spark系列-应用篇之通过yarn api提交Spark任务
前言
在工作中,大部使用的都是hadoop和spark的shell命令,或者通过java或者scala编写代码。最近工作涉及到通过yarn api处理spark任务,感觉yarn的api还是挺全面的,但是调用时需要传入很多参数,而且会出现一些诡异的问题。虽然最终使用livy来提交任务,但是通过yarn api提交任务可以帮助使用者更好的理解yarn,而且使用yarn查询任务还是不错的。至于livy的安装和使用,我也会通过后面的文章分享出来。
前期准备
- 本篇的开发环境为Hadoop 2.6、Spark 2.3.1,版本有些差异也无所谓。
- 我使用的是postman来调用yarn api,你也可以使用编程语言来实现http请求。
首先启动yarn - 启动hdfs
start-hdfs.sh
4. 准备一个spark jar包,如果没有可以使用spark样例spark-examples_2.11-2.3.1.jar,并上传到hdfs上
hdfs dfs -put $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.1.jar /- 准备需要引入的spark库,打包成zip文件,并上传到hdfs上
cd $SPARK_HOME/jars
zip -q -r __spark_libs__.zip *
hdfs dfs -put __spark_libs__.zip /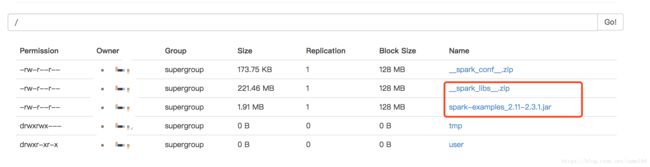
6. 启动yarn
start-yarn.sh正篇
本篇基本都是参考hadoop官方文档,有兴趣的可以阅读一下,里面有很多API接口

创建spark任务
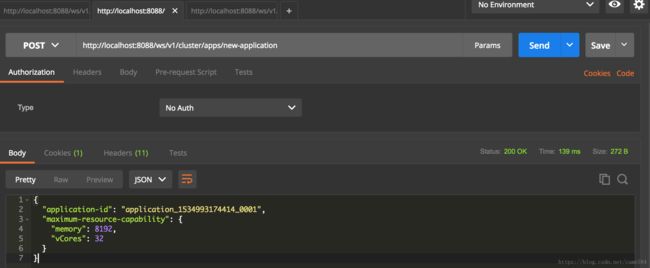
从官方文档中找到创建spark任务的api
http://localhost:8088/ws/v1/cluster/apps/new-application
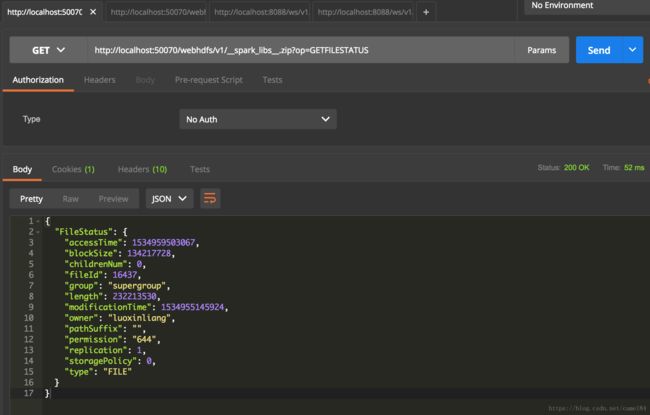
查看jar包的属性
http://localhost:50070/webhdfs/v1/spark-examples_2.11-2.3.1.jar?op=GETFILESTATUS
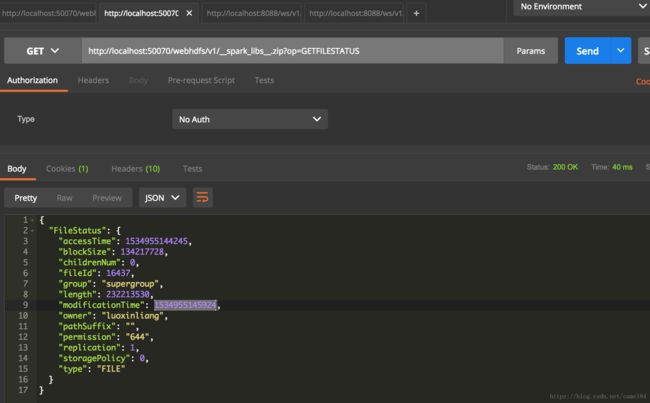
查看spark库zip文件属性
http://localhost:50070/webhdfs/v1/__spark_libs__.zip?op=GETFILESTATUS
提交spark任务
http://localhost:8088/ws/v1/cluster/apps
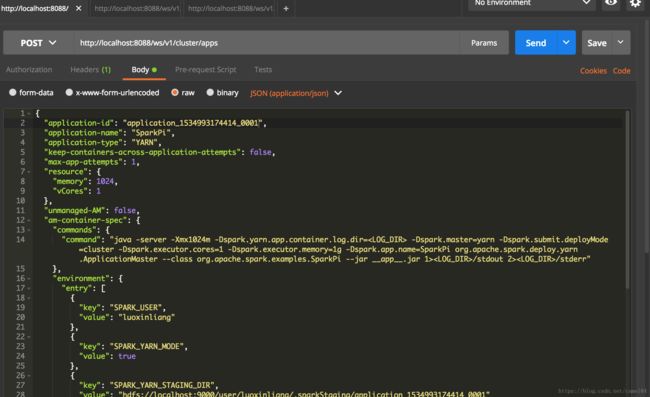
这里的__app__.jar和__spark_libs__的相关参数,就是使用上面的通过hdfs API获得的两个文件的属性。
{
"application-id": "application_1534993174414_0001",
"application-name": "SparkPi",
"application-type": "YARN",
"keep-containers-across-application-attempts": false,
"max-app-attempts": 1,
"resource": {
"memory": 1024,
"vCores": 1
},
"unmanaged-AM": false,
"am-container-spec": {
"commands": {
"command": "java -server -Xmx1024m -Dspark.yarn.app.container.log.dir= -Dspark.master=yarn -Dspark.submit.deployMode=cluster -Dspark.executor.cores=1 -Dspark.executor.memory=1g -Dspark.app.name=SparkPi org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.examples.SparkPi --jar __app__.jar 1>/stdout 2>/stderr"
},
"environment": {
"entry": [
{
"key": "SPARK_USER",
"value": "luoxinliang"
},
{
"key": "SPARK_YARN_MODE",
"value": true
},
{
"key": "SPARK_YARN_STAGING_DIR",
"value": "hdfs://localhost:9000/user/luoxinliang/.sparkStaging/application_1534993174414_0001"
},
{
"key": "CLASSPATH",
"value": "{{PWD}}{{PWD}}/__app__.jar{{PWD}}/__spark_libs__/*$HADOOP_CONF_DIR$HADOOP_COMMON_HOME/share/hadoop/common/*$HADOOP_COMMON_HOME/share/hadoop/common/lib/*$HADOOP_HDFS_HOME/share/hadoop/hdfs/*$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*$HADOOP_YARN_HOME/share/hadoop/yarn/*$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*{{PWD}}/__spark_conf__/__hadoop_conf__"
},
{
"key": "SPARK_DIST_CLASSPATH",
"value": "{{PWD}}{{PWD}}/__app__.jar{{PWD}}/__spark_libs__/*$HADOOP_CONF_DIR$HADOOP_COMMON_HOME/share/hadoop/common/*$HADOOP_COMMON_HOME/share/hadoop/common/lib/*$HADOOP_HDFS_HOME/share/hadoop/hdfs/*$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*$HADOOP_YARN_HOME/share/hadoop/yarn/*$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*{{PWD}}/__spark_conf__/__hadoop_conf__"
}
]
},
"local-resources": {
"entry": [
{
"key": "__app__.jar",
"value": {
"resource": "hdfs://localhost:9000/spark-examples_2.11-2.3.1.jar",
"size": 1997556,
"timestamp": 1534953699017,
"type": "FILE",
"visibility": "APPLICATION"
}
},
{
"key": "__spark_libs__",
"value": {
"resource": "hdfs://localhost:9000/__spark_libs__.zip",
"size": 232213530,
"timestamp": 1534955145924,
"type": "ARCHIVE",
"visibility": "APPLICATION"
}
}
]
}
}
}上面的传入参数会容易理解,但是收集这些参数很麻烦。值得注意的一个地方是command这个参数,使用的是java运行spark的一个类org.apache.spark.deploy.yarn.ApplicationMaster,而不是我们熟悉的spark-submit命令。笔者也尝试的使用spark-submit来作为command,结果是提交了两个任务,一个是通过yarn api提交的伤,另一个是spark-submit命令提交的任务。前者状态显示失败,而后一个是成功。原因是ApplicationMaster在执行后,会返回一个ExitCode=0。当把java运行ApplicationMaster改成spark-submit是不会有返回ExitCode。
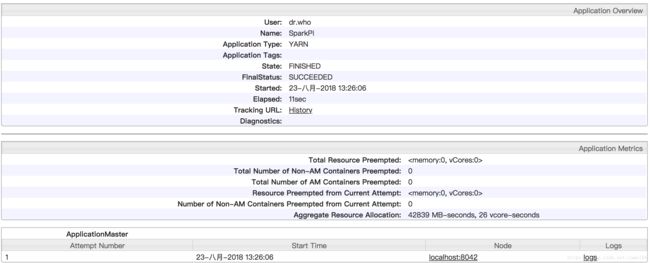

有兴趣的读者还可以尝试一下spark-shell –master yarn,看看它启动时的yarn日志。
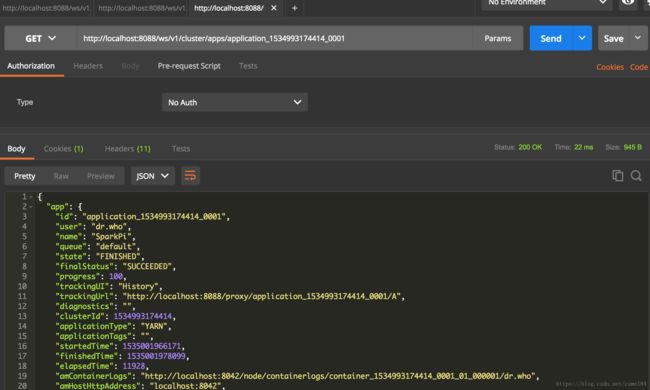
查询spark任务
http://localhost:8088/ws/v1/cluster/apps/application_1534993174414_0001
总结
通过yarn api提交spark任务并不难,但是需要准备的参数以及包是很麻烦的。此篇只是通过另一个角度帮助读者熟悉yarn的工作原理。在项目开发时还是建议使用livy来远程提交spark任务。livy不仅可以提交spark jar包,还可以提交spark代码片断,功能上更加丰富。