学界 | 量化深度强化学习算法的泛化能力

来源:AI 科技评论
OpenAI 近期发布了一个新的训练环境 CoinRun,它提供了一个度量智能体将其学习经验活学活用到新情况的能力指标,而且还可以解决一项长期存在于强化学习中的疑难问题——即使是广受赞誉的强化算法在训练过程中也总是没有运用监督学习的技术,例如 Dropout 和 Batch Normalization。但是在 CoinRun 的泛化机制中,OpenAI 的研究人员们发现这些方法其实有用,并且他们更早开发的强化学习会对特定的 MDP 过拟合。 CoinRun 在复杂性方面取得了令人满意的平衡:这个环境比传统平台游戏如《刺猬索尼克》要简单得多,但它仍是对现有算法的泛化性的有难度的挑战。
泛化挑战
任务间的泛化一直是当前深度强化学习(RL)算法的难点。虽然智能体经过训练后可以解决复杂的任务,但他们很难将习得经验转移到新的环境中。即使人们知道强化学习智能体倾向于过拟合——也就是说,不是学习通用技能,而更依赖于他们环境的细节——强化学习智能体始终是通过评估他们所训练的环境来进行基准测试。这就好比,在监督学习中对你的训练集进行测试一样!
之前的强化学习研究中已经使用了 Sonic 游戏基准、程序生成的网格世界迷宫,以及通用化设计的电子游戏 AI 框架来解决这个问题。在所有情况下,泛化都是通过在不同级别集合上的训练和测试智能体来进行度量的。在 OpenAI 的测试中,在 Sonic 游戏基准中受过训练的智能体在训练关卡上表现出色,但是如果不经过精细调节(fine-tuning)的话,在测试关卡中仍然会表现不佳。在类似的过拟合显示中,在程序生成的迷宫中训练的智能体学会了记忆大量的训练关卡,而 GVG-AI 智能体在训练期间未见过的难度设置下表现不佳。
游戏规则
CoinRun 是为现有算法而设计的一个有希望被解决的场景,它模仿了 Sonic 等平台游戏的风格。CoinRun 的关卡是程序生成的,使智能体可以访问大量且易于量化的训练数据。每个 CoinRun 关卡的目标很简单:越过几个或静止或非静止的障碍物,并收集到位于关卡末尾的一枚硬币。 如果碰撞到障碍物,智能体就会立即死亡。环境中唯一的奖励是通过收集硬币获得的,而这个奖励是一个固定的正常数。 当智能体死亡、硬币被收集或经过1000个时间步骤后,等级终止。

每个关卡的 CoinRun 设置难度从 1 到 3 .上面显示了两种不同的关卡:难度-1(左)和难度-3(右)
评估泛化
OpenAI 训练了 9 个智能体来玩 CoinRun,每个智能体都有不同数量的可用训练关卡。其中 8 个智能体的训练关卡数目从 100 到 16000 不等,最后一个智能体的关卡数目不受限制,因此它也永远不会经历相同的训练关卡。OpenAI 使用一个常见的 3 层卷积网络架构(他们称之为Nature-CNN),在其上训练智能体的策略。他们使用近端策略优化(PPO)对智能体进行了训练,总共完成了 256M 的时间步骤。由于每轮训练平均持续 100 个时间步骤,具有固定训练集的智能体将会看到每个相同的训练级别数千到数百万次。而最后那一个不受限制的智能体,经过不受限制的集合训练,则会看到约 200 万个不同的关卡,每个关卡一次。
OpenAI 收集了数据并绘制出了下面的图,每个点表示智能体在 10000 轮训练中的表现的平均值。在测试时使用智能体进行从未见过的关卡。他们发现,当训练关卡数目低于 4000 时,就会出现严重的过拟合。事实上,即使有 16000 个关卡的训练,仍会出现过拟合现象!不出所料,接受了不受限水平训练的智能体表现最好,因为它可以访问最多的数据。这些智能体用下图中的虚线表示。
他们将 Nature-CNN 基线与 IMPALA 中使用的卷积网络进行了比较,发现 IMPALA- cnn 智能体在任何训练集下的泛化效果都要好得多,如下所示。
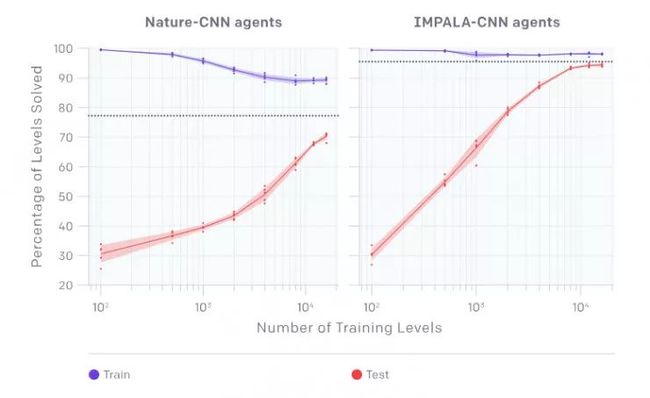
(左)最终训练和测试cnn - nature agent的性能,经过256M的时间步长,横轴是训练关卡数目。
(右)最终训练并测试IMPALA-CNN agent的性能,经过256M的时间步长,横轴是训练关卡数目
提高泛化性能
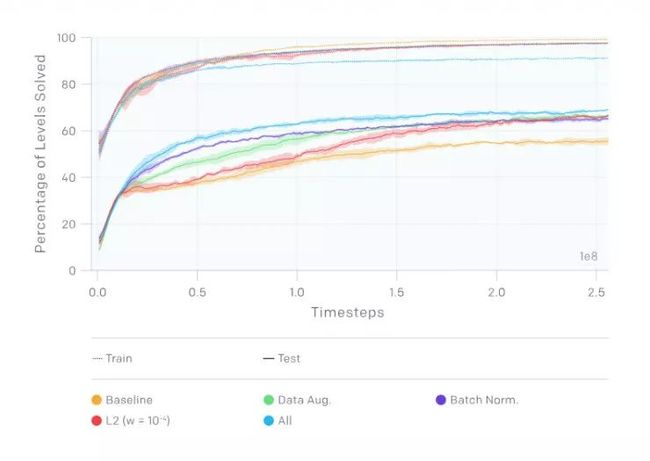
在接下来的实验中,OpenAI 使用了 500 个CoinRun级别的固定训练集。OpenAI 的基准智能体在如此少的关卡数目上泛化,这使它成为一个理想的基准训练集。他们鼓励其他人通过在相同的 500 个关卡上进行训练来评估他们自己的方法,直接比较测试时的性能。 利用该训练集,他们研究了几种正则化技术的影响:
dropout (当一个复杂的前馈神经网络在小的数据集上训练时容易造成过拟合。为了防止这种情况的发生,可以通过在不同的时候让不同的特征检测器不参与训练的做法来提高神经网络的性能)和 L2 批量正则化(就是在深度神经网络训练过程中,让每一层神经网络的输入都保持相同分布的批标准化):两者都带来了更好的泛化性能,而 L2 正则化的影响更大
数据增强和批量标准化:数据增强和批量标准化都显著改善了泛化。
环境随机性:与前面提到的任何一种技术相比,具有随机性的训练在更大程度上改善了泛化(详见论文 https://arxiv.org/abs/1812.02341)。
额外的环境
OpenAI 还开发了另外两个环境来研究过拟合:一个名为 CoinRun-Platforms 的 CoinRun 变体和一个名为 RandomMazes 的简单迷宫导航环境。 在这些实验中,他们使用了原始的 IMPALA-CNN 架构和 LSTM,因为他们需要足够的内存来保证在这些环境中良好地运行。
在 CoinRun-Platforms 中,智能体试图在 1000 步时限内收集几个硬币。硬币被随机地分散在关卡的不同平台上。在 CoinRun-Platforms 中,关卡更大、更固定,因此智能体必须更积极地探索,偶尔还要回溯其步骤。
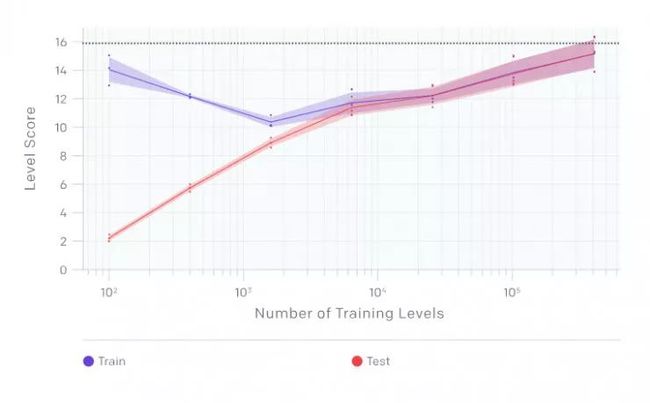
在 CoinRun-Platforms 上经过 20 亿个时间步骤后的最终训练和测试性能,横轴是训练关卡数目
当他们在基线智能体实验中测试运行 CoinRun-Platforms 和 RandomMazes 时,智能体在所有情况下都非常严重过拟合。在 RandomMazes 中,他们观察到特别强的过拟合,因为即使使用 20,000 个训练关卡是,仍然与无限关卡的智能体存在相当大的泛化差距。
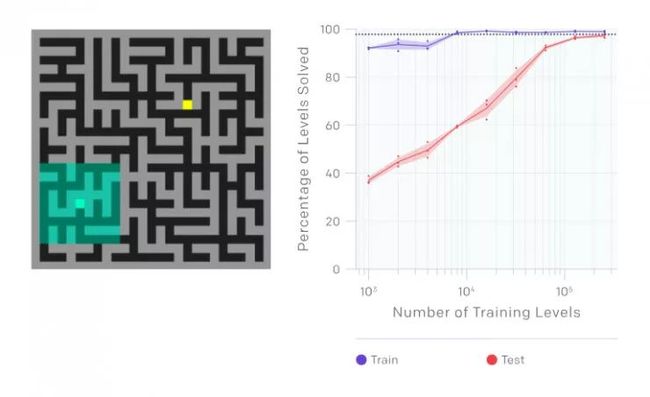
RandomMazes中的一个级别,显示智能体的观察空间(左)。横轴是训练关卡数目
下一步
OpenAI 的结果再次揭示了强化学习中潜在的问题。使用程序生成的 CoinRun 环境可以精确地量化这种过拟合。有了这个度量,研究人员们可以更好地评估关键的体系结构和算法决策。他相信,从这个环境中吸取的经验教训将适用于更复杂的环境,他们希望使用这个基准,以及其他类似的基准,向具有通用泛化能力的智能体迭代前进。
对于未来的研究,OpenAI 建议如下:
研究环境复杂性与良好泛化所需的关卡数量之间的关系
调查不同的循环体系结构是否更适合在这些环境中进行泛化
探索有效结合不同正则化方法的方法
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
