } public void setMoney(Double money) { this.money = money; } public User getUser() { return user; } public void setUser(User user) { this.user = user; } @Override public String toString() { return "Account{" + "id=" + id + ", uid=" + uid + ", money=" + money + ", user=" + user + '}'; } } -
账户 Dao
/** * 账户持久层接口 */ public interface AccountDao { /** * 查询所有账户信息,同时查询所属用户信息 * @return */ public List<Account> findAllWithUser(); } -
账户持久层配置文件
<mapper namespace="com.zt.dao.AccountDao"> <resultMap id="accountUserMap" type="account"> <id property="id" column="id">id> <result property="uid" column="uid">result> <result property="money" column="money">result> <association property="user" javaType="user" select="com.zt.dao.UserDao.findById" column="uid"> association> resultMap> <select id="findAllWithUser" resultMap="accountUserMap"> select * from account select> mapper>注意:
- select:填写我们要调用的 select 映射的 id
- column:填写我们要传递给 select 映射的参数
-
开启 Mybatis 的延迟加载策略
在 Mybatis 的配置文件 SqlMapConfig.xml 文件中添加延迟加载的配置:
<settings> <setting name="lazyLoadingEnabled" value="true"/> settings> -
编写测试只查账户信息不查用户信息
@Test public void testFindAllWithUser() { List<Account> allWithUser = mapper.findAllWithUser(); } -
打印结果
[ main] DEBUG dao.AccountDao.findAllWithUser - ==> Preparing: select * from account [ main] DEBUG dao.AccountDao.findAllWithUser - ==> Parameters: [ main] DEBUG dao.AccountDao.findAllWithUser - <== Total: 3
1.5.4 总结
我们发现,因为本次只是将 Account 对象查询出来放入 List 集合中,并没有涉及到 User 对象,所以就没有发出 SQL 语句查询账户所关联的 User 对象的查询。
1.6 一对多实现延迟加载
1.6.1 需求
查询所有用户,同时包含用户下的所有账户信息
1.6.2 实现
-
用户实体类
public class User implements Serializable { private Integer id; private String username; private Date birthday; private String sex; private String address; // 一对多关系映射:主表实体应该包含从表实体的集合引用 private List<Account> accounts; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public Date getBirthday() { return birthday; } public void setBirthday(Date birthday) { this.birthday = birthday; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } public List<Account> getAccounts() { return accounts; } public void setAccounts(List<Account> accounts) { this.accounts = accounts; } @Override public String toString() { return "User{" + "id=" + id + ", username='" + username + '\'' + ", birthday=" + birthday + ", sex='" + sex + '\'' + ", address='" + address + '\'' + ", accounts=" + accounts + '}'; } } -
用户 Dao
/** * 用户持久层接口 */ public interface UserDao { /** * 查询所有用户,同时包含用户下的所有账户信息 * @return */ public List<User> findAllWithAccount(); } -
用户持久层配置文件
<mapper namespace="com.zt.dao.UserDao"> <resultMap id="UserAccountMap" type="user"> <id property="id" column="id">id> <result property="username" column="username">result> <result property="birthday" column="birthday">result> <result property="sex" column="sex">result> <result property="address" column="address">result> <collection property="accounts" ofType="account" select="com.zt.dao.AccountDao.findById" column="id"> collection> resultMap> <select id="findAllWithAccount" resultMap="UserAccountMap"> select * from user select> mapper> -
开启 Mybatis 的延迟加载策略
在 Mybatis 的配置文件 SqlMapConfig.xml 文件中添加延迟加载的配置:
<settings> <setting name="lazyLoadingEnabled" value="true"/> settings> -
编写测试只加载用户信息
@Test public void testFindAllWithAccount() { List<User> allWithAccount = mapper.findAllWithAccount(); } -
打印结果
[ main] DEBUG ansaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@710726a3] [ main] DEBUG dao.UserDao.findAllWithAccount - ==> Preparing: select * from user [ main] DEBUG dao.UserDao.findAllWithAccount - ==> Parameters: [ main] DEBUG dao.UserDao.findAllWithAccount - <== Total: 7
1.6.3 总结
我们发现,因为本次只是将 User 对象查询出来放入 List 集合中,并没有涉及到 Account 对象,所以就没有发出 SQL 语句查询所关联的 Account 账户信息。
2. MyBatis 的缓存
2.1 缓存的概念
缓存是存在于内存中的临时数据
2.2 缓存的作用
减少和数据库的交互次数,提高执行效率
2.3 适用缓存的数据和不适用缓存的数据
- 适用缓存的数据
- 经常查询并且不经常改变的数据
- 数据的正确与否对最终结果影响不大的数据
- 不适用缓存的数据
- 经常改变的数据
- 数据的正确与否对最终结果影响很大的数据(例如:商品的库存,银行的汇率,股市的牌价)
2.4 MyBatis 的一级缓存
2.4.1 一级缓存的概念
它指的是 Mybatis 中 SqlSession 对象的缓存。
当我们执行查询之后,查询的结果会同时存入到 SqlSession 为我们提供一块区域中。该区域的结构是一个 Map,当我们再次查询同样的数据,mybatis 会先去 SqlSession 中查询是否有,有的话直接拿出来用。
2.4.2 证明一级缓存的存在
-
用户实体类
public class User implements Serializable { private Integer id; private String username; private Date birthday; private String sex; private String address; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public Date getBirthday() { return birthday; } public void setBirthday(Date birthday) { this.birthday = birthday; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } } -
用户 Dao
/** * 用户持久层接口 */ public interface UserDao { /** * 查询单个用户 * @param id */ User findById(Integer id); } -
用户持久层映射文件
<mapper namespace="com.zt.dao.UserDao"> <select id="findById" parameterType="java.lang.Integer" resultType="user"> select * from user where id=#{id}; select> mapper> -
测试类
@Test public void testFindById() { User user1 = mapper.findById(52); System.out.println(user1); User user2 = mapper.findById(52); System.out.println(user2); System.out.println(user1 == user2); } -
打印结果
[ main]DEBUG com.zt.dao.UserDao.findById - ==> Preparing: select * from user where id=?; [ main]DEBUG com.zt.dao.UserDao.findById - ==> Parameters: 52(Integer) [ main]DEBUG com.zt.dao.UserDao.findById - <== Total: 1 com.zt.domain.User@24b1d79b com.zt.domain.User@24b1d79b true -
结论
我们可以发现,虽然在上面的代码中我们查询了两次,但最后只执行了一次数据库操作,这就是 Mybatis 提供给我们的一级缓存在起作用了。因为一级缓存的存在,导致第二次查询 id 为 52 的记录时,并没有发出 sql 语句从数据库中查询数据,而是从一级缓存中查询。
2.4.3 触发清空一级缓存的情况
一级缓存是 SqlSession 范围的缓存,当调用 SqlSession 的修改,添加,删除,commit(),close(),clearCache() 等方法时,就会清空一级缓存。
2.5 MyBatis 的二级缓存
2.5.1 二级缓存的概念
它指的是 Mybatis 中 SqlSessionFactory 对象的缓存。
由同一个 SqlSessionFactory 对象创建的 SqlSession 共享其缓存。
2.5.2 二级缓存的结构图
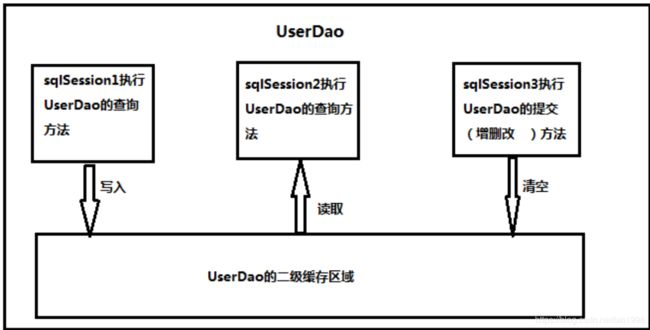
-
sqlSession1 去查询用户信息,查询到用户信息会将查询数据存储到二级缓存中。
-
sqlSession2 去查询与 sqlSession1 相同的用户信息,首先会去缓存中找是否存在数据,如果存在直接从
缓存中取出数据。
-
SqlSession3 去执行相同 mapper 映射下 sql,执行 commit 提交,将会清空该 mapper 映射下的二
级缓存区域的数据。
2.5.3 二级缓存的使用步骤
-
让 Mybatis 框架支持二级缓存(在 SqlMapConfig.xml 中配置)
<settings> <setting name="cacheEnabled" value="true"/> settings> -
让当前的映射文件支持二级缓存(在 IUserDao.xml 中配置)
<cache>cache> -
让当前的操作支持二级缓存(在 select 标签中配置)
<select id="findById" parameterType="java.lang.Integer" resultType="user" useCache="true"> select * from user where id=#{id}; select> -
测试类
/** * 测试二级缓存 */ @Test public void testFindById() { SqlSession sqlSession1 = sqlSessionFactory.openSession(); UserDao mapper1 = sqlSession1.getMapper(UserDao.class); User user1 = mapper1.findById(52); System.out.println(user1); // 一级缓存消失 sqlSession1.close(); SqlSession sqlSession2 = sqlSessionFactory.openSession(); UserDao mapper2 = sqlSession2.getMapper(UserDao.class); User user2 = mapper2.findById(52); System.out.println(user2); sqlSession1.close(); System.out.println(user1 == user2); } -
打印结果
[ main] DEBUG com.zt.dao.UserDao.findById - ==> Preparing: select * from user where id=?; [ main] DEBUG com.zt.dao.UserDao.findById - ==> Parameters: 52(Integer) [ main] DEBUG com.zt.dao.UserDao.findById - <== Total: 1 com.zt.domain.User@4b53f538 [ main] DEBUG ansaction.jdbc.JdbcTransaction - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@727803de] [ main] DEBUG ansaction.jdbc.JdbcTransaction - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@727803de] [ main] DEBUG source.pooled.PooledDataSource - Returned connection 1920467934 to pool. [ main] DEBUG com.zt.dao.UserDao - Cache Hit Ratio [com.zt.dao.UserDao]: 0.5 com.zt.domain.User@1445d7f false -
结论
经过上面的测试,我们发现执行了两次查询,并且在执行第一次查询后,我们关闭了一级缓存,再去执行第二次查询时,我们发现并没有对数据库发出 sql 语句,所以此时的数据就只能是来自于我们所说的二级缓存。但是两次的 user 对象不是同一个对象,这是因为二级缓存中存放的内容是数据,而不是对象,在使用二级缓存时会创建一个新的对象,再填充数据。
2.5.4 二级缓存的注意事项
当我们在使用二级缓存时,所缓存的实体类一定要实现 java.io.Serializable 接口,这样就可以使用序列化方式来保存对象。