Aritcle
-

The bath
Say sonmething

The bath
Say sonmething
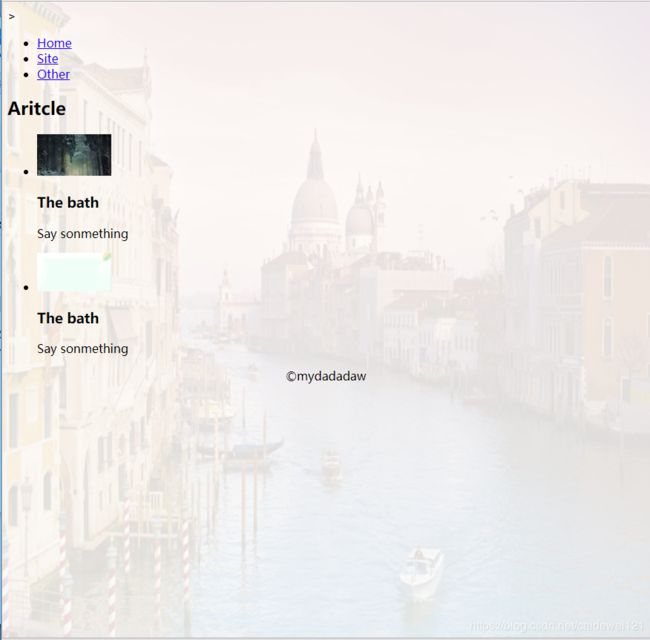
网页源代码如下
大阿瓦达
>
Say sonmething
Say sonmething
由于是静态网页,我用的是绝对路径 ,我就直接存放在桌面的目录里: C:\Users\伟\Desktop\网页作业\另一个网页作业\11.html
Soup = BeautigulSoup(html,’lxml’)
(PS:lxml为解析网页所需要的库,在python中这个库是没有的,所以我们需要进入cmd 进行自主安装“pip install lxml”,这里我会在后面在介绍另外四种解析网页库,分别是:”html parser”,”lxml HTML”, ”lxml xml”, ”html 51ib”)
资源 = Soup.select(‘???’)
Something
(网页的段落标签)tittle = Something
rate = 4.0
BeautifulSoup => CSS Select:
一个网页的基本结构
Xpath与CSS解析网页的比较
Xpath:谁,在哪,哪几个 (之后再讲)
CSS Select:谁在哪,第几个,长什么样(我们接下来的爬虫就主要用copy selector找我们需要的内容)
三、写Python代码来爬取我们写的网页
这四行代码就可以实现我们网页的爬取
from bs4 import BeautifulSoup
with open('/Users/伟/Desktop/网页作业/另一个网页作业/11.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
print(Soup)
'''
这里 第行的语句的意思是打开我们这个目录下的这个网页文件,r代表只读
'''这样就把我们整个网页的数据抓取过来了,但是结果并不是我们想要的

我们要将爬取的网页进行分析
还是点开我们写的网页,抓取我们需要的图片
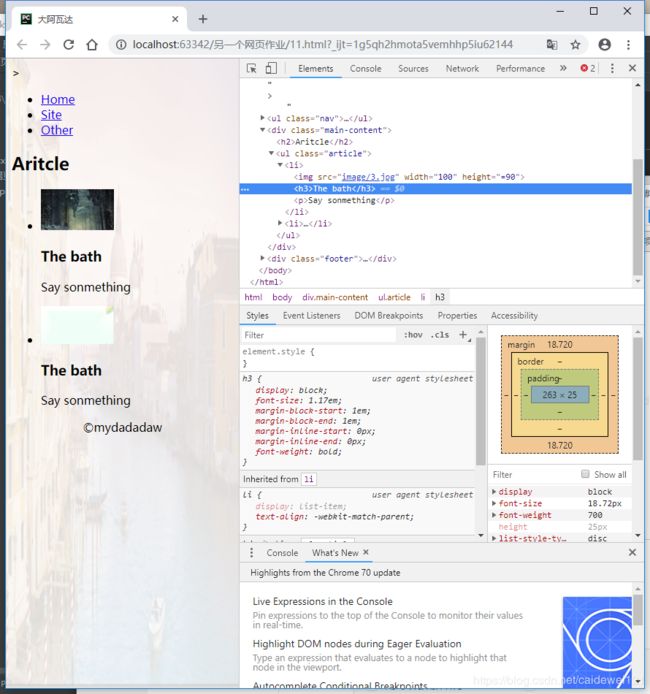
找到图片img这一行,然后右键,copy,找到,copy selector
body > div.main-content > ul > li:nth-child(1) > img,这就是我们所需要抓取的图片的代码
images = Soup.select('body > div.main-content > ul > li:nth-child(1) > img')放进pycharm(Python编辑器)中进行抓取
后面再打印我们所抓取的图片信息
print(images)但我们放进python中,它会报错,因为我们没有按照他的格式进行
![]()
因此,我们要将代码![]()

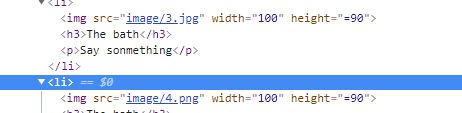
from bs4 import BeautifulSoup
with open('/Users/伟/Desktop/网页作业/另一个网页作业/11.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images = Soup.select('body > div.main-content > ul > li > img')
p = Soup.select('body > div.main-content > ul > li > p')
tittle = Soup.select('body > div.main-content > ul > li > h3')
print(images,p,tittle,sep='\n-----\n')
[, ]
-----
[Say sonmething
, Say sonmething
]
-----
[The bath
, The bath
]在代码中加上判断结构即可得到我们所需要的内容
如有补充,我会在后续加上