问题分析报告--Hive表列属性更新慢并偶尔更新失败
1、问题描述
1.1 基本信息[Basic Information]
- 集群规模:37+3台物理机,每台128G内存;CPU:2*16C;SATA磁盘,2T*12
- hadoop社区版本:**
- 商业版本:FusionInsight_HD_V100R002C30LCN001SPC005
- MetaStore:高斯数据库(Postgresql)
1.2 问题描述[Problem Description]
- 10月16日,在执行批量任务时,alter table test change column id id int comment ‘my comment’这类语句执行比较慢,该表150多个分区, 执行需要200多s;
- 在10月13日,同样的操作,只需要10多s。
- 在执行批量任务时,alter table test change column id id int comment ‘my comment’这类语句偶现失败。
2、问题分析[Problem Analysis]
2.1 Hive表列属性偶现失败问题分析
直接在现网重现该问题,并获取日志后进行分析:
1.HiveServer在01:45:31接收到Alter table列信息的请求:
2016-10-16 01:45:31,335 | INFO | HiveServer2-Background-Pool: Thread-45308 | Starting command: alter table hw_test2 change column log_id log_id decimal(24,9) comment '日志号5' | org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1257)
2.HiveServer向10.0.11.11节点的metaStore发起客户端连接:
2016-10-16 01:45:31,336 | INFO | HiveServer2-Background-Pool: Thread-45308 | Trying to connect to metastore with URI thrift://10.0.11.11:21088 | org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:378)
3.MetaStore审计日志记录了本次alter table的请求:
2016-10-16 01:45:31,355 | INFO | pool-6-thread-187 | UserName=hdmp UserIP=10.0.11.11 Time=2016/10/16 01:45:31 Opertaion=alter_table: db=tmp tbl=hw_test2 newtbl=hw_test2
4.由于执行表的alter table操作的同时,会遍历修改该表下的所有分区的列的元数据信息,因此在分区数比较多的情况下会耗时较长。而当时HiveServer与MetaStore之间的连接超时时间设置成了10分钟,如果10分钟还没有完成一次任务执行,HiveServer会认为其MetaStore连接超时,并抛出异常,然后进行重连:
2016-10-16 01:55:31,453 | WARN | HiveServer2-Background-Pool: Thread-45308 | MetaStoreClient lost connection. Attempting to reconnect. | org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:133)
org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timed out
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:129)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:84)
5.于是HiveServer向另一个MetaStore 11.12发起了连接:
2016-10-16 01:55:32,481 | INFO | HiveServer2-Background-Pool: Thread-45308 | Trying to connect to metastore with URI thrift://10.0.11.12:21088 | org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:378)
6.连接到11.12后重试alter table的请求:
2016-10-16 01:55:32,527 | INFO | pool-6-thread-2 | UserName=hdmp UserIP=10.0.11.11 Time=2016/10/16 01:55:32 Opertaion=alter_table: db=tmp tbl=hw_test2 newtbl=hw_test2 | org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.logAuditEvent(HiveMetaStore.java:365)
7.第一次连接中,由于请求已经发送到MetaStore服务端,当客户端超时认为失败后断开,MetaStore服务端对于元数据库的修改动作仍在继续运行直到2点08分这个alter table请求执行成功:
2016-10-16 02:08:59,065 | INFO | pool-6-thread-187 | UserName=hdmp UserIP=10.0.11.11 Time=2016/10/16 02:08:59 Opertaion=alter_table result=success details=null | org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.logAuditEvent(HiveMetaStore.java:365)
8.从01:45到02:08之间,第一次发起的请求一直在更新元数据表的信息,MetaStore服务端持有了表的元数据的行锁,而01:55时,第二次发起了同样的请求,则需要等待第一次请求持有的锁释放。然而第一次的任务一直持续到02:08,因此,第二次请求到达10分钟超时时间02:05时,仍未获取到锁,任务本次请求失败,向客户端抛出失败异常。
2016-10-16 02:05:38,979 | ERROR | pool-6-thread-2 | Database access problem. Killing off this connection and all remaining connections in the connection pool. SQL State = 08006 | com.jolbox.bonecp.ConnectionHandle.markPossiblyBroken(ConnectionHandle.java:388)
2016-10-16 02:05:38,980 | ERROR | pool-6-thread-2 | Update of object "org.apache.hadoop.hive.metastore.model.MStorageDescriptor@24b03fe" using statement "UPDATE SDS SET CD_ID=? WHERE SD_ID=?" failed : org.postgresql.util.PSQLException: An I/O error occured while sending to the backend.
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:374)
对应失败的审计日志:
2016-10-16 02:05:38,983 | INFO | pool-6-thread-2 | UserName=hdmp UserIP=10.0.11.11 Time=2016/10/16 02:05:38 Opertaion=alter_table result=failed details=MetaException(message:The transaction for alter partition did not commit successfully.) | org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.logAuditEvent(HiveMetaStore.java:365)
9.进一步分析10分钟超时的产生原因,从元数据库获取到的调试信息中可以看到对应时间的锁阻塞情况,第二次01:55开始启动的请求,为需要更新Hive元数据库中的SDS表,被第一次的请求锁住了13分钟
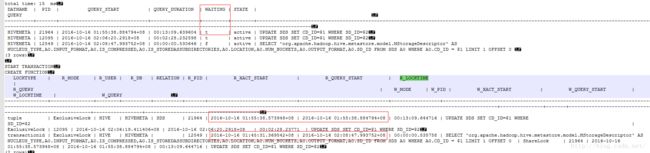
10.而第一次请求的执行时间慢的原因在于,测试表的分区数量为1072个,每个请求都需要更新保存列信息的元数据表COLUMNS_V2,而该表会通过外键关联到核心表SDS,SDS表具有大量的外键与其他表进行关联。

11.从关联关系中可以看出,在修改列信息的时候会联动更新若干元数据表的记录,其中包括元数据核心的SDS表。而针对来自CDS表的外键CD_ID没有创建索引,在联动修改过程中,需要全表扫描SDS表。
![]()
12.在当前SDS数据量达到200W以上级别的前提下,一次全表扫描耗时940ms左右,即每个分区的列信息更新操作,达到一秒左右的时间,1000个分区需要花费1000秒以上。
[2016-10-16 17:22:32.367 CST] gaussdb 12750 LOG: duration: 942.519 ms execute
2.2 Hive表列属性更新慢问题分析
直接在现网重现该问题,并获取日志后进行分析:
1.从执行的SQL语句日志分析, 在修改列信息的时候会联动更新若干元数据表的记录,其中包括元数据核心的SDS表。而针对来自CDS表的外键CD_ID没有创建索引,在联动修改过程中,需要全表扫描SDS表。
![]()
2.在当前SDS数据量达到200W以上级别的前提下,一次全表扫描耗时940ms左右,即每个分区的列信息更新操作,达到一秒左右的时间,1000个分区需要花费1000秒以上。
[2016-10-16 17:22:32.367 CST] gaussdb 12750 LOG: duration: 942.519 ms execute
3.我们模拟了数据量在有无索引情况下的性能:

同样的表,同样的数据量,在加索引前,是800多ms,跟生产环境一样, 加了索引之后,就变成0.1ms,性能提升了几百倍,因此, 性能慢的问题,判断为缺少索引导致的。
4.Alter table add comment有3三种不同表现,a是以前没有comment的,新增comment;b是已经有comment,修改成不同comment,c是已经有comment,修改成相同comment;这三种情况,b因为要插入sds,查询sds,因此耗时最长,c因为hive使用的datanucleaus组件能判断出没有发生变化,没有操作sds表,因此耗时最短
5.针对用户反馈10.13号只需要10多秒, 而近期增加的分区信息并没有那么多, 为什么性能下降这么快的问题, 将生产环境的dbservice备份数据导入测试环境中, 发现相同的表,执行alter操作需要300s左右,而在增加索引后, 变成了7s,性能提升巨大.
3、根本原因[Root Cause]
3.1 Hive表列属性偶现失败
本问题主要包括两个方面:
- HiveServer与MetaStore客户端连接超时时间未按照集群规模进行合理配置;
- 对于大数据量频繁读元数据表的情形,缺少针对性优化。
3.2 Hive表列属性更新慢
- 系统建表未建立索引为可优化点,根据内部测试,建立索引后性能有较大幅度的提升。
- 用户之前反应比较快,根据生产环境到测试环境的重建,发现执行修改comment,需要相似的时间,用户反应之前快,可能是上边分析中修改的comment前后一样导致的.
4、解决措施[Corrective Action]
4.1 Hive表列属性偶现失败
- 临时解决措施[Workaround]:将HiveServer与MetaStore连接超时时间调长,使之能满足业务场景需要,恢复业务运行。
- 最终解决措施[Solution]:为元数据中需要频繁访问的表添加索引,提升访问效率。
4.2 Hive表列属性更新慢
- 优化措施[Workaround]:针对查询慢的问题, 建议在系统空闲时对表增加索引,提升查询性能