并行:四种C+OpenMP计算π的并行程序
四种C+OpenMP计算π的并行程序
- VS2017中OpenMP配置
- 计算π的串行程序
- 计算π的并行程序
- 1.并行域并行化
- 2.共享任务结构并行化
- 3.private字句和critical制导语句并行化
- 4.并行规约并行化
- 四种并行程序整合在一个project里
最近并行计算课要做一份实验报告,挺有意思的,特写篇博客记录一下。
VS2017中OpenMP配置
参考之前的博客:https://blog.csdn.net/chao_ji_cai/article/details/89431622
计算π的串行程序
/* serial code */
static long num_steps = 100000;
double step;
void main()
{
int i;
double x, pi, sum = 0.0;
step = 1.0/(double)num_steps;
for(i=0; i<=num_steps; i++)
{
x = (i-0.5)*step;
sum = sum+4.0/(1.0+x*x);
}
pi = step*sum;
}
计算π的并行程序
1.并行域并行化
#include "pch.h"
#include <stdio.h>
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel private(i) //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
for (i=id, sum[id]=0.0;i< num_steps; i=i+NUM_THREADS){
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i=0, pi=0.0;i<NUM_THREADS;i++) pi += sum[i] * step;
printf("pi is approximately:%.16lf\n",pi);
}
2.共享任务结构并行化
#include "pch.h"
#include <stdio.h>
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main ()
{
int i;
double x, pi, sum[NUM_THREADS];
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel //并行域开始,每个线程(0和1)都会执行该代码
{
double x;
int id;
id = omp_get_thread_num();
sum[id]=0;
#pragma omp for //未指定chunk,迭代平均分配给各线程(0和1),连续划分
for (i=0;i< num_steps; i++){
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i=0, pi=0.0;i<NUM_THREADS;i++) pi += sum[i] * step;
printf("pi is approximately:%.16lf\n",pi);
}//共2个线程参加计算,其中线程0进行迭代步0~49999,线程1进行迭代步50000~99999.
3.private字句和critical制导语句并行化
#include "pch.h"
#include <stdio.h>
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main ()
{
int i;
double pi=0.0;
double sum=0.0;
double x=0.0;
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel private(x,sum,id) //该子句表示x,sum变量对于每个线程是私有的(!!!注意id要设为私有变量)
{
int id;
id = omp_get_thread_num();
for (i=id, sum=0.0;i< num_steps; i=i+NUM_THREADS){
x = (i+0.5)*step;
sum += 4.0/(1.0+x*x);
}
#pragma omp critical //指定代码段在同一时刻只能由一个线程进行执行
pi += sum*step;
}
printf("pi is approximately:%.16lf\n",pi);
} //共2个线程参加计算,其中线程0进行迭代步0,2,4,...线程1进行迭代步1,3,5,....当被指定为critical的代码段 正在被0线程执行时,1线程的执行也到达该代码段,则它将被阻塞知道0线程退出临界区。
}
4.并行规约并行化
#include "pch.h"
#include <stdio.h>
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main ()
{
int i;
double pi=0.0;
double sum=0.0;
double x=0.0;
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); //设置2线程
#pragma omp parallel for reduction(+:sum) private(x) //每个线程保留一份私有拷贝sum,x为线程私有,最后对线程中所以sum进行+规约,并更新sum的全局值
for(i=1;i<= num_steps; i++){
x = (i-0.5)*step;
sum += 4.0/(1.0+x*x);
}
pi = sum * step;
printf("pi is approximately:%.16lf\n",pi);
} //共2个线程参加计算,其中线程0进行迭代步0~49999,线程1进行迭代步50000~99999.
四种并行程序整合在一个project里
有些重名变量需要重命名
#include "pch.h"
#include <iostream>
#include <stdio.h>
#include <omp.h>
static long num_steps = 100000;
double step;
#define NUM_THREADS 2
int main()
{
int i;
double pi = 0.0;
double sum = 0.0;
double x = 0.0;
step = 1.0 / (double)num_steps;
omp_set_num_threads(NUM_THREADS);
//1.--------------------------------------------------------->并行规约 reduction
#pragma omp parallel for reduction(+:sum) private(x)
for (i = 1; i <= num_steps; i++) {
x = (i - 0.5)*step;
sum += 4.0 / (1.0 + x * x);
}
pi = sum * step;
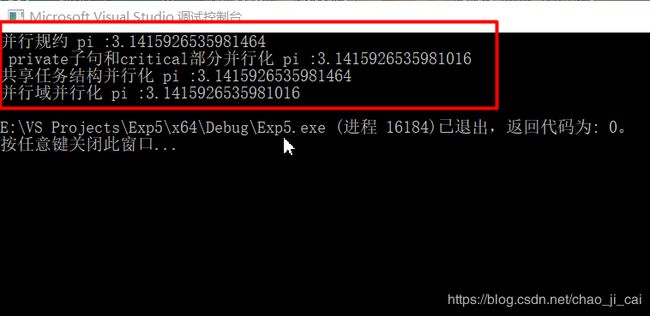
printf("并行规约 pi :%.16lf\n ", pi);
//2.--------------------------------------------->private子句和critical部分并行化
double pi1 = 0.0;
int id;
#pragma omp parallel private(x,sum,id) //注意id要设为私有变量
{
id = omp_get_thread_num();
for (i = id, sum = 0.0; i < num_steps; i = i + NUM_THREADS) {
x = (i + 0.5)*step;
sum += 4.0 / (1.0 + x * x);
}
#pragma omp critical //指定代码段在同一时刻只能由一个线程进行执行
pi1 += sum * step;
}
printf("private子句和critical部分并行化 pi :%.16lf\n", pi1);
//3.---------------------------------------------------------->共享任务结构并行化
double pi2 = 0.0;
double sum1[NUM_THREADS];
# pragma omp parallel private(i,x) shared(sum)
{
int id = omp_get_thread_num();
sum1[id] = 0;
# pragma omp for
for (i = 0; i < num_steps; i++)
{
x = (i + 0.5)*step;
sum1[id] += 4.0 / (1.0 + x * x);
}
}
for (i = 0, pi = 0; i < NUM_THREADS; i++)
pi2 += sum1[i] * step;
printf("共享任务结构并行化 pi :%.16lf\n", pi2);
//4.--------------------------------------------------------------->并行域并行化
double pi3 = 0.0;
double sum2[NUM_THREADS];
#pragma omp parallel private(i)
{
double x;
int id;
id = omp_get_thread_num();
for (i = id, sum2[id] = 0.0; i < num_steps; i = i + NUM_THREADS) {
x = (i + 0.5)*step;
sum2[id] += 4.0 / (1.0 + x * x);
}
}
for (i = 0, pi3 = 0.0; i < NUM_THREADS; i++) pi3 += sum2[i] * step;
printf("并行域并行化 pi :%.16lf\n", pi3);
}
运行结果:
四种并行程序参考博客:https://blog.csdn.net/rectsuly/article/details/69788860